本章探討如何在組織中建立健康的 事後檢討(Postmortem)文化,涵蓋撰寫高品質 postmortem 的原則、推動組織文化轉變的激勵措施,以及支持流程的工具與範本。
核心理念#
Google 的經驗表明,真正 無責備(blameless) 的 postmortem 文化能帶來更可靠的系統。在組織中導入 postmortem 既是技術變革,也是文化變革。關鍵要點如下:
- 不要在事件結束後期望系統會自行修復——應主動撰寫 postmortem 並跟進行動方案
- 可以從簡單的 postmortem 流程開始,再逐步調整以適應組織需求
- 當 postmortem 被妥善撰寫、確實執行並廣泛分享時,它能有效推動正向的組織變革並防止事故再發
案例研究:衛星機架除役事件#
本章以 Google 的一次真實事件作為貫穿全文的案例。故事背景如下:
- Google 除了在自有資料中心部署伺服器外,也在共同託管設施(colocation facilities)中部署稱為 衛星(satellites) 的代理/快取機架
- 衛星機架需定期維護與升級,其除役流程大部分已自動化
- 除役流程中包含 diskerase(磁碟清除)步驟,一旦執行就無法恢復資料
事件經過#
- 一個衛星機架被標記為除役,diskerase 步驟成功完成,但後續自動化流程失敗
- 工程師重新執行除役流程時,觸發了一個 輸入驗證 bug——API 將空列表視為「無篩選條件」而非「不操作任何機器」
- 結果:全球所有衛星機器的磁碟在數分鐘內被清除,導致使用者連線改由核心資料中心處理,延遲增加
- 由於良好的容量規劃,大多數使用者僅感受到輕微影響,團隊花了兩天時間重建機器
- 三年後發生類似事件時,第一次 postmortem 的行動方案大幅降低了影響範圍
差勁的 Postmortem 範例分析#
本章先展示一份「差勁」的 postmortem 範例,再逐一說明其問題所在:
缺乏上下文#
- 使用了 “satellites”、“diskerase” 等專業術語但未在 Background 或 Glossary 中解釋
