本章描述 Google 管理流量的方法,涵蓋 負載平衡(Load Balancing)、自動擴展(Autoscaling) 和 負載卸除(Load Shedding) 三大策略,以及它們如何協同運作以保持服務的可靠性。核心觀點是:沒有單一方案能解決所有負載問題,而是需要多種工具、技術和策略的組合。
Google Cloud Load Balancing(GCLB)#
大多數公司如今不再自行開發全球負載平衡方案,而是使用公有雲供應商的負載平衡服務。GCLB 是 Google 對外提供的全球負載平衡解決方案,源自其內部開發的全球負載平衡系統。
在閱讀本章前,建議先參考第一本 SRE 書中的 Chapter 19(前端負載平衡)和 Chapter 20(資料中心內負載平衡)。
Anycast#
Anycast 是一種網路定址和路由方法,它將封包從單一發送者路由到一組接收者中拓撲上最近的節點,所有接收者共用同一個目的 IP 位址。
Google 透過 BGP(Border Gateway Protocol) 從網路的多個節點公告 IP,依賴 BGP 路由網格將封包送到最近的前端位置。這種方式消除了單播 IP 膨脹和尋找最近前端的問題。但仍存在兩個挑戰:
- 太多鄰近使用者可能壓垮一個前端站點
- BGP 路由重新計算可能重設連線
Stabilized Anycast(穩定化 Anycast)#
當 BGP 路由「震盪(flap)」時,進行中的 TCP 串流會因封包被導向沒有 TCP session 狀態的新前端而被重設。為解決此問題,Google 利用其自訂負載平衡器 Maglev 來穩定 anycast。
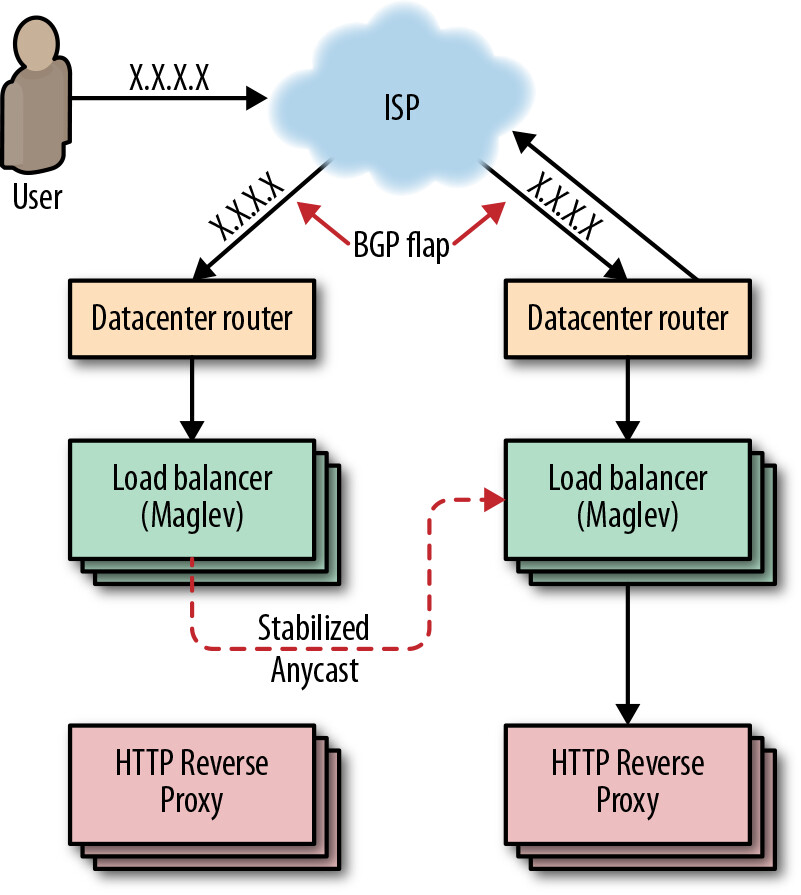
Figure 11.1: Stabilized anycast
