本章深入探討如何識別、衡量並消除 toil(苦差事),涵蓋 toil 的定義與分類、衡量方法、管理策略,以及兩個大型案例研究——資料中心網路自動化修復與淘汰 filer 儲存系統。
什麼是 Toil?#
Toil 是指與維運服務相關的重複性、可預測、持續不斷的工作流。Google SRE 將營運性工作的時間上限設定為 50%,其餘時間應用於工程專案。識別與量化 toil 是優化團隊時間的第一步。
Toil 的特徵呈光譜分布,包含以下面向:
- 手動(Manual):例如工程師手動登入伺服器刪除暫存檔案來釋放磁碟空間
- 重複性(Repetitive):同樣的問題會反覆發生
- 可自動化(Automatable):如果修復文件內容讀起來像虛擬碼,那它就能被自動化
- 非策略性/被動(Nontactical/Reactive):過多的「磁碟已滿」或「伺服器掛掉」警報會分散工程師對高價值工作的注意力
- 缺乏持久價值(Lacks Enduring Value):關閉一張工單讓服務暫時恢復,但不能防止未來再度發生
- 增長速度至少與其來源相當(Grows at Least as Fast as Its Source):例如硬體維修工作量隨伺服器數量線性增長
Toil 會逐漸侵蝕團隊士氣。花在 toil 上的時間通常意味著無法進行批判性思考或發揮創造力。減少 toil 是對工程師才能的尊重——讓他們投入在需要人類判斷力的領域。
範例:手動回應 Toil#
John Looney(後來加入 Facebook 的 Production Engineering 主管)分享了他加入 Google 時的經驗:他的第一個任務是登入損壞的機器進行調查與修復,但隨時有超過 20,000 台損壞的機器。他發現上千台機器因核心驅動程式產生大量無用日誌而導致根檔案系統塞滿。
他原本計畫寫腳本來清理日誌,但資深工程師指出:應該修復根本原因,而非掩蓋症狀。最終他直接修改了核心原始碼中的問題程式碼,並向核心團隊提交了 bug 來改進測試套件。他以成本分析(每台伺服器每小時 1 美元,總計每小時 1,000 美元)說服開發團隊接受修補。
理想的組織文化應獎勵根本原因修復(root-cause fix),而非僅掩蓋問題的變通方案。
衡量 Toil#
經驗與直覺雖然可能產生結果,但它們不可重複、不客觀、不可轉移。同一團隊的成員常對 toil 的嚴重程度得出不同結論。要在長期維持聚焦並證明投入的合理性,需要客觀的衡量指標。

Figure 6.1: Estimate the amount of time you'll spend on toil reduction efforts
在開始消除 toil 專案前,應分析成本與效益,確認消除 toil 節省的時間至少與開發自動化方案的投入成正比。即使單純的「工時節省 vs 工時投入」看起來不划算,自動化仍有許多間接好處:
- 工程專案工作量隨時間增長(進一步減少 toil)
- 團隊士氣提升、人員流失與倦怠降低
- 減少中斷導致的上下文切換,提高生產力
- 流程更清晰、更標準化
- 技術技能與職涯成長
- 縮短訓練時間
- 因人為錯誤導致的故障減少
- 安全性改善
- 用戶請求的回應時間縮短
衡量 toil 的三步驟:
- 識別它:由利害關係人(包含實際執行工作的人)來識別
- 選擇適當的度量單位:分鐘、小時是自然選擇;也可用已套用的 patch、已完成的工單、手動生產環境變更等作為單位。需考慮上下文切換的成本
- 持續追蹤:在消除 toil 的努力前、中、後都要追蹤,並簡化收集流程以避免產生新的 toil
Toil 分類#
Toil 隱藏在日常瑣事中。以下是常見的 toil 類型:
業務流程(Business Processes)#
這可能是最常見的 toil 來源。團隊管理計算、儲存、網路、負載平衡器、資料庫等資源,處理用戶上線、機器設定、軟體更新、容量調整等工單驅動的流程。工單型 toil 特別隱蔽,因為它「通常能完成目標」——用戶得到他們要的,而 toil 平均分散在團隊中,不會顯著地呼喊著需要修復。
生產環境中斷(Production Interrupts)#
時間敏感的維護任務:修復資源短缺(磁碟、記憶體、I/O)、手動釋放空間、重啟記憶體洩漏的應用程式、更換硬碟、手動調整容量等。這類中斷會把注意力從更重要的工作中帶走。
發布管理(Release Shepherding)#
即使有自動化、完整的測試覆蓋率和程式碼審查,部署流程不總是順利。發布請求、回滾、緊急修補和重複的手動設定變更仍可能產生 toil。
遷移(Migrations)#
從一個技術遷移到另一個。雖然看似「一次性工作」,但大規模手動遷移很可能涉及 toil——工作是重複的,且遷移前後的業務價值本質上相同。
成本工程與容量規劃(Cost Engineering and Capacity Planning)#
無論擁有硬體還是使用雲端,都有相關 toil:確保成本效益基線、準備高流量事件、審查上下游服務層級、優化工作負載配置、依照雲端計費特性優化應用程式等。
不透明架構的故障排除(Troubleshooting for Opaque Architectures)#
分散式微服務架構中,新的故障模式不斷出現。問題排查本身不是壞事,但應聚焦在新穎的故障模式,而非每週因脆弱架構引起的同類型故障。
一個 4 個 9 的服務若增加 9 個 4 個 9 的關鍵依賴,其可用性將降至 0.9999^10 = 99.9%,實質變成 3 個 9 的服務。