- 缺少適當的背景資訊,使讀者難以理解甚至忽略 postmortem
關鍵細節遺漏#
- 問題摘要:僅提供問題持續時間,缺乏量化數據來評估影響規模
- 根因分析:僅簡短一段文字,未深入探討底層技術細節
- 復原過程:該區段完全空白,無法讓讀者了解實際發生了什麼
行動方案品質低落#
- 大多數行動方案僅是 緩解性質(mitigate),缺少預防性(prevent)和修復性(fix)措施
- 所有項目優先級一樣(都是 P2),無法判斷處理順序
- 使用模糊語言如「Make automation better」、「Improve paging and alerting」
- 僅一個項目有追蹤 bug 編號
具反效果的指責#
- 在「Things that went poorly」中指名責備團隊成員
- 在「Root causes and trigger」中將責任完全歸咎於個人(如「dylanfour@ completely ignored…」)
- 使用「careless ignorance」等帶有情緒色彩的語言
指名道姓的 postmortem 會讓團隊成員變得規避風險,害怕被公開羞辱,甚至可能為了自保而隱瞞關鍵事實。
其他問題#
- 動態語言:包含主觀判斷和情緒化描述(如「which is ridiculous」、「I can’t believe we survived this one!!!」)
- 缺乏所有權:列出四位 owner,但理想上應由單一聯絡人負責
- 受眾有限:僅分享給團隊成員,而非公司全體
- 延遲發布:事件發生四個月後才發布,期間若再發生類似事故則無從參考
優良的 Postmortem 範例分析#
本章接著展示同一事件的實際 postmortem(經脫敏處理),並說明其優秀之處。
清晰度#
- 完整的 詞彙表(Glossary) 解釋所有專業術語(如 GFE、MDB、IMAG、OMG、Satellites 等)
- 行動方案按五大主題分組:預防/風險教育、緊急回應、監控/告警、衛星佈建、清理/雜項
量化指標#
- 提供具體的影響數據:前端查詢丟失量、QPS、延遲增加毫秒數
- 記錄快取命中率變化(如某服務從 X% 降至 Y%)