Maglev 有能力將客戶端 IP 對映到最近的 Google 前端站點。當 Maglev 處理到一個 anycast VIP 封包,而該客戶端其實更靠近另一個前端站點時,Maglev 會將封包轉發到最近站點的 Maglev 機器進行交付。
Maglev#
Maglev 是 Google 自訂的分散式封包級負載平衡器,是雲端架構的核心元件。
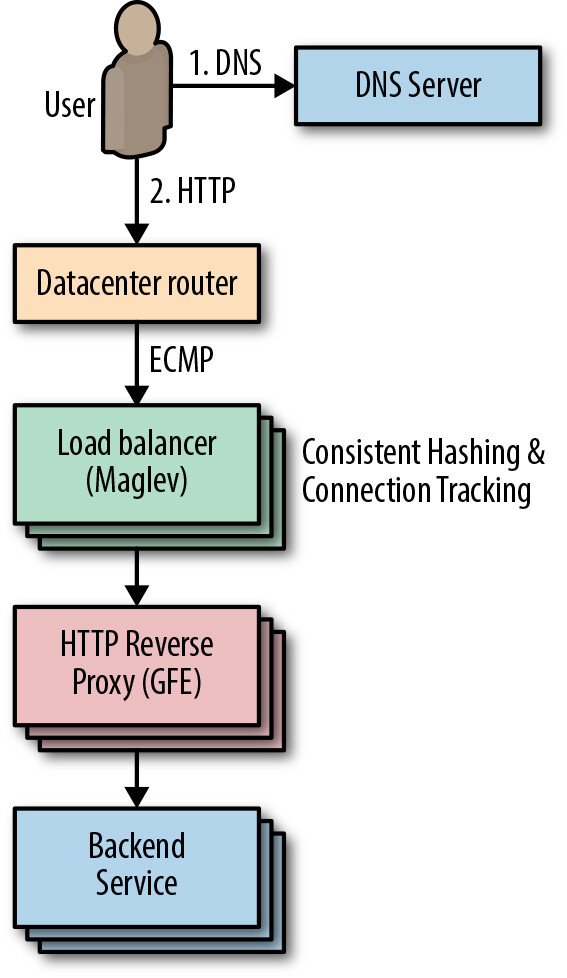
Figure 11.2: Maglev
Maglev 與傳統硬體負載平衡器的關鍵差異:
- 透過 ECMP(Equal-Cost Multi-Path) 轉發,封包可均勻分散到 Maglev 機器池中,只需增加伺服器即可提升容量
- 冗餘模型為 N+1(相較於傳統的 1+1 主動/被動架構),提升了可用性和可靠性
- 由 Google 端到端控制,能快速實驗和迭代
- 運行於資料中心的通用硬體上,大幅簡化部署
Maglev 的封包交付使用 一致性雜湊(consistent hashing) 和 連線追蹤(connection tracking)。當路由器收到一個目標為 Maglev 託管 VIP 的封包時,會透過 ECMP 轉發到叢集中任一 Maglev 機器。Maglev 計算封包的 5-tuple hash(來源位址、目的位址、來源埠、目的埠、傳輸協定),查詢連線追蹤表。若找到匹配且後端健康,則重用連線;否則使用一致性雜湊選擇後端。這種組合消除了在個別 Maglev 機器之間共享連線狀態的需求。
Global Software Load Balancer(GSLB)#
GSLB 是 Google 的全球軟體負載平衡器,允許在叢集之間平衡即時使用者流量,將使用者需求匹配到可用的服務容量。
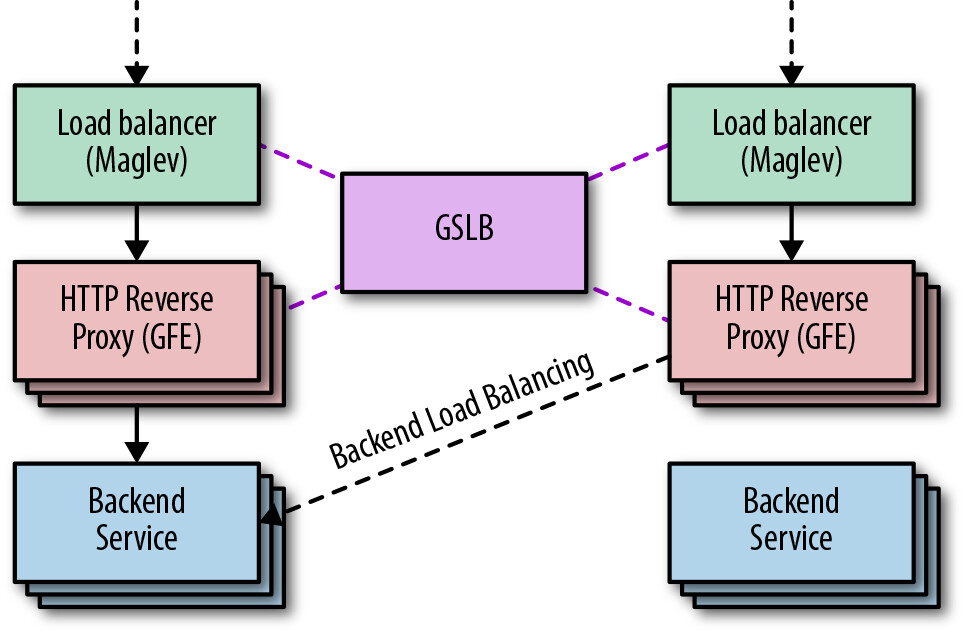
Figure 11.3: GSLB
GSLB 的功能:
- 控制連線到 GFE 的分配,以及請求到後端服務的分配