Toil 管理策略#
以下是一系列通用策略,可在規劃 toil 消除方案時參考:
識別與衡量 Toil#
採用資料驅動的方法來識別和比較 toil 來源、做出客觀的修復決策、量化 ROI。如果團隊正經歷 toil 超載,應將 toil 消除視為獨立專案。Google SRE 團隊常用 bug tracker 追蹤 toil,並根據修復成本與節省時間進行排序。
從系統中移除 Toil#
最佳策略是從源頭消除 toil。運行生產系統的團隊擁有寶貴的第一手經驗,知道哪些環節最容易產生 toil。SRE 團隊應與產品開發團隊合作,開發運維友善的軟體。
拒絕 Toil#
分析回應 toil 與不回應的成本。另一個策略是故意延遲 toil,讓任務累積後進行批次或並行處理,減少中斷並幫助辨識 toil 模式。
使用 SLO 減少 Toil#
明確定義的 SLO (Service Level Objective) 讓工程師做出知情決策。例如,如果忽略某些營運任務不會消耗或超過錯誤預算,就可以選擇不處理。聚焦整體服務健康而非個別裝置的 SLO 更靈活且可持續。
從人工支撐的介面開始#
對於有許多邊界情況的複雜業務問題,考慮部分自動化作為全面自動化的過渡步驟。服務透過定義的 API 接收結構化資料,但工程師仍可處理部分操作。這種「幕後工程師」方法允許逐步邁向全面自動化,同時避免在尚未完全理解領域前過度工程化。
提供自助服務方法#
透過 web 表單、腳本、API 或文件讓用戶自行操作。例如提供簡單的網頁表單或腳本來觸發虛擬機佈建,而非要求工程師提交工單。目標是將 80-90% 的請求轉為自助服務。
獲得管理層與同事支持#
短期內,toil 消除專案會減少可用於功能請求和其他任務的人力。但長期來看,團隊會更健康、快樂,有更多時間進行工程改進。使用客觀的 toil 指標來爭取推回不合理需求的空間。
將 Toil 消除包裝為功能#
尋找機會將 toil 消除策略與其他有吸引力的目標結合——如安全性、可擴展性或可靠性。客戶更願意放棄現有的 toil 產生系統,換取更好的新系統。
從小處開始,逐步改進#
不要試圖設計消除所有 toil 的完美系統。先自動化幾個高優先項目,然後用節省下來的時間改進方案。選擇明確的指標如 MTTR (Mean Time to Repair) 來衡量成功。
增加一致性#
大規模下,多樣化的生產環境會呈指數級增長管理難度。使用「寵物 vs 牲畜(Pets vs Cattle)」方法——從個別專用裝置轉向具有共同介面的設備群。一致的介面(分流、恢復流量、關機等)允許更靈活和可擴展的自動化。
Google 透過業務激勵對齊來鼓勵工程團隊在不斷演進的內部技術工具中統一。團隊可自由選擇方法,但必須自行承擔不支援工具或遺留系統產生的 toil。
評估自動化中的風險#
自動化擁有管理員級別的權限時,防禦性軟體至關重要。建議做法:
- 防禦性地處理用戶輸入,即使輸入來自上游系統
- 內建安全防護措施(命令超時、系統指標檢查、當前故障數量檢查)
- 注意即使是讀取操作,若實作粗糙,也可能觸發裝置負載飆升
- 自動化遇到不安全狀況時應預設交由人工操作
自動化 Toil 回應#
將手動工作拆解為可分別實作的元件,建立可組合的軟體庫供其他自動化專案重用。不要直接將人工工作流程逐字翻譯成機器工作流程,自動化也不應消除人類對「哪裡出了問題」的理解。
使用開源與第三方工具#
你不一定要自己做所有工作。許多一次性遷移可能不值得建構專屬工具,但你很可能不是第一個走這條路的組織。
使用回饋來改進#
主動向與你的工具和自動化互動的人尋求回饋。用戶的熟悉程度越低,主動尋求回饋就越重要。同時衡量自動化任務的效能指標:延遲、錯誤率、重工率、節省的人工時間。
遺留系統的處理路徑#
- 迴避(Avoidance):接受技術債,選擇不正面處理
- 封裝/增強(Encapsulation/Augmentation):在遺留系統外層建構抽象 API、自動化、監控和測試——如同將高利率技術債轉為低利率
- 替換/重構(Replacement/Refactoring):定義共同介面,逐步安全地遷移用戶
- 退役/託管所有權(Retirement/Custodial Ownership):大部分功能遷移後,未遷移的用戶承擔遺留系統的託管責任
案例研究 1:透過自動化減少資料中心的 Toil#
本案例突顯的 toil 消除策略:從系統中移除 toil、從小處開始、增加一致性、使用 SLO、評估自動化風險、使用回饋改進、自動化 toil 回應
背景#
Google 的資料中心隨著流量需求急劇增長。早期每個資料中心的網路拓撲只有少量網路裝置管理大量機器的流量。單一裝置故障可能嚴重影響效能,但小型工程團隊可以手動除錯並轉移流量。
下一代資料中心引入了軟體定義網路(SDN)和摺疊 Clos 拓撲,大幅增加了交換器數量。雖然單一故障的影響比以前小,但問題的龐大數量開始壓垮工程人員。
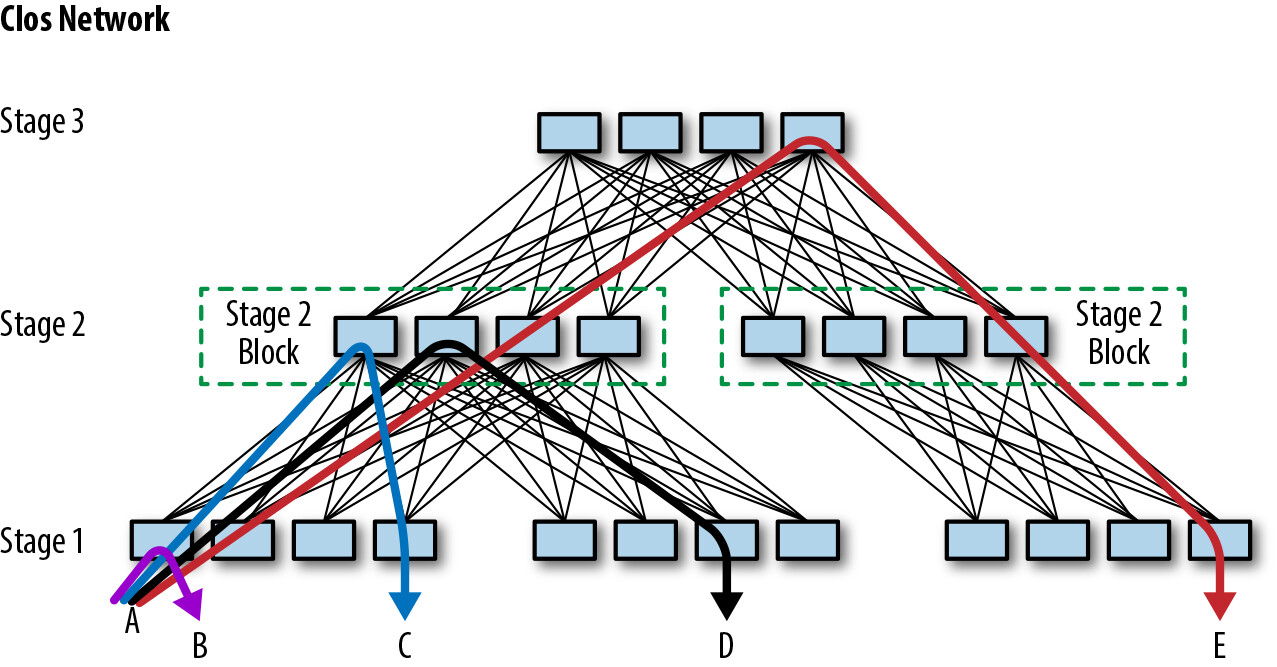
Figure 6.2: A small Clos network, which supports 480 machines attached below Stage 1
複雜的佈局對技術人員造成困惑:哪些鏈路需要檢查?需要更換哪張線路卡(line card)?Stage 2 交換器和 Stage 1 或 Stage 3 有什麼區別?關閉某台交換器會不會影響用戶?