- 附帶連結指向原始數據來源
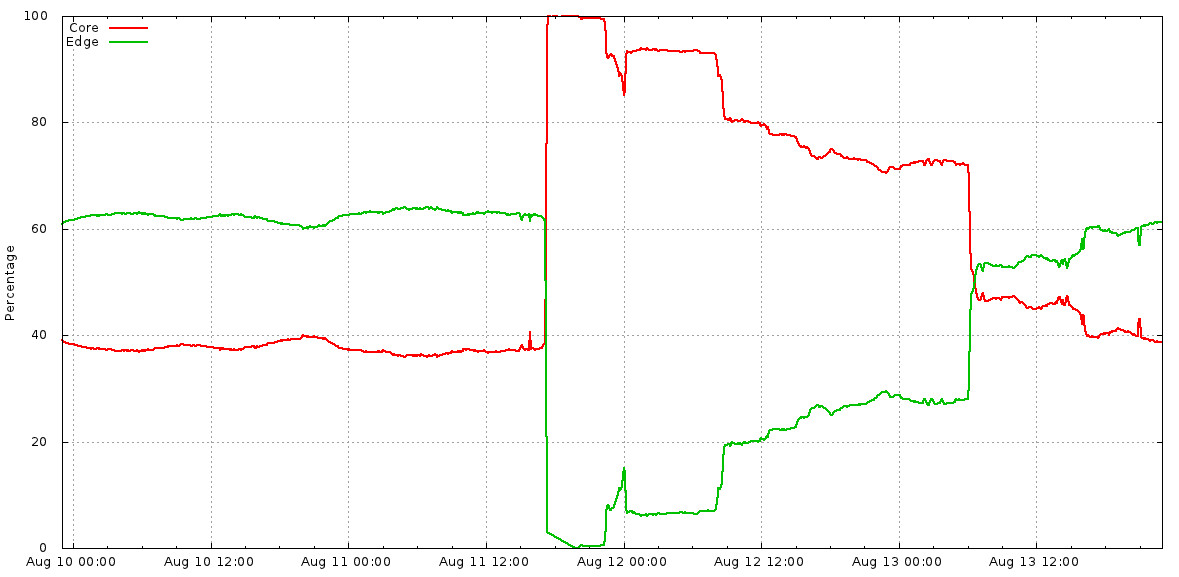
Figure 10.1: Core vs. Edge QPS breakdown
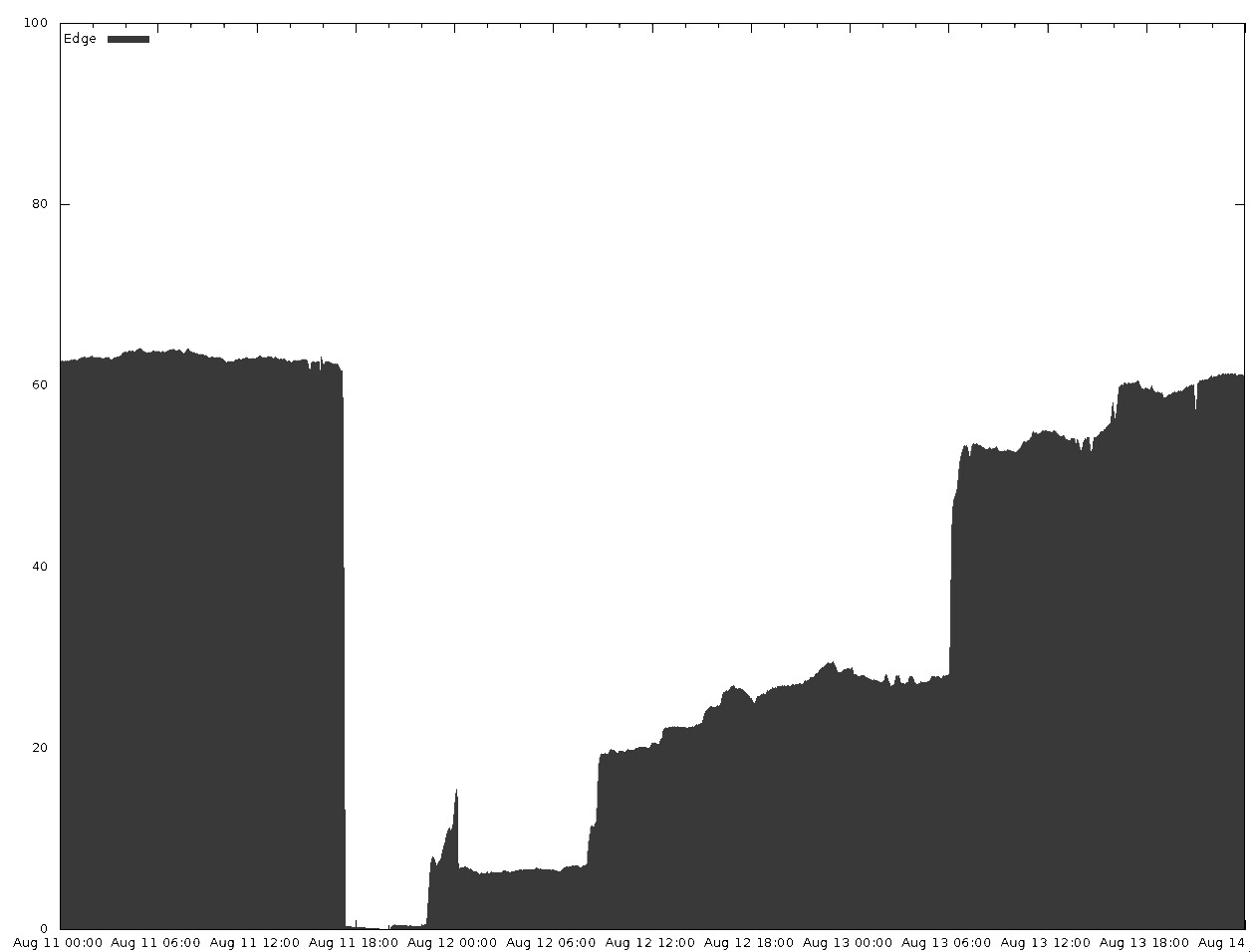
Figure 10.2: Core vs. Edge QPS breakdown (alternate representation)
具體的行動方案#
優質行動方案具備以下特性:
- 明確所有權:每個項目都有 owner 和追蹤 bug 編號
- 合理的優先級:區分 P0、P1、P2 級別
- 可衡量的結束狀態:例如「在超過 X% 機器被移走時新增告警」
- 預防性措施:例如「禁止單一操作影響跨越 namespace/class 邊界的伺服器」
無責備原則#
- 「Things that went poorly」聚焦於系統設計缺陷,而非個人錯誤
- 「Root cause and trigger」探討「什麼」出了問題,而非「誰」造成的
- 行動方案旨在改善系統而非改善人
深度與廣度#
- 影響分析涵蓋多個面向:使用者影響、營收影響、團隊影響
- 根因分析深入追蹤技術細節,從 API bug 到工作流引擎的「run once」語意
- 復原過程詳細記錄了各種問題(如 TFTP 在高延遲連結上的效能、Autoreplacer 的併發回歸等)
及時性與簡潔性#
- 事件結束後不到一週即發布
- 冗長的數據來源(如聊天記錄、系統日誌)經過摘要,完整版本透過連結提供
組織激勵措施#
示範並強制無責備行為#
- 使用無責備語言:避免引導性問題(如「為什麼你沒確保…」),改用建設性建議
- 納入所有事件參與者共同撰寫 postmortem,避免遺漏關鍵因素
- 建立審查流程:透過明確的審查與溝通計畫,防止責備性語言傳播
一個更具建設性的回應方式:不說「為什麼你沒讓大家完成訓練?」,而是說「也許團隊成員應在加入 on-call 輪值前完成訓練?或者我們可以提醒他們在遇到困難時快速升級。畢竟,升級不是罪——特別是當它能減少使用者的痛苦時!」