- 允許從不同叢集中的後端和 GFE 為使用者提供服務
- 理解後端服務的健康狀態,自動將流量從失敗的叢集排出
Google Front End(GFE)#
GFE 位於外部世界和各種 Google 服務之間,通常是客戶端 HTTP(S) 請求遇到的第一個 Google 伺服器。
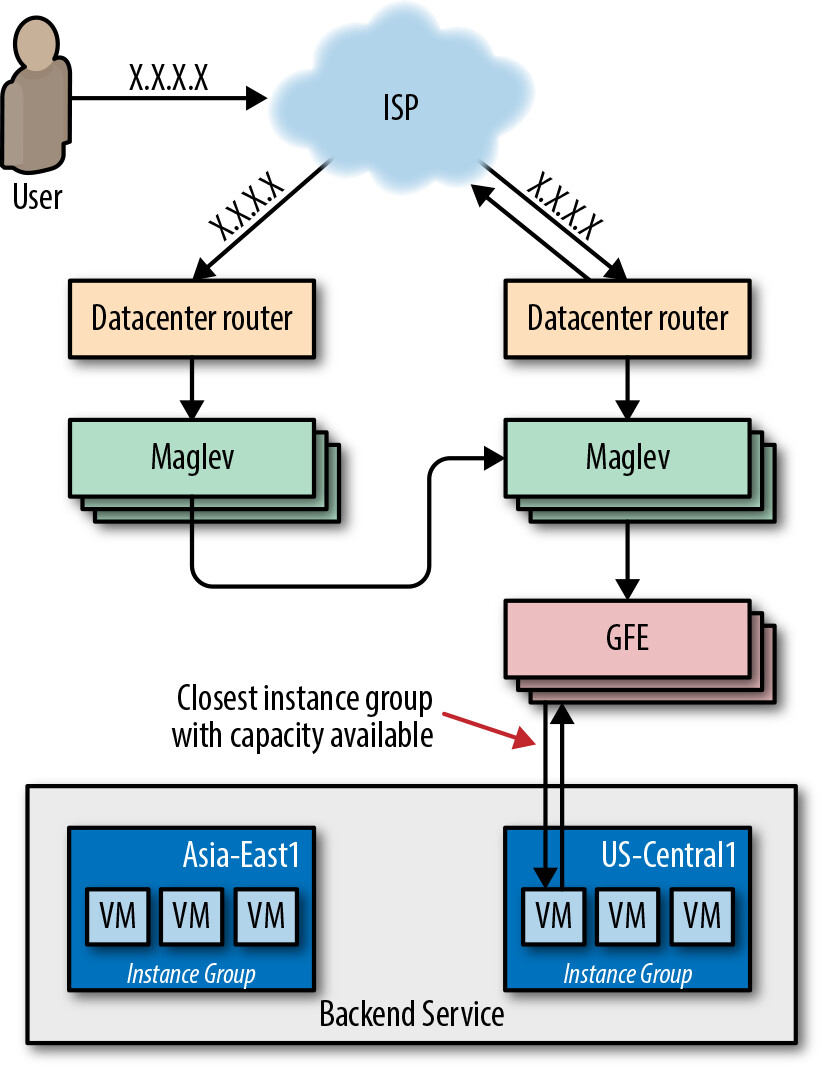
Figure 11.4: GFE
GFE 的職責:
- 終止客戶端的 TCP 和 SSL session,檢查 HTTP 標頭和 URL 路徑以決定路由
- 健康檢查後端:若後端回傳 NACK 或健康檢查逾時,GFE 停止發送流量
- 支援 lame duck 模式:後端在回應進行中請求的同時讓健康檢查失敗,實現優雅下線
- 維持持久連線:與所有最近活躍的後端保持 session,減少使用者延遲
GCLB 的低延遲策略#
Google 的網路佈建策略旨在降低對終端使用者的延遲。HTTPS 安全連線需要客戶端與伺服器之間兩次網路往返,因此特別重要的是:
- 在網路邊緣部署 Maglev 和 GFE,盡可能靠近使用者終止 SSL
- 透過長壽命加密連線將請求轉發到網路深處的後端服務
- GSLB 提供各層之間的黏合:讓 Maglev 找到最近的有容量 GFE,讓 GFE 路由請求到最近的有容量 VM 實例群組
GCLB 的高可用性#
- GCLB 提供 99.99% 的可用性 SLA
- 透過 金絲雀部署(canarying) 和 漸進式發布(gradual rollouts) 維持高可用
- 若新版本未通過健康檢查,負載平衡器會自動繞過它
- 可透過管理手段將實例群組從負載平衡器中移除,而不影響主要版本
案例研究 1:Pokemon GO 與 GCLB#
背景與挑戰#