問題陳述#
- 團隊無法快速擴充以跟上故障數量,且無法足夠快地修復問題
- 重複執行相同步驟導致過多人為錯誤
- 不同線路卡故障的影響程度不同,但缺乏優先排序機制
- 某些故障是暫時性的,希望能先嘗試重啟,再決定是否更換
- 手動風險評估充滿人為錯誤的機會
第一代設計:Saturn 線路卡修復#
在自動化之前,修復工作流程完全手動:
- 確認轉移流量是否安全
- 將流量從故障裝置移走(drain 操作)
- 執行重啟或修復(如更換線路卡)
- 將流量恢復至裝置(undrain 操作)
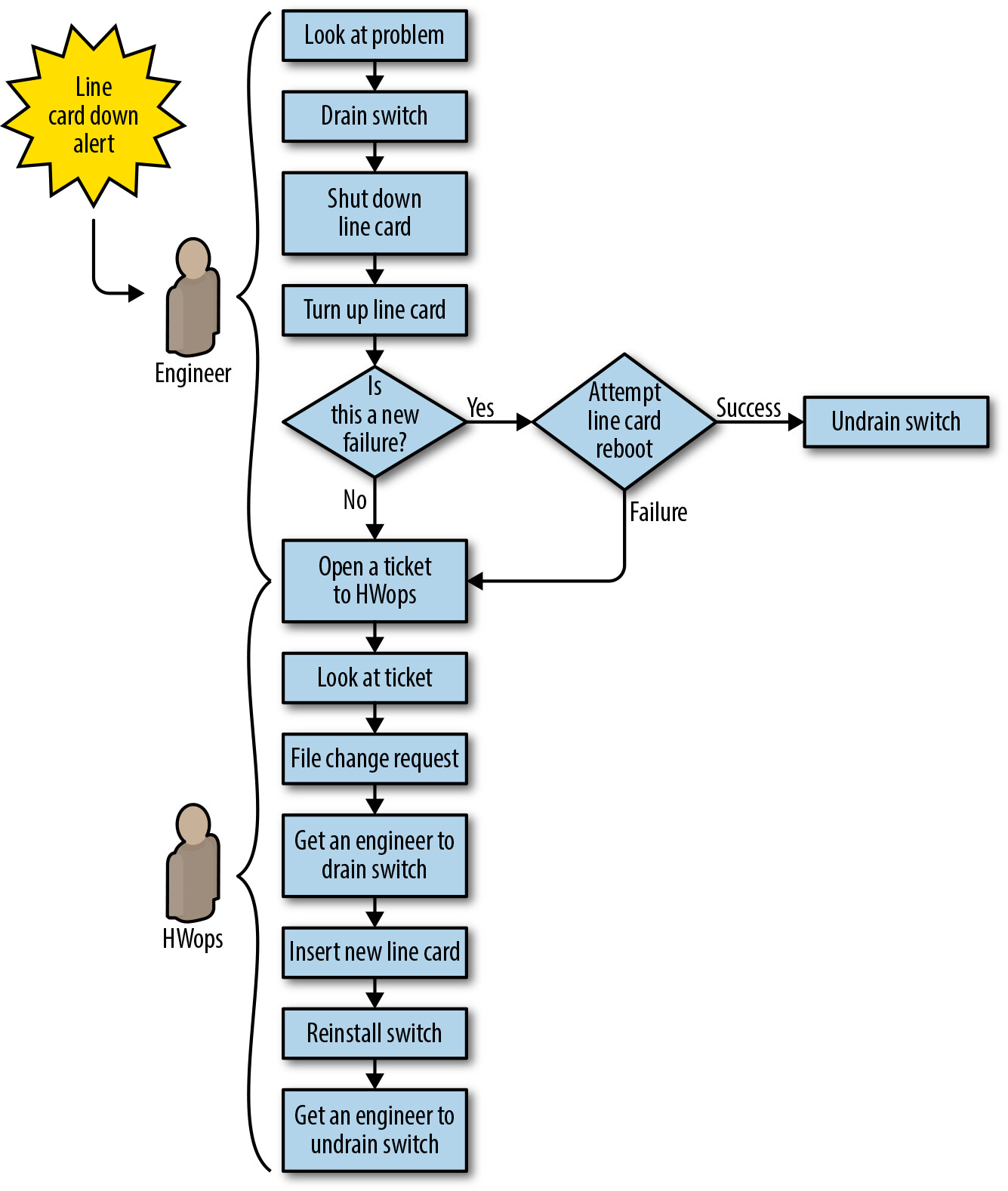
Figure 6.3: Datacenter (Saturn) line-card repair workflow before automation
這種不變且重複的 drain、undrain、修復工作是教科書等級的 toil。重複性工作還引入了新問題——例如工程師可能同時處理線路卡與除錯,不小心將未設定的交換器放回網路。
自動化解決方案的關鍵特性:
- 利用現有工具:將已有的告警機制重新用於觸發自動修復,並重用工單系統支援網路修復
- 自動化風險評估:在 drain 前自動確認不會意外隔離裝置,消除大量人為錯誤
- 打擊政策(Strike Policy):第一次故障僅重啟並重裝軟體;第二次故障觸發硬體更換
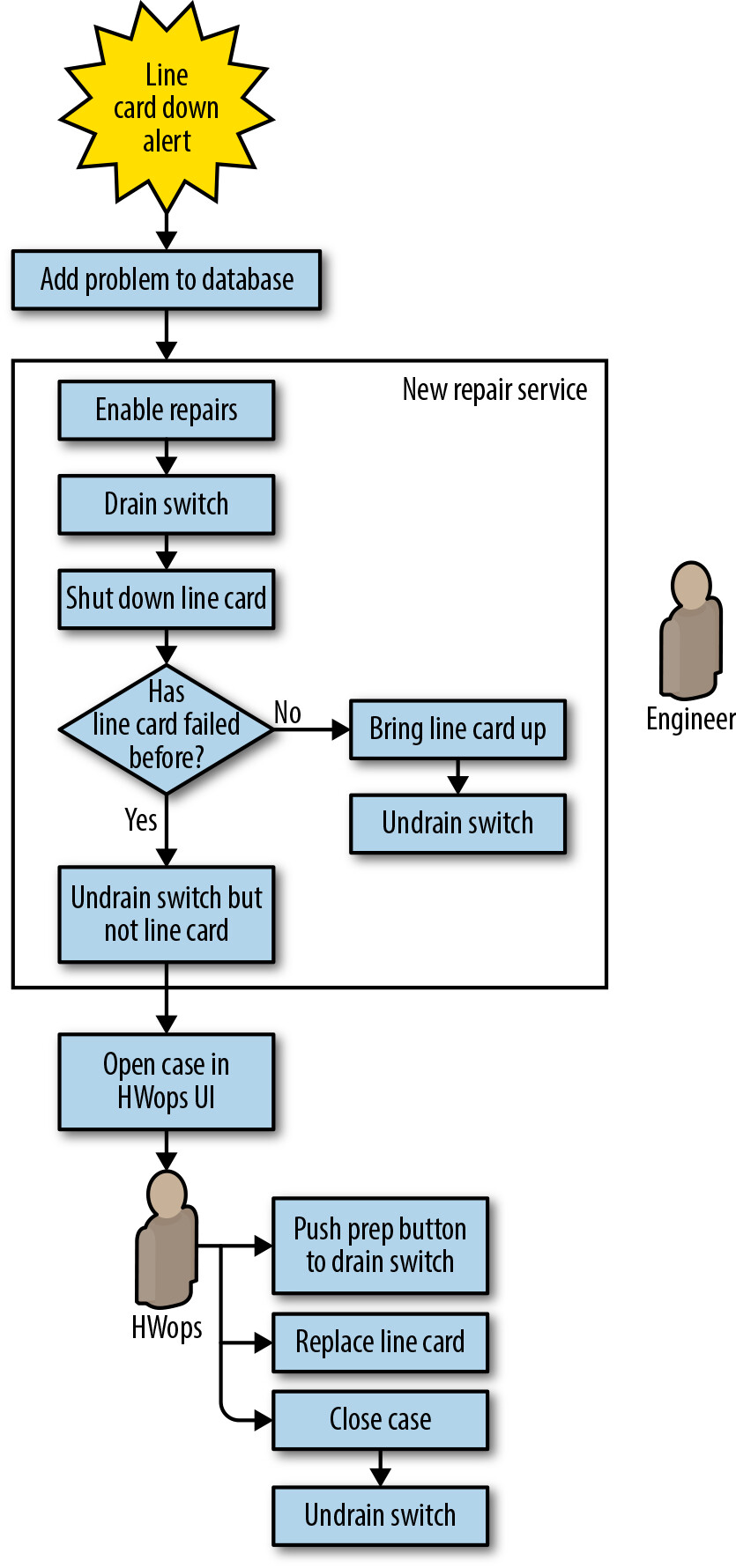
Figure 6.4: Saturn line-card repair workflow with automation
自動化工作流程:
- 偵測問題線路卡,在資料庫中記錄症狀
- 修復服務接管問題,執行風險評估後 drain 交換器、關閉線路卡
- 若為首次故障:重啟並 undrain,流程結束
- 若為第二次故障:進入步驟 3
- 工作流管理器將案例發送給技術人員
- 技術人員認領案例,透過 UI 按鈕啟動 drain,等待完成後更換線路卡
- 自動修復系統重新啟動線路卡並恢復流量
第二代設計:Jupiter 線路卡修復#
Jupiter 是下一代資料中心結構,規模比以往任何 Google 網路結構大六倍以上。相應地,潛在故障點也增加了六倍,但更大的冗餘性也允許更積極的自動化。
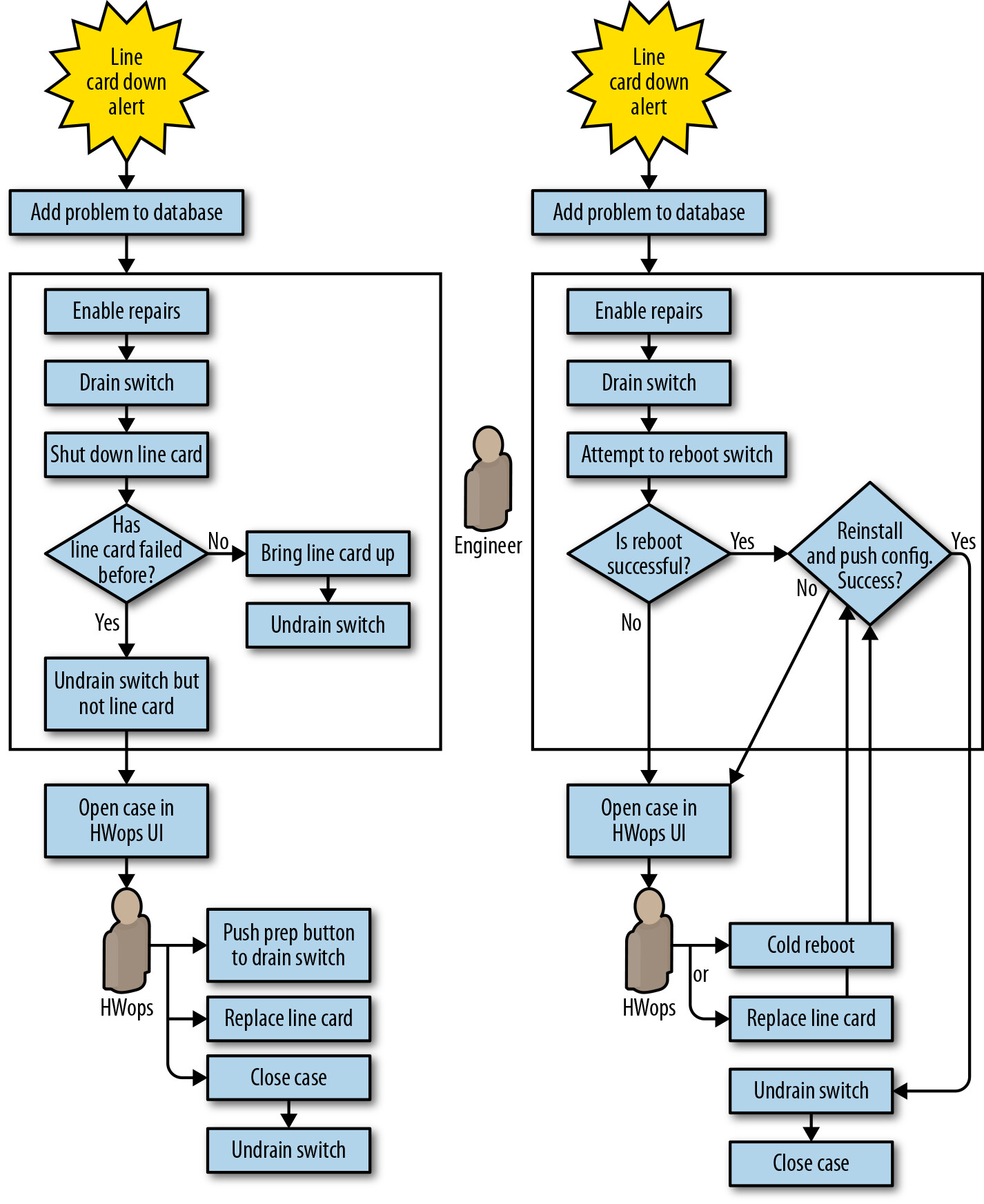