獎勵 Postmortem 成果#
- 獎勵行動方案的關閉:僅獎勵撰寫 postmortem 而不獎勵關閉行動方案,會導致未完成的 postmortem 堆積
- 獎勵正向的組織變革:將 postmortem 教訓的廣泛實施視為擴大影響力的機會
- 突顯可靠性改善:在報告、簡報和績效考核中強調因 postmortem 而帶來的進步
- 樹立 Postmortem 負責人為領導者:讓作者有機會向更廣泛的聽眾分享教訓
遊戲化(Gamification)#
Google 每年舉辦兩次 FixIt 週,關閉最多 postmortem 行動方案的 SRE 可獲得小獎勵和吹噓的權利。
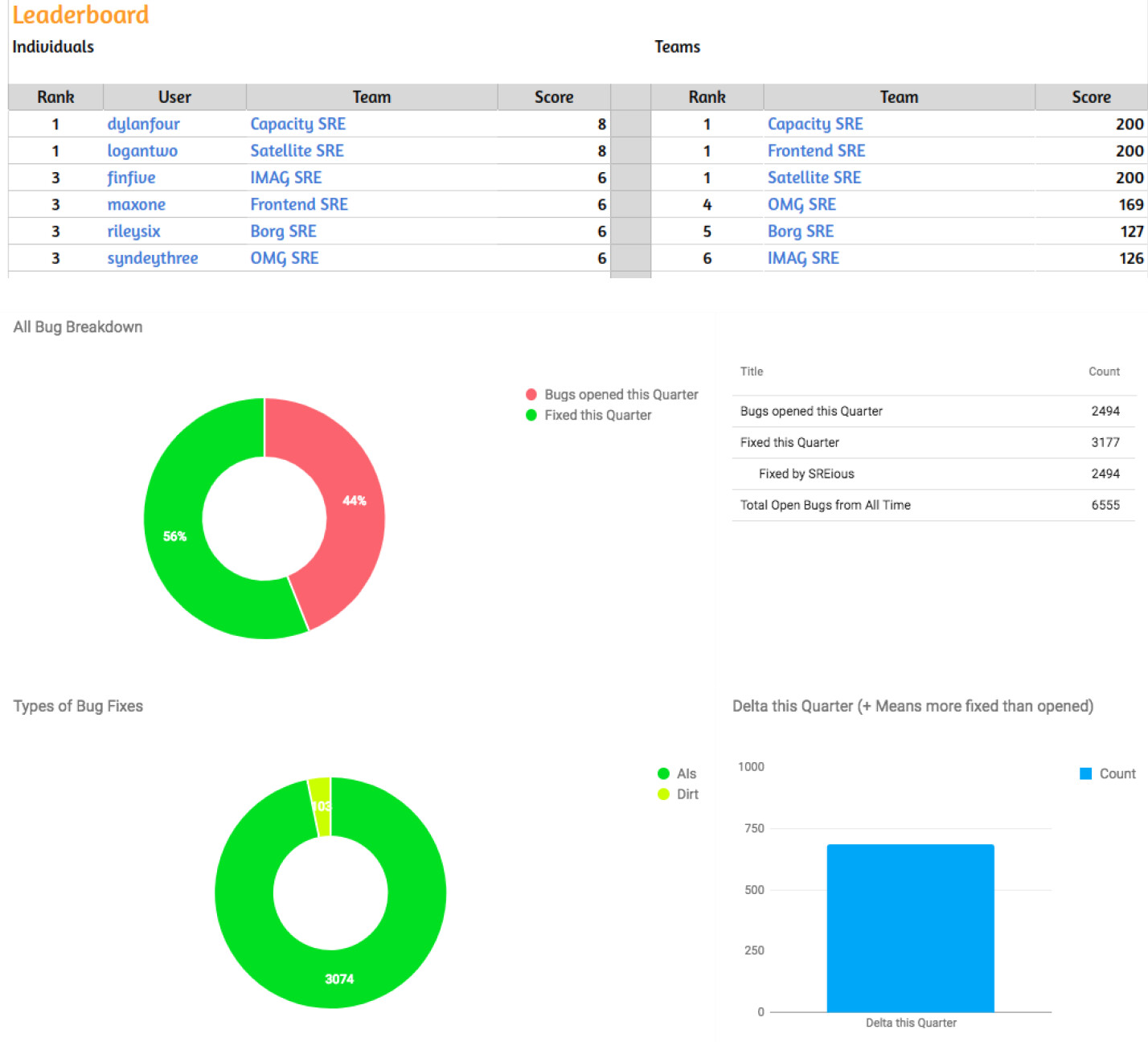
Figure 10.3: Postmortem leaderboard
廣泛分享 Postmortem#
- 透過內部溝通管道(email、Slack 等)宣布 postmortem 的發布
- 進行 跨團隊審查:一個團隊走過其事件過程,其他團隊提問並間接學習
- Google 多個辦公室有非正式的 Postmortem Reading Club,開放所有員工參加
- 使用 Wheel of Misfortune 訓練新工程師:由工程師重新演繹過去的 postmortem
- 建立每週事故報告並定期彙整「最佳精選」
回應 Postmortem 文化失敗#
常見的文化失敗模式與解決方案:
| 失敗模式 | 症狀 | 解決方案 |
|---|---|---|
| 逃避關聯 | 工程師不想與 postmortem 產生任何關聯 | 確保高能見度的 postmortem 經過無責備審查,分享正面案例 |
| 未能強化文化 | 高層主管使用責備性語言 | 溫和地將敘事導向更具建設性的方向 |
| 缺乏撰寫時間 | postmortem 品質低落,行動方案不完整 | 優先處理 postmortem 工作,追蹤完成與審查進度 |
| 事故重複發生 | 團隊經歷與過去相似的故障 | 深入調查——行動方案是否太慢關閉?功能速度是否凌駕可靠性修復? |