Niantic 於 2016 年夏天推出 Pokemon GO。實際發布時的 RPS(Requests Per Second)是他們最樂觀流量估計的近 50 倍——遠超任何軟體堆疊的預期擴展範圍。更複雜的是,遊戲世界在所有玩家之間全球共享,需要近即時的狀態更新。
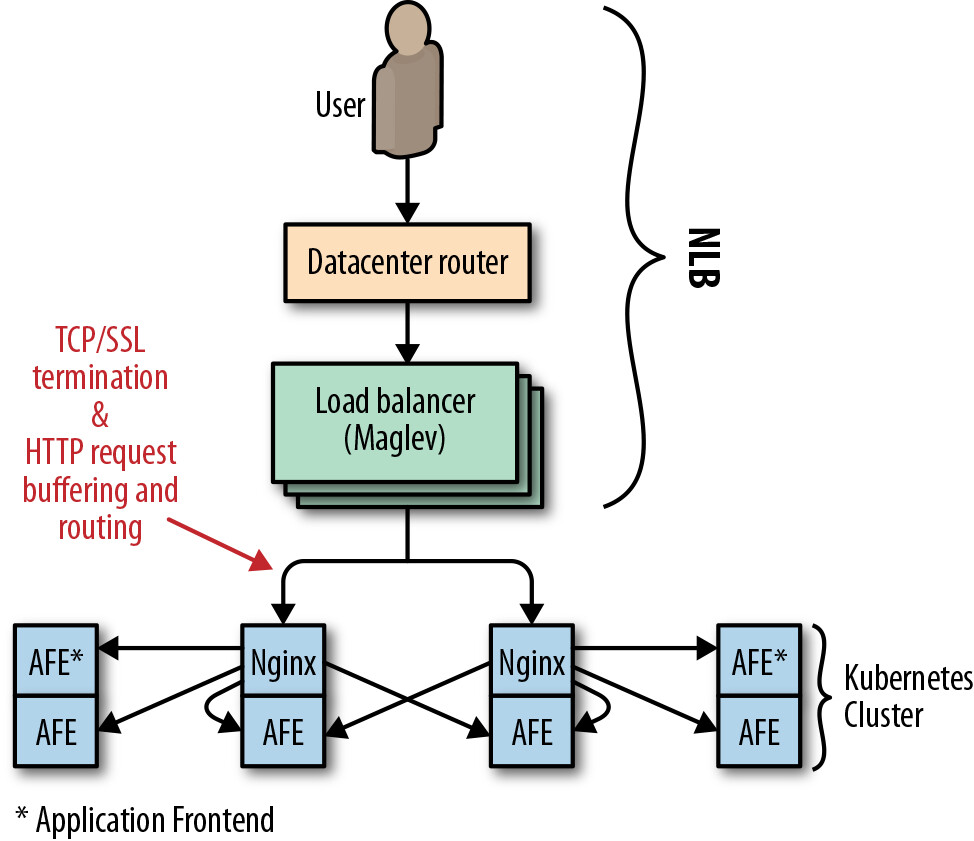
Figure 11.5: Pokemon GO (pre-GCLB)
發布時,Pokemon GO 使用 Google 的區域 Network Load Balancer(NLB) 來平衡流入 Kubernetes 叢集的流量。每個叢集包含 Nginx 實例 pod 作為 Layer 7 反向代理。這種架構存在以下問題:
- Nginx 後端負責為客戶端終止 SSL,需要兩次往返
- 緩衝 HTTP 請求導致代理層資源耗盡,特別是慢速客戶端
- 低層網路攻擊(如 SYN flood)無法被封包級代理有效緩解
遷移到 GCLB#
一次大規模 SYN flood 攻擊使遷移成為優先事項。遷移是 Niantic 與 Google CRE/SRE 團隊的聯合工作。然而,隨著流量達到高峰,出現了未預見的問題:
- 真實客戶端需求比先前觀察到的高 200%——Niantic 前端代理拒絕了大量連線,這些被拒連線未出現在監控中
- 眾多後端服務超出容量,導致經典的 級聯故障(cascading failure)
- 後端變得極度緩慢(而非拒絕請求),負載平衡器重試 GET 請求,加劇了系統負載
- GFE 的 SSL 客戶端程式碼在前所未有的壓力下出現嚴重效能回歸,GCLB 全球容量實際降低了 50%
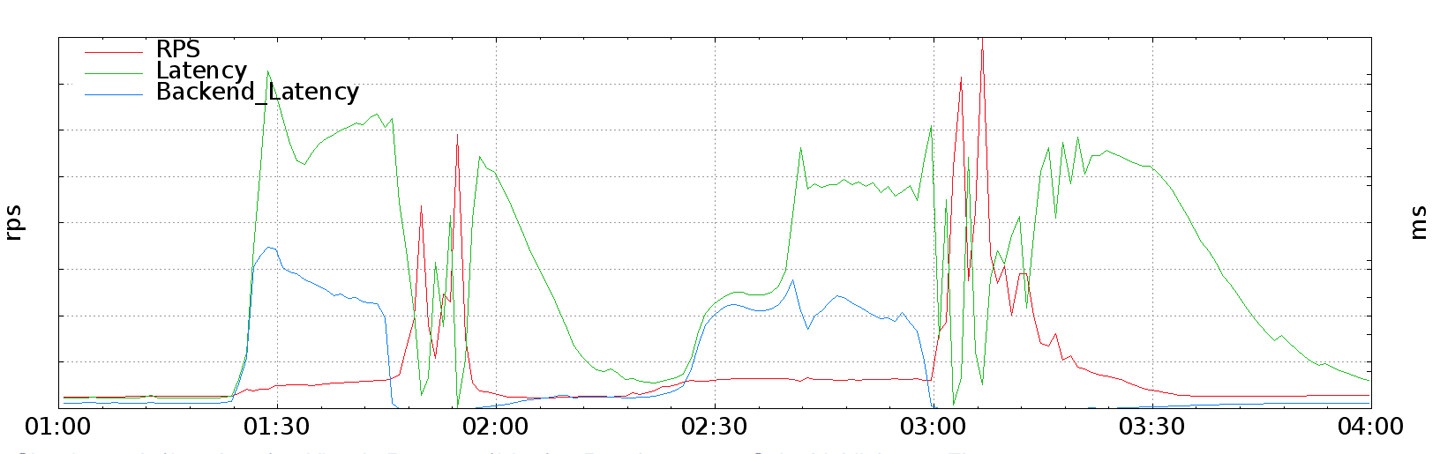
Figure 11.6: Traffic spikes caused by synchronous client retries