Figure 6.5: Saturn line-card down automation (left) versus Jupiter automation (right)
相較於 Saturn 的改進:
- 故障時自動 drain 整台交換器,不再需要技術人員手動啟動
- 新增硬體更換後自動安裝和推送設定的功能
- 啟用自動驗證修復是否成功
- 盡可能在不涉及技術人員的情況下恢復交換器
Jupiter 採用簡單統一的工作流程:宣告交換器故障、drain、開始修復。若六個月內第二次故障,直接要求硬體更換。
此外,團隊利用了現有的部署工具:
- 設定新交換器的安裝與驗證操作被重用於驗證已更換的交換器
- 部署新結構所需的 BERT(Bit Error Rate Test) 和纜線審計功能被重用於自動測試進入修復的鏈路
Jupiter 記憶體錯誤自動化#
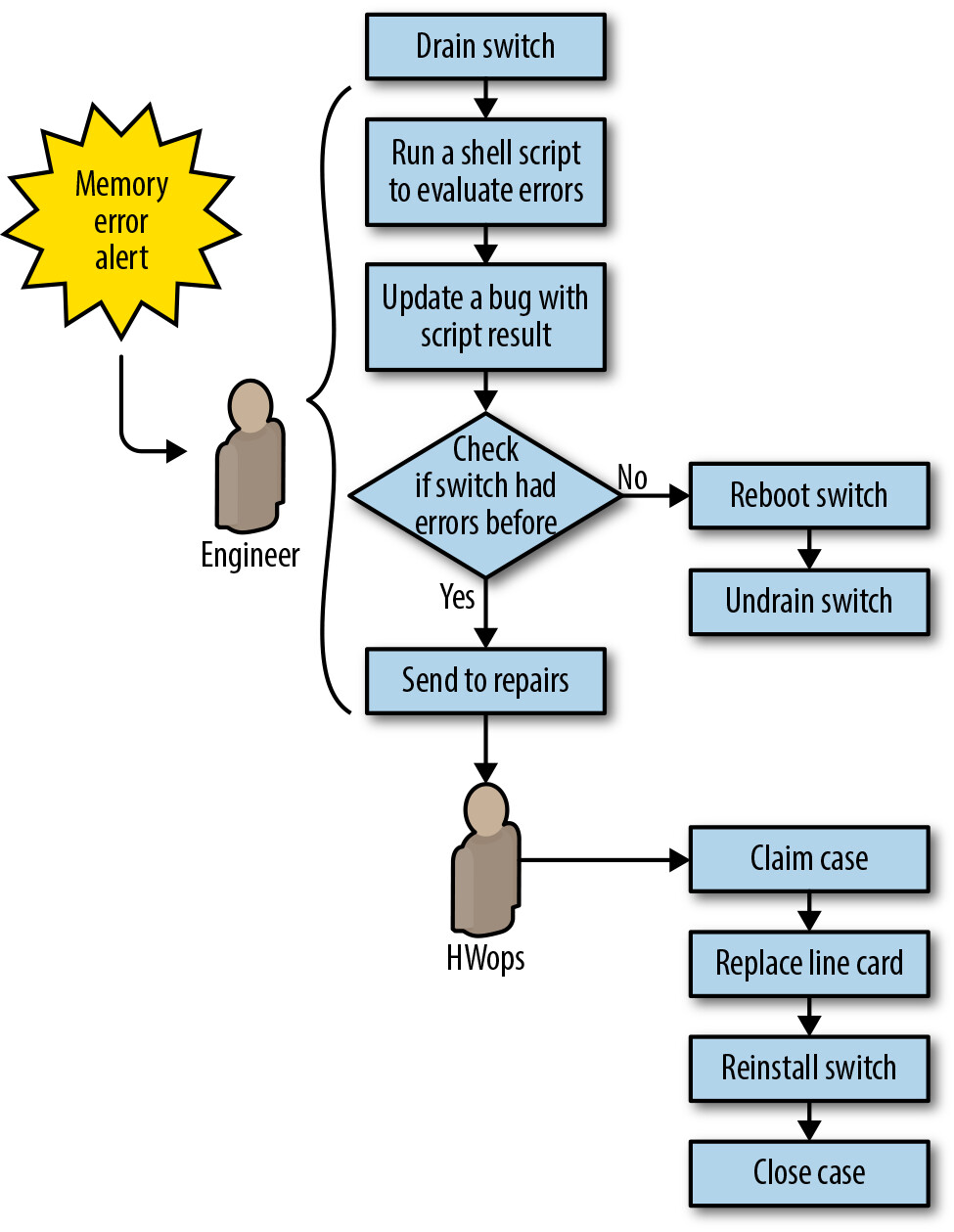
Figure 6.6: Jupiter memory error repair workflow before automation
自動化前,記憶體錯誤工作流程高度依賴工程師判斷故障是硬體還是軟體相關。自動化方案簡化了流程:不再嘗試區分錯誤類型,而是將記憶體錯誤與線路卡故障同等對待——只需在設定檔中新增一個症狀類型即可。
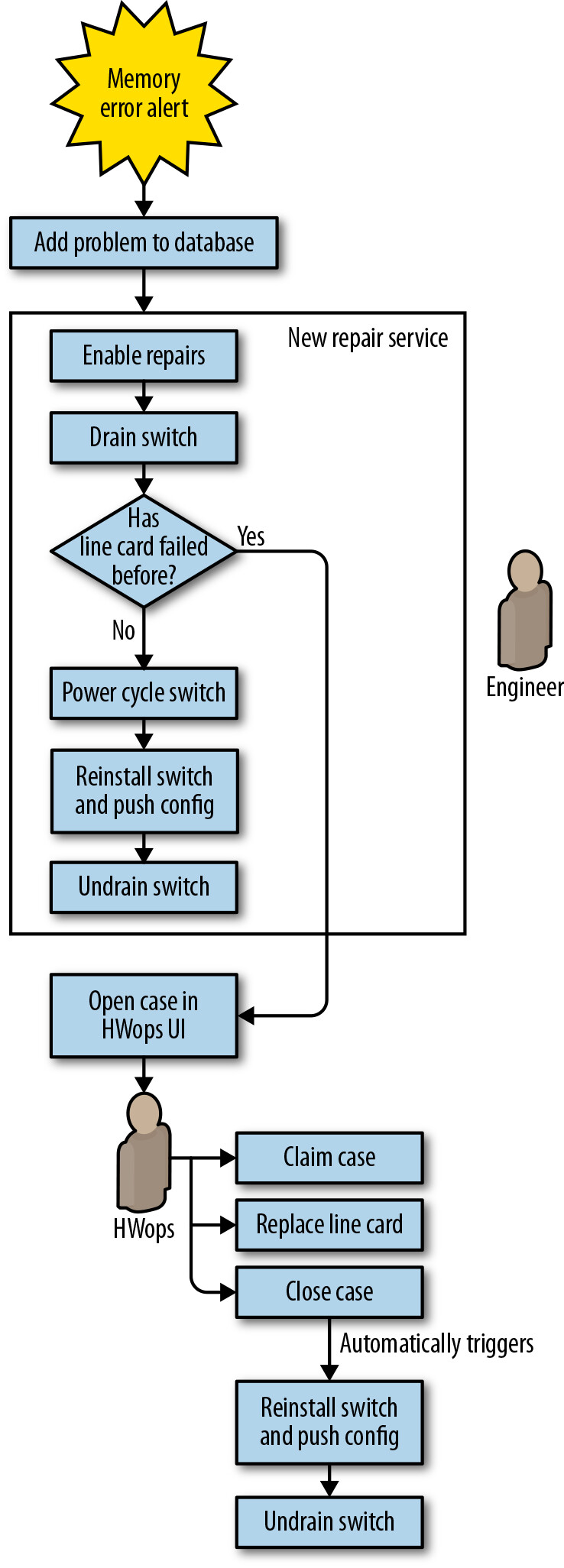
Figure 6.7: Jupiter memory error repair workflow with automation
經驗教訓#
UI 不應引入額外的負擔或複雜性
Saturn 的「Prep component」按鈕讓技術人員在準備更換前 drain 交換器,但引發了多個意外問題:按下按鈕後無法看到 drain 進度、按鈕狀態與交換器實際狀態不同步、新手技術人員不知如何聯繫工程師。後續設計改為在技術人員到達前就確保交換器已安全就緒。
不要依賴人類專業知識
過度依賴經驗豐富的技術人員來識別系統錯誤。一次高影響事件中,一位技術人員為加速流程,同時啟動了資料中心內所有等待修復的線路卡的 drain,造成網路壅塞和用戶可見的封包遺失。
設計可重用元件
避免單體設計。將複雜的自動化工作流程拆分為處理明確任務的可分離元件。早期 Jupiter 自動化的關鍵元件可以在每一代結構中輕鬆重用或調整。
