本章探討簡單性(Simplicity)為何是 SRE 的核心目標,以及如何衡量、推動和重獲系統的簡單性。簡單的系統更可靠、更容易理解、維護和測試。對 SRE 而言,簡單性是一個端到端的目標,不僅限於程式碼本身,還延伸到系統架構、工具和管理軟體生命週期的流程。
衡量複雜度#
衡量軟體系統的複雜度並非絕對的科學。程式碼層級有較為客觀的衡量方式,最著名的是 Cyclomatic Code Complexity(循環複雜度),它衡量程式碼中不同執行路徑的數量。許多 IDE(如 Visual Studio、Eclipse、IntelliJ)都內建了這類量測工具。
然而,我們較不擅長判斷:
- 量測出的複雜度是 必要的(necessary)還是 偶然的(accidental)
- 一個方法的複雜度如何影響更大的系統
- 哪種重構方法最為合適
在系統層級,正式的複雜度衡量方法很罕見。一些實用的代理指標包括:
- 訓練時間(Training time):新成員需要多久才能上線值班?文件品質差是主觀複雜度的重要來源
- 解釋時間(Explanation time):向新成員完整解釋系統架構需要多長時間?
- 管理多樣性(Administrative diversity):系統中有多少種不同方式可以配置類似的設定?
- 部署配置多樣性(Diversity of deployed configurations):生產環境中有多少種唯一的配置組合?
- 系統年齡(Age):系統有多老?Hyrum’s Law 指出,隨時間推移,API 使用者會依賴其實作的每個面向,導致脆弱且不可預測的行為
兩個關於複雜度的核心觀察:(1) 在運行中的軟體系統裡,除非有反向的努力,複雜度一般會持續增加;(2) 投入這種反向努力是值得的。
簡單性是端到端的,SRE 適合推動它#
生產系統通常不是以整體方式設計的,而是有機地成長。隨著團隊新增功能和發布新產品,系統會逐漸累積元件和連接。單一變更看似簡單,但每個變更都會影響周圍的元件,因此整體複雜度可以迅速變得難以承受。
複雜度是一種外部性(externality)——引入複雜度的個人、團隊或角色往往不會直接承受其成本,而是由後續在系統中工作的人承擔。因此,需要有人為端到端的系統簡單性代言。
SRE 天然適合這個角色,因為:
- SRE 的工作要求他們將系統視為一個整體
- SRE 不僅支援自己的服務,還必須了解服務互動的系統
- 產品開發團隊通常缺乏生產環境全局視角,SRE 可以提供設計和營運上的建議