Pokemon GO 應用程式的重試策略(單次立即重試後固定退避)在大規模故障時導致了 雷群效應(thundering herd)——客戶端重試同步化,產生高達先前全球 RPS 峰值 20 倍的請求尖峰。
解決方案#
Google 的 Traffic SRE 值班人員採取以下步驟:
- 隔離:將可服務 Pokemon GO 流量的 GFE 從主要負載平衡器池中分離
- 擴展隔離池:直到能在效能回歸下處理尖峰流量
- 流量限速:在 Niantic 同意下,實施管理覆寫以限制負載平衡器代表 Pokemon GO 接受的流量速率
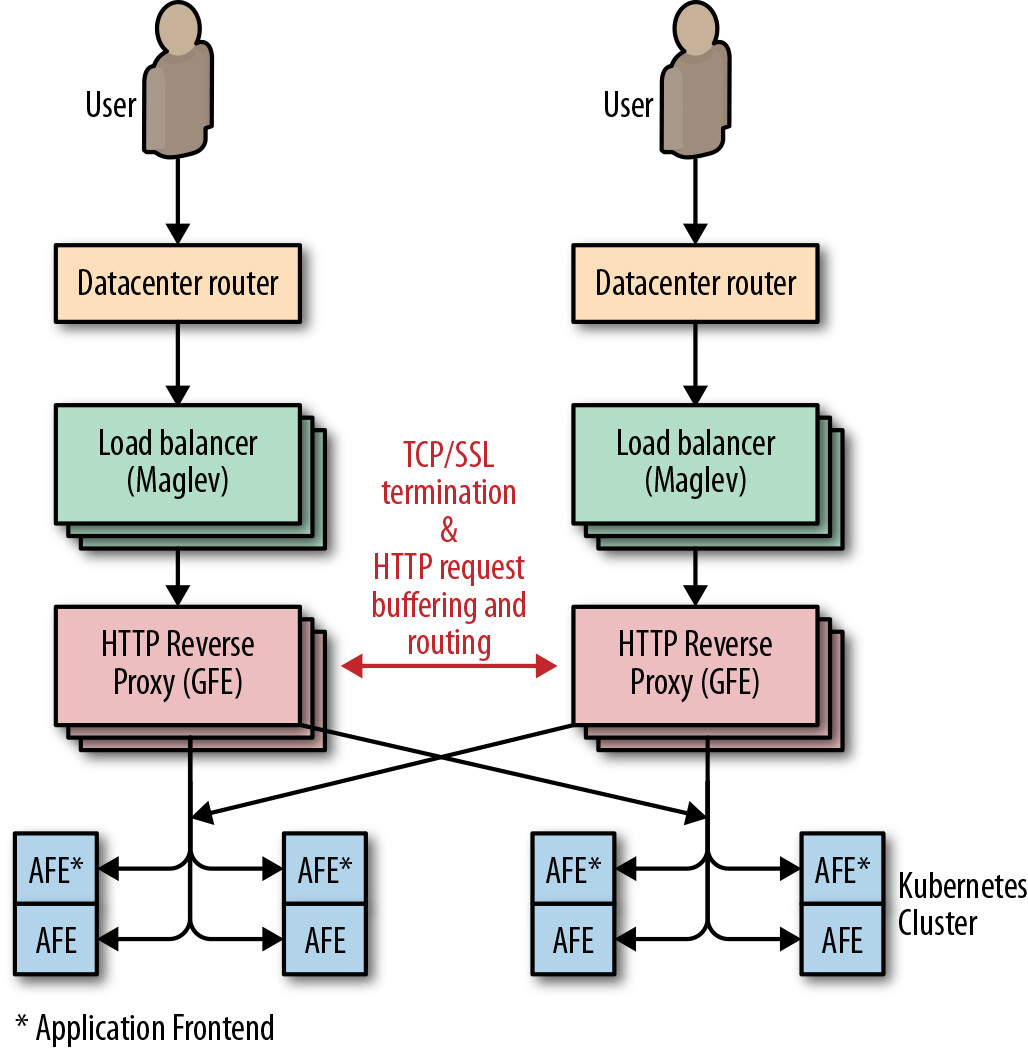
Figure 11.7: Pokemon GO GCLB
事後防護措施#
- Niantic 在客戶端引入了 抖動(jitter) 和 截斷指數退避(truncated exponential backoff),抑制同步重試尖峰
- Google 開始將 GFE 後端視為潛在的重大負載來源,建立了資格審查和負載測試實踐
- 雙方認識到應 盡可能靠近客戶端測量負載——若能準確預測客戶端 RPS 需求,就能預先擴展資源
自動擴展(Autoscaling)#
自動擴展可以是垂直的(增加每台機器的資源)或水平的(增加機器數量),是提升服務可用性和利用率的強大工具。但若配置不當或誤用,也可能對服務產生負面影響。
處理不健康的機器#
Autoscaling 通常將利用率平均到所有實例上,假設實例在請求處理效率上是同質的。當不健康的實例(如啟動中或殭屍實例)被計入平均值時,autoscaling 將不會觸發。改善策略:
- 基於負載平衡器的容量指標 autoscale,自動排除不健康實例
- 等待新實例穩定後再收集指標(GCE 稱此為 cool-down period)
- 結合 Autoscale 與 Autoheal:autohealer 監控實例健康狀態,自動重啟不健康的實例