不要過度分析問題
團隊花了**近三年(2012-2015)**收集超過 650 個記憶體錯誤問題的資料,試圖精確區分軟體和硬體錯誤,最終發現這是過度分析。一旦決定對任何偵測到的錯誤採取行動,就可以直接用現有的修復自動化實作簡單策略。結果發現大多數錯誤是暫時性的,重啟後就恢復了。
有時不完美的自動化就夠好了
BERT 工具不支援網路管理鏈路,但團隊直接讓這些鏈路跳過驗證。因為它們不承載客戶流量,且可以之後再補充驗證功能。
修復自動化不是一勞永逸的
自動化可能存在很長時間。由於 Jupiter 結構的零件短缺,Saturn 結構在原定壽命終止日期之後仍然存活很久,需要很晚才引入一些改進。設計自動化時應考慮靈活演進,基於策略的自動化(policy-based automation) 透過明確分離意圖與通用實作引擎來實現。
內建風險評估與縱深防禦
在主要的風險評估工具之外,引入了二級檢查——設定受影響鏈路和裝置的上限。超過閾值時自動開啟追蹤 bug。這個原本被視為臨時措施的二級檢查,後來成功識別了因電力中斷和軟體 bug 導致的異常修復率。
獲得失敗預算與管理層支持
修復自動化初期可能會失敗。管理層支持對於保留專案和賦能團隊堅持下去至關重要。建議為反 toil 自動化建立錯誤預算,並向外部利害關係人說明自動化儘管有失敗風險但仍然必要。
系統性思考
自動化前重新審視系統——能否先簡化系統或工作流程?關注工作流程的所有面向,不僅是對你個人產生 toil 的面向。確保自動化不會產生新的 toil——例如開啟不必要的需人工處理的工單。
案例研究 2:淘汰 Filer 支撐的 Home Directories(Project Moira)#
本案例突顯的 toil 消除策略:考慮淘汰遺留系統、將 toil 消除包裝為功能、獲得管理層支持、拒絕 toil、從人工支撐的介面開始、提供自助服務方法、從小處開始、使用回饋改進
背景#
Google 的 Corp Data Storage (CDS) SRE 團隊透過一組 Netapp Storage Appliances(以 NFS/CIFS 協定運作的「filers」)為所有 Googler 提供 home directories 和 Team Shares。類似 Active Directory 的 Roaming Profiles,Googler 可以在不同工作站和平台之間使用相同的 home directory。