在工程師首次值班前,鼓勵他們繪製(並反覆重繪)系統架構圖。在文件中保留一組標準圖表——對新工程師有用,也幫助資深工程師跟上變化。確保 SRE 審查所有重要設計文件,並記錄新設計如何影響系統架構。
案例研究 1:端到端 API 簡單性#
背景#
一家新創公司在核心程式庫中使用 key/value bag 資料結構。RPC 接受一個 bag 並返回一個 bag,實際參數以鍵值對儲存。核心程式庫支援 bag 的常見操作(序列化、加密、日誌),API 看似極其簡單且靈活。
問題#
客戶端為這種抽象的核心 API 付出了代價:每個服務的鍵和值(及值的型別)需要仔細記錄但通常沒有被記錄。隨著參數的新增、移除或更改,維護向前/向後相容性變得困難。
教訓#
像 Google Protocol Buffers 或 Apache Thrift 這樣的結構化資料型別看似更複雜,但它們能產生 更簡單的端到端解決方案,因為它們強制進行前期設計決策和文件記錄。
案例研究 2:專案生命週期的複雜度#
當你審視現有系統的糾結時,可能會想用一個全新、乾淨、簡單的系統來替換它。但維護現有系統的同時創建新系統的成本可能不值得。
背景#
Borg 是 Google 內部的容器管理系統,運行大量 Linux 容器。隨著硬體變化、功能增加和規模擴大,Borg 及其生態系統逐漸成長。Omega 旨在成為更有原則、更乾淨的 Borg 替代品,但計畫遇到了嚴重問題:
- Borg 在 Omega 開發期間持續演進,Omega 永遠在追趕一個移動的目標
- 改善 Borg 的困難程度被過度悲觀估計,而對 Omega 的期望過度樂觀
- 從 Borg 遷移到 Omega 的難度被嚴重低估——數百萬行配置代碼、數千個服務和眾多 SRE 團隊意味著遷移成本極高
決策與教訓#
最終,團隊將 Omega 設計中產生的一些想法回饋到 Borg 中,並利用 Omega 的許多概念來啟動開源容器管理系統 Kubernetes。
考慮重寫時,請思考完整的專案生命週期:追趕移動目標的開發、完整的遷移計畫、遷移期間的額外成本。不要將預期結果與當前系統比較,而要與「如果投入相同努力改善現有系統」的結果比較。
重獲簡單性#
大多數簡化工作包括從系統中移除元素。有時簡化是直接的(移除未使用的依賴),有時需要重新設計(例如將重複的遠端資料擷取合併為一次)。
關鍵原則:
- 領導層必須確保簡化努力得到慶祝和明確的優先排序
- 簡化是效率——它節省的是工程時間和認知負荷
- 同等慶祝程式碼的新增和移除(Google 內部網為刪除大量程式碼的工程師顯示「Zombie Code Slayer」徽章)