有狀態系統的處理#
有狀態系統將同一使用者 session 的所有請求一致地送到同一後端。在這種情況下:
- 水平擴展(增加實例)不一定有幫助
- 智慧的任務級路由(例如使用一致性雜湊)是更好的策略
- 垂直擴展可搭配任務級平衡使用,吸收短期熱點
- 需謹慎使用,因為垂直擴展通常對所有實例統一應用,低流量實例可能不必要地變大
保守配置#
- 向上擴展比向下擴展更重要且風險更低——未能向上擴展可能導致過載和流量丟失
- 大多數 autoscaler 設計上對流量跳升比下降更敏感
- 建議將 autoscaler 配置為讓服務遠離關鍵系統瓶頸(如 CPU)
- 面向使用者的服務應保留足夠的備用容量用於過載保護和冗餘
設定約束#
Autoscaler 若配置錯誤可能失控。常見風險場景:
- 基於 CPU 使用率擴展,但新版本含有消耗 CPU 的 bug,導致 autoscaler 不斷擴展直到用盡所有配額
- 依賴項失敗導致所有請求卡住、消耗資源,autoscaler 持續擴展加劇問題
設定 autoscaler 的最小和最大邊界,確保有足夠配額擴展到設定的上限。這既能防止配額耗盡,也有助於容量規劃。
包含終止開關(Kill Switch)#
確保值班工程師了解如何停用 autoscaling 以及如何手動擴展。終止開關功能應 簡單、明顯、快速且有良好文件。
避免過載後端#
部署 autoscaler 前應執行 詳細的依賴分析:
- 確保後端服務有足夠的額外容量來服務增加的流量
- 確保後端在過載時能優雅降級
- 注意共享配額的微服務——若一個微服務擴展消耗了大部分配額,其他微服務將無法成長
避免流量不平衡#
某些 autoscaler(如 AWS EC2、GCP)可跨區域實例群組(RMiGs)平衡實例。額外的再平衡工作可:
- 避免單一區域過大
- 均勻化配額使用
- 提供更多的故障域多樣性