問題陳述#
隨著時間推移,filer 方案被更好的儲存方案取代(版本控制系統、Google Drive、Google Cloud Storage 等),但舊系統仍在運行且營運成本高昂:
- NFS/CIFS 協定不適合 WAN:即使只有數十毫秒的延遲,用戶體驗就會快速惡化
- 擴展成本高:相較於替代方案,這些設備運行和擴展費用昂貴
- 安全性問題:要讓 NFS/CIFS 與 Google 的 Beyond Corp 網路安全模型相容需要大量工作
大量的 toil 源自工單驅動的儲存佈建流程:建立和設定共享空間、修改存取權限、排除終端用戶問題、管理容量的啟用與關閉。CDS 還需管理專用硬體的佈建、上架和佈線,有時甚至需要出差到遠端辦公室進行部署。
資料驅動的決策#
CDS 建立了一個名為 Moonwalk 的工具來分析員工如何使用服務。收集的指標包括:
- 每日活躍用戶(DAU) 和 每月活躍用戶(MAU)
- 哪些職務族群實際使用 home directories
- 每日使用 filer 的用戶最常存取什麼類型的檔案
Moonwalk 結合用戶調查,驗證了 filer 服務的業務需求可以由營運成本更低的替代方案更好地服務。另一個商業動機是:遷移經驗可以用來改進 G Suite/GCP 產品,幫助其他大型企業遷移。
替代方案#
沒有單一替代方案能滿足所有 filer 使用案例,但多個方案的組合可以涵蓋全部:
- x20(內部全球共享檔案系統):適合團隊分享靜態 artifacts 如二進位檔
- G Suite Team Drive:適合辦公文件協作,對延遲的容忍度比 NFS 好得多
- Google Colossus File System:允許團隊更安全、可擴展地分享大型資料檔案
- Piper/Git-on-Borg:更好地同步 dotfiles(工程師的個人化工具偏好)
- 新的 history-as-a-service 工具:跨工作站的命令列歷史記錄
設計與實作#
淘汰 filer 是一個持續多年的迭代努力,包含多個內部專案:
- Moira:Home directory 淘汰(本案例研究的焦點)
- Tekmor:遷移 home directory 用戶的長尾
- Migra:Team Share 淘汰