Postmortem 是你寫給未來團隊成員的信:保持一致的品質標準非常重要,以免意外地教導未來的隊友不良的經驗教訓。
工具與範本#
Postmortem 範本#
- 標準化格式讓 postmortem 更容易撰寫、分享和閱讀
- 可針對團隊需求自訂(例如:資料中心團隊的硬體型號、行動團隊的 Android 版本)
- Google 在 g.co/SiteReliabilityWorkbookMaterials ↗ 分享了其範本
- 其他業界範本來源包括:PagerDuty、GitHub 社群、Server Fault 等
Postmortem 工具#
Google 的內部工具支援以下流程:
- Postmortem 建立:事件管理工具自動將數據(Incident Commander、時間軸、IRC 日誌、受影響服務等)推送到 postmortem
- Postmortem 檢查清單:引導作者確保完整性,包含影響評估、根因分析深度、技術負責人審查、廣泛分享等步驟
- Postmortem 儲存:使用名為 Requiem 的工具儲存和搜尋,自 2009 年起已累積數千份 postmortem
- Postmortem 追蹤:行動方案作為 bug 追蹤,確保不會被遺漏
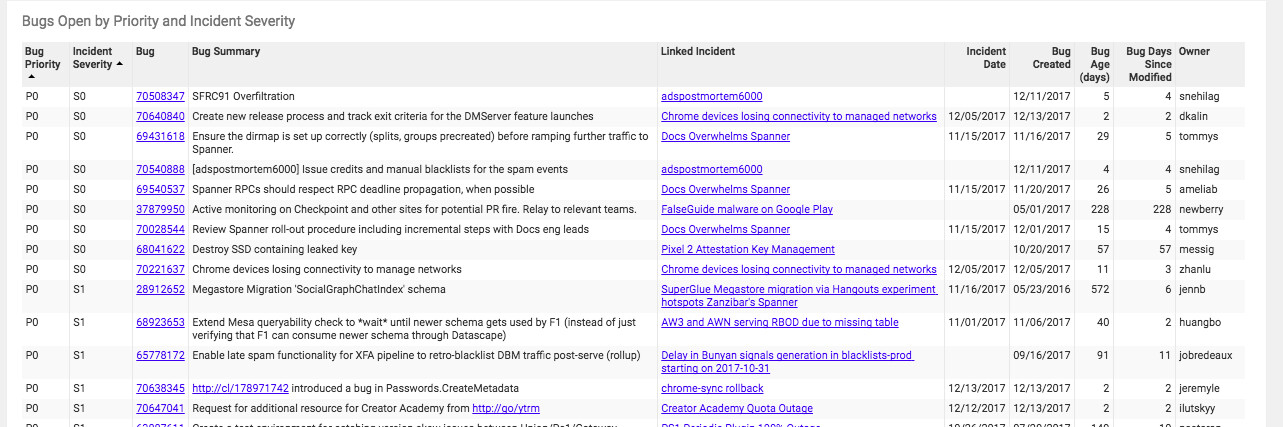
Figure 10.4: Postmortem action item monitoring
- Postmortem 分析:團隊可利用資料庫中的資料撰寫趨勢報告,找出最脆弱的系統,發現潛在的不穩定性來源
Figure 10.5: Postmortem analysis
雖然無法完全自動化撰寫 postmortem 的每個步驟,但範本和工具能讓流程更順暢,讓作者能專注於最關鍵的部分——根因分析和行動方案規劃。
結論#
持續投資培養 postmortem 文化,能帶來更少的故障、更好的使用者體驗,以及依賴你的人更多的信任。一致地應用這些實踐能帶來更好的系統設計、更少的停機時間,以及更高效且更快樂的工程師。即使最糟的情況再次發生,你也能承受更少的損害、更快地恢復,並擁有更多數據來持續強化生產環境。