組合策略管理負載#
當系統足夠複雜時,可能需要同時使用多種負載管理策略:
- 負載平衡 + 自動擴展:多區域部署的服務,透過 autoscaling 隨負載擴展
- 負載平衡 + 負載卸除:當增加硬體需數週時,本地服務滿載後溢出到其他位置
- 自動擴展 + 負載卸除:Kubernetes 叢集中的資料處理管線,在記憶體不足時暫時卸除負載
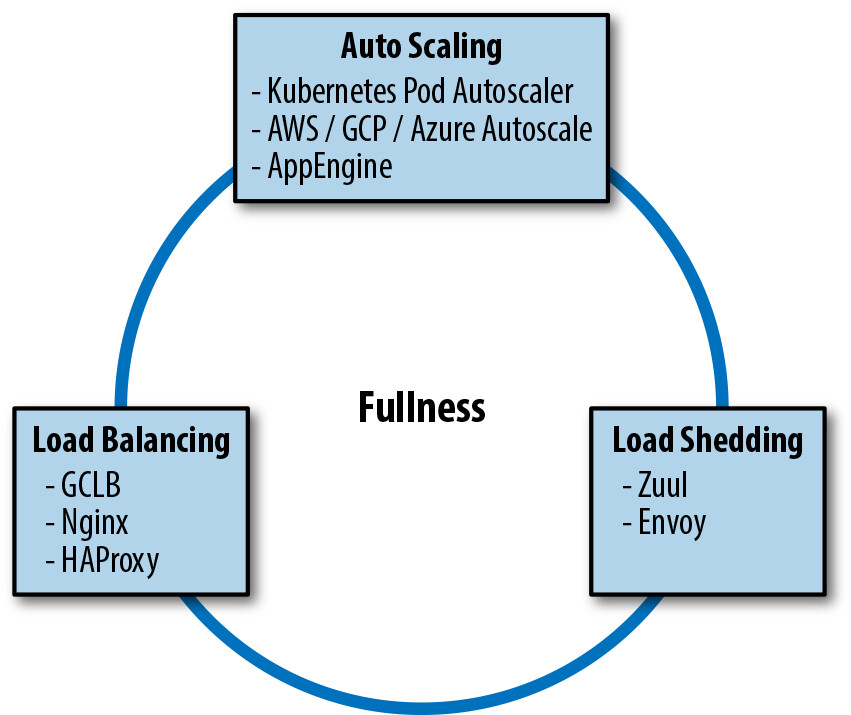
Figure 11.8: A full traffic management system
負載平衡、負載卸除和自動擴展雖然通常分別實施和配置,但它們並非完全獨立。當採用新的負載管理工具時,必須仔細檢查它與系統中已有工具的交互作用。
案例研究 2:當負載卸除反噬#
場景#
虛構公司 Dressy 在三個區域部署其線上服裝應用程式。客服團隊開始收到投訴——客戶無法存取應用程式。開發團隊發現負載平衡器將所有流量導向 region A,即使 A 已滿載而 B 和 C 完全空閒。
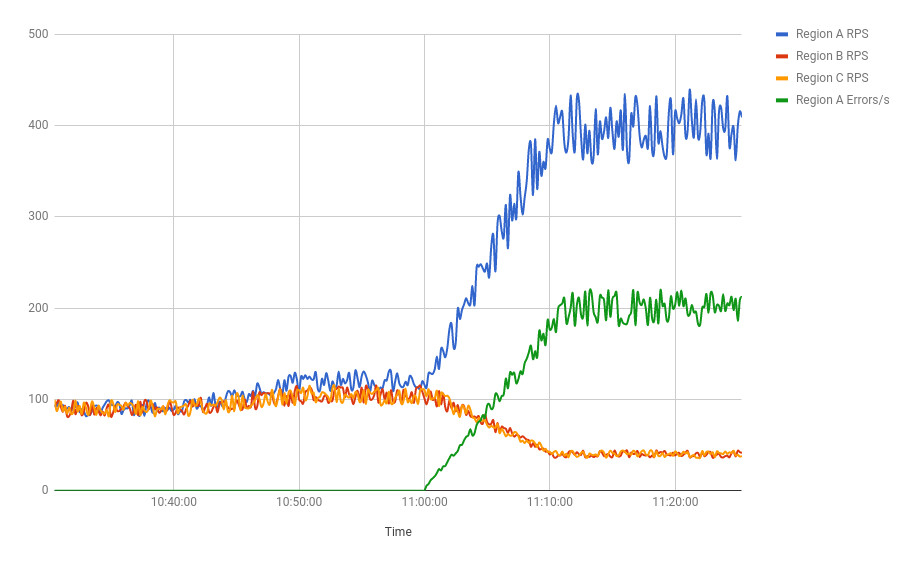
Figure 11.9: Regional traffic
事件時間線#
- 一天開始時,三個叢集穩定在 90 RPS
- 10:46,所有三個區域的流量開始上升
- 11:00,region A 略早到達 120 RPS
- 11:10,region A 成長到 400 RPS,而 B 和 C 降至 40 RPS
- 負載平衡器穩定在此狀態,大部分打到 region A 的請求回傳 503 錯誤
根因分析#
團隊在稍早啟用了 負載卸除——當 CPU 使用率達到閾值時,伺服器對新請求回傳錯誤而非嘗試處理。問題出在:
- Region A 略早達到閾值,開始拒絕 10%、20%、50% 的請求
- 拒絕請求時,CPU 使用率維持不變