- 預留工程專案時間的 10% 用於「簡化」專案
- 將簡單性設為特別複雜系統或超載團隊的明確目標
繪製系統架構圖時,可以尋找以下問題:
- 放大效應(Amplification):呼叫返回錯誤或超時時進行多層重試,導致 RPC 總數倍增
- 循環依賴(Cyclic dependencies):元件直接或間接依賴自身,嚴重損害系統完整性,可能導致冷啟動不可能
案例研究 3:Display Ads 蜘蛛網的簡化#
背景#
Google 的 Display Ads 業務包含許多相關產品,部分來自收購(DoubleClick、AdMob、Invite Media 等)。這些獨立開發的產品形成了一個難以推理的互連後端系統。觀察流量通過各元件的情況困難,容量規劃也不精確。
做法#
Ads serving SRE 是標準化的天然推動者——每個元件有特定的開發團隊,但 SRE 為整個堆疊值班。團隊草擬了統一標準並與開發團隊合作逐步採用:
- 建立單一的大型資料集複製方式
- 建立單一的外部資料查詢方式
- 提供監控、配置和容量規劃的通用範本
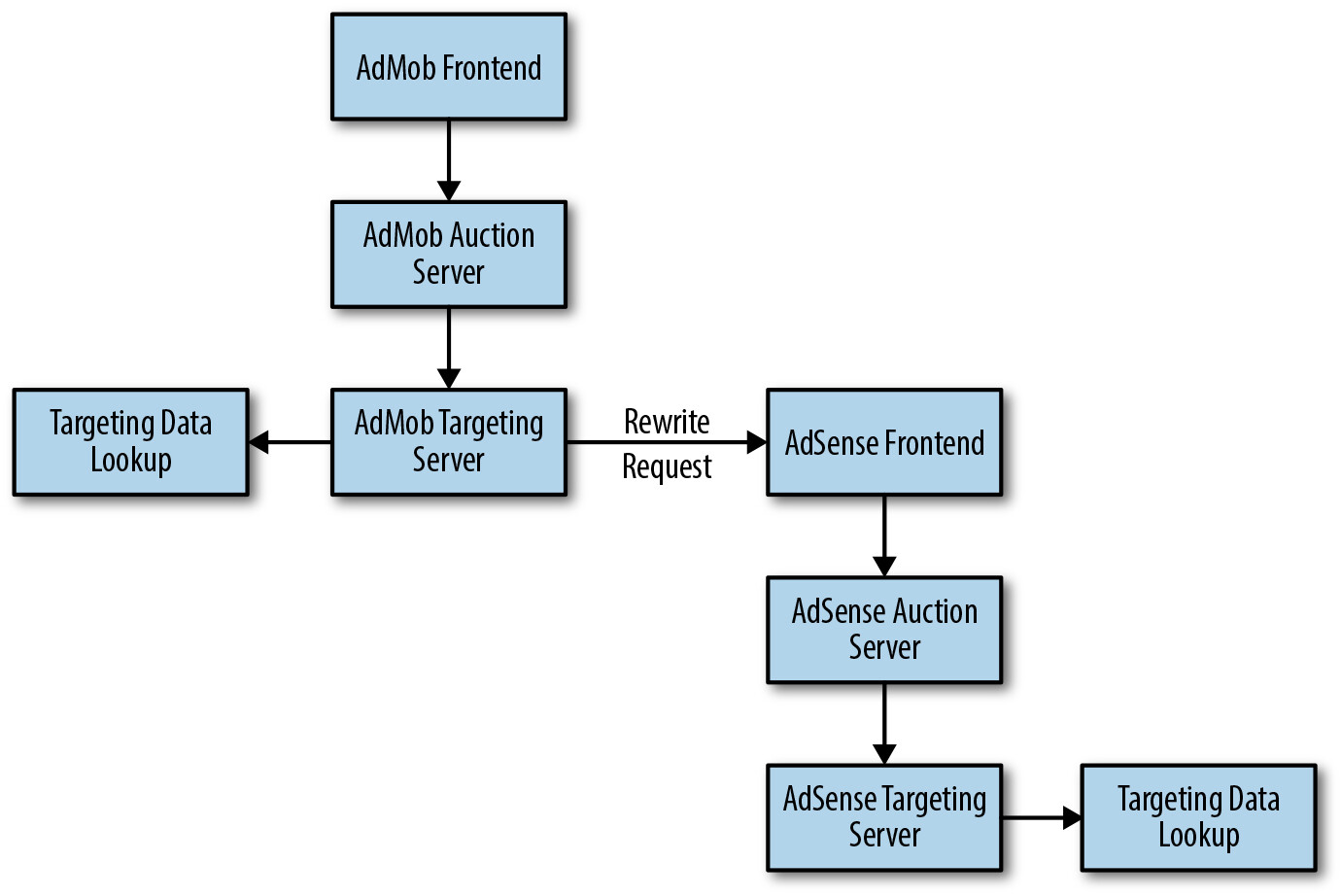
Figure 7.1: Previously, an ad request might hit both the AdMob and AdSense systems
在簡化之前,當一個廣告請求可能命中兩個定向系統時,需要改寫請求以符合第二個系統的期望,這需要額外的程式碼和處理,也增加了不良迴圈的可能性。
簡化後,團隊在共用程式中加入滿足所有使用情境的邏輯,逐步移除功能旗標,將功能整合到更少的伺服器後端。統一後的拍賣伺服器可以直接與兩個定向伺服器溝通,資料查詢只需進行一次。
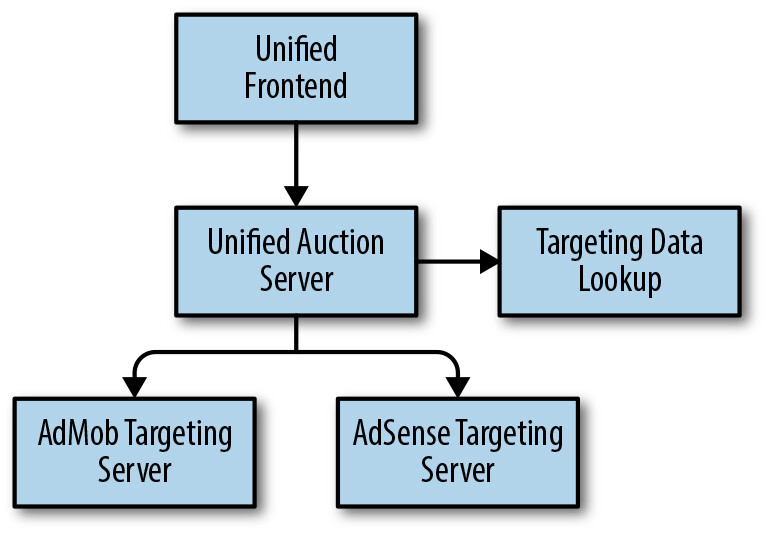
Figure 7.2: The unified auction server now performs a data lookup only once
教訓#
- 最好以漸進方式將已運行的系統整合到自己的基礎設施中
- 類似函數在程式中是「程式碼異味」(code smell),冗餘查詢在請求中是「系統異味」(system smell)
- 建立有 SRE 和開發人員認同的明確標準,能為移除複雜度提供清晰藍圖
案例研究 4:在共享平台上運行數百個微服務#
背景#