- 負載平衡器基於 CPU 使用率估算滿載程度,認為每個被拒請求都代表 降低了每請求 CPU 成本
- 負載平衡器判定 region A「更高效」(以 80% CPU 服務 240 RPS,而 B 和 C 以同樣 CPU 只服務 120 RPS),於是持續將更多流量導向 A
根本問題#
負載卸除和負載平衡系統 沒有互相溝通。這兩個系統分別由不同工程師安裝和配置,沒有人將它們作為統一的負載管理系統來檢視。
經驗教訓#
要有效管理系統負載,必須在配置個別工具和管理其交互作用上都保持 刻意性(deliberate)。具體建議:
負載平衡方面:
- Autoscaling 可與負載平衡協同運作,在靠近使用者的位置擴展容量——但要小心 正向回饋迴路
- 若需求主要集中在一個位置,該位置會持續成長到所有容量集中於一處——若此位置故障,後果嚴重
- 透過設定每個位置的 最小實例數 來保留故障轉移的備用容量
負載卸除方面:
- 設定閾值使系統在負載卸除啟動 之前 先 autoscale
- 否則系統可能卸除本可在擴展後服務的流量
RPC 管理方面:
- 在 RPC 請求上設定 截止時間(deadline)——避免處理對使用者已無益的請求
- 伺服器應終止耗時過長的請求,客戶端應取消不再有用的請求
- 沒有明確 deadline 時,系統會為所有進行中的請求持有資源直到最大上限,導致延遲增加和資源耗盡風險
結論#
在 Google 的經驗中,不存在完美的流量管理配置。Autoscaling 是強大的工具,但容易出錯。如果負載平衡、負載卸除和自動擴展被孤立配置,可能產生災難性的回饋迴路。流量管理在基於系統間交互作用的全局視角時運作得最好。
再三證明的是,當所有系統同步失敗時,任何程度的負載卸除、自動擴展或節流都無法拯救服務。要讓服務優雅地故障,需要提前規劃——設定旗標、變更預設行為、啟用昂貴的日誌記錄,或公開流量管理系統用於決策的參數當前值。