Google 在過去 15 年開發了多個成功的產品線,許多系統擁有專屬的 SRE 團隊和領域特定的生產堆疊,包括客製化的開發工作流、CI/CD 軟體週期和監控。這些獨特的生產堆疊在維護、開發成本和獨立的 SRE 投入方面產生了顯著的開銷。
做法#
社群網路領域的一組 SRE 團隊致力於將其服務的生產堆疊整合為 單一的受管微服務平台,由單一 SRE 群組管理。共享平台符合最佳實踐,自動配置許多先前未充分利用的可靠性和除錯功能。新服務必須使用共用平台,舊服務必須遷移或淘汰。
成果#
- 開發團隊可以在沒有深度 SRE 介入的情況下運行數百個服務
- 分層的 SRE 參與模式(tiered SRE engagement)變得常見:從輕度諮詢和設計審查到深度參與(SRE 共同值班)
教訓#
- 從稀疏或不明確的標準轉向高度標準化的平台是長期投資
- 每一步都是漸進的,但最終能減少開銷,使大規模運行服務成為可能
- 重要的是讓開發人員看到轉換的價值——在每個開發階段都提供漸進的生產力收益
案例研究 5:pDNS 不再依賴自身#
背景#
Google 生產環境中的客戶端使用 Svelte 查詢服務的 IP 位址。過去,客戶端使用 pDNS(Production DNS)查詢 Svelte 的 IP,而 pDNS 透過負載均衡器存取,負載均衡器又使用 Svelte 來查詢 pDNS 伺服器的 IP——形成了 循環依賴。
正常情況下查詢不會出問題,因為 pDNS 有複製機制,打破依賴迴圈所需的資料始終在某處可用。但冷啟動將是不可能的。如同一位 SRE 所說:「我們就像只能用上一堆營火的火把來點火的穴居人。」
解決方案#
修改 Google 生產環境中的低層元件,在所有機器的本地儲存中維護附近 Svelte 伺服器的當前 IP 位址列表。此外還引入了白名單機制來控制允許與 pDNS 通訊的服務集合,逐步縮小該集合。
教訓#
- 注意服務的依賴關係——使用明確的白名單防止意外的依賴增加
- 特別警惕循環依賴
結論#
簡單性是 SRE 的自然目標,因為簡單的系統往往更可靠且更易於運行。雖然很難定量衡量分散式系統的簡單性,但存在合理的代理指標,值得選取一些並努力改善。
SRE 因其對系統的端到端理解,處於識別、預防和修復複雜度來源的絕佳位置。SRE 應儘早參與設計討論,以其獨特的視角權衡替代方案的成本和收益,特別關注簡單性。SRE 也可以主動制定標準來統一生產環境。
推動簡單性是 SRE 職責的重要部分。SRE 領導層應賦予團隊推動簡單性的權力,並明確獎勵這些努力。系統在演進過程中不可避免地向複雜度靠攏,因此追求簡單性需要持續的關注和承諾。