- Azog:退役 home directory/share 基礎設施與硬體
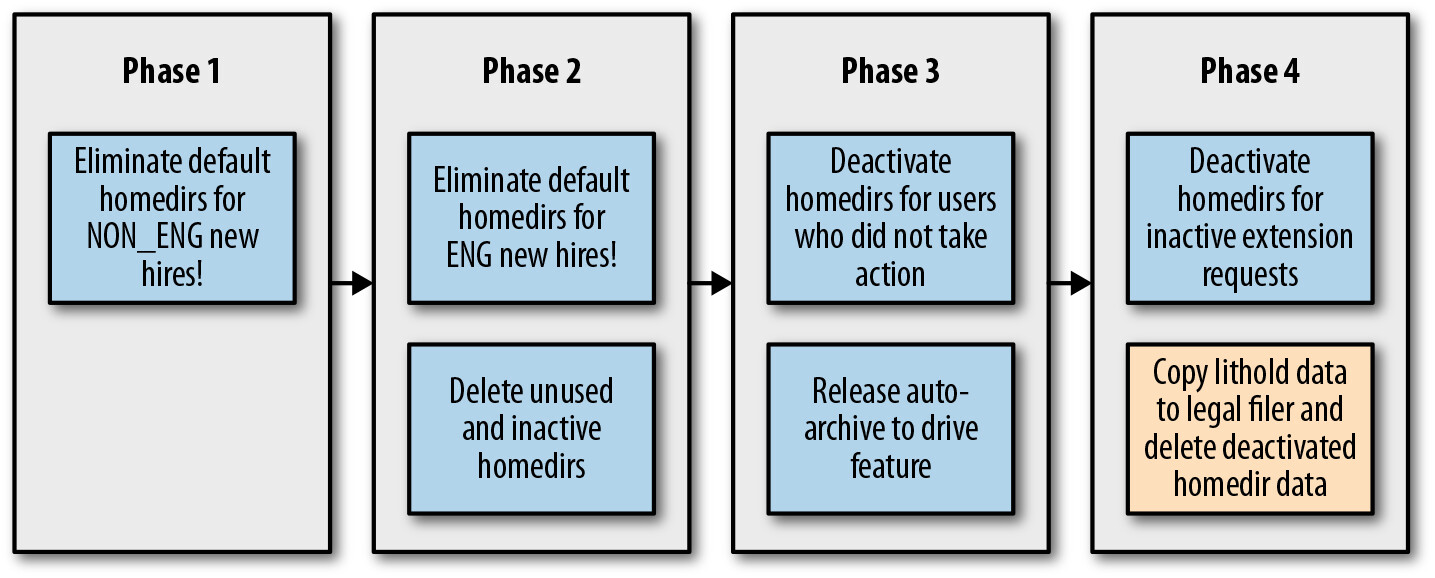
Figure 6.8: The four stages of Project Moira
Project Moira 分為四個階段。退役遺留系統的第一步是停止(或更實際地是減緩或阻止)新的採用。Moonwalk 資料顯示非工程類 Googler 最少使用共享 home directory,因此初始階段以這些用戶為目標。隨著階段範圍擴大,團隊對替代儲存方案和遷移流程的信心也隨之增長。
關鍵元件#
Moonwalk
將誰在何時存取什麼檔案的資料儲存在 BigQuery 中,支援報告和即席查詢。資料規模:跨 25 億個檔案、300 TB 磁碟空間、60,000 POSIX 用戶、400 磁碟卷、124 NAS 設備、全球 60 個地理站點。
Moira Portal
龐大的用戶群使得用手動工單流程管理淘汰工作不可行。Portal 提供:
- 描述專案的登陸頁面
- 持續更新的 FAQ
- 當前用戶共享空間的狀態和使用資訊
- 請求、停用、封存、刪除、延期或重新啟用共享空間的選項
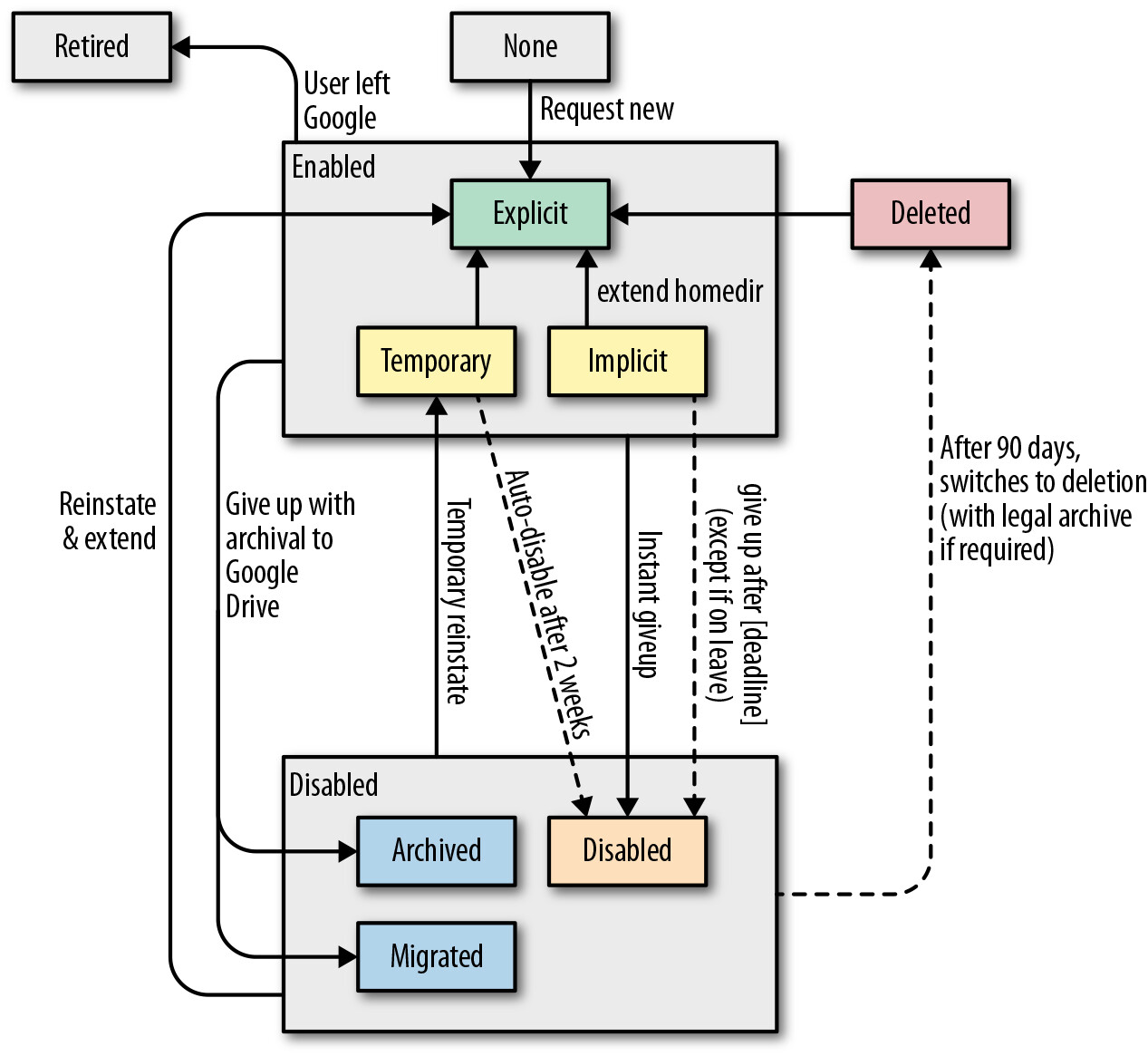
Figure 6.9: Business logic based upon user scenarios
業務邏輯相當複雜,需考慮多種用戶場景:用戶可能離開 Google、臨時休假、或資料處於法律訴訟保留狀態。Portal 以 Python + Flask 框架撰寫,讀寫 Bigtable,並使用多個背景工作和排程器管理任務。
封存與遷移自動化
需要大量輔助工具來整合 Portal 和設定管理,以及查詢和與用戶溝通。誤報(false positive)和漏報(false negative)都不可接受——誤報意味著錯誤地報告需要行動,漏報意味著未能通知用戶其資料即將被移除。
團隊與替代儲存系統的擁有者合作,將功能加入其產品路線圖。隨著專案進展,較不成熟的替代方案變得更適合 filer 使用案例。例如,使用另一團隊的內部工具將 Google Cloud Storage 的資料遷移到 Google Drive。
專案在各元件上採用漸進式開發——直到第三階段(將近兩年後)才接近功能完備。這種緩慢穩健的方法帶來的好處:
- 維持精簡團隊(平均 3 位 CDS 團隊成員)
- 減少對用戶工作流程的干擾
- 限制 Techstop(Google 內部技術支援)的 toil
- 按需建構工具以避免浪費工程投入
專案於 2016 年正式完成。Home directories 從 65,000 減少到大約 50 個。
經驗教訓#
挑戰既有假設,退役昂貴的業務流程
業務需求會漂移,新方案持續出現。以用戶分析和超越 toil 消除的商業理由來強化你的論點。Moira 的主要商業理由是 Beyond Corp 安全模型的好處——強調安全性使案例更具說服力。
建構自助服務介面
Moira 建構了自定義 Portal(成本相對較高)。但很多團隊使用版本控制管理服務,以 pull request 形式處理請求,幾乎不需要服務團隊的參與,同時獲得程式碼審查和持續部署的好處。
從人工支撐的介面開始
Moira 團隊多次使用「幕後工程師」方法。例如:共享空間請求開啟追蹤 bug,自動化處理請求時更新 bug。工單可作為自動化的快速 GUI——保留工作日誌、更新利害關係人、提供人工備援機制。
消融雪花(Melt Snowflakes)
自動化渴望一致性。Moira 的工程師選擇修改不符合預期的共享空間以符合工具的期望,而非修改工具來處理邊界案例。這讓大部分遷移流程實現了零接觸自動化。

Figure 6.10: The garden gnome that wouldn't go away
在 Google,「改變現實以符合程式碼」而非相反的做法被稱為「買下地精(Buying the Gnome)」。這源自早期購物搜尋引擎 Froogle 的趣事:搜尋 [running shoes] 時,一個穿著跑鞋的花園地精因 bug 排名靠前。多次修復未果後,有人發現它是 eBay 上的單件商品,於是直接買下了它。
運用組織推力(Organizational Nudges)
尋找方法引導新用戶採用更好的替代方案。Moira 要求新的共享空間或配額請求需要升級核准,並表彰退役共享空間的用戶。提供良好的文件、codelabs 和 cookbooks 讓用戶自行上手。
結論#
維運生產服務的 toil 至少與其複雜性和規模呈線性增長。自動化通常是消除 toil 的黃金標準,但也可以與其他策略結合。即使 toil 不值得完全自動化,也可以透過部分自動化或改變業務流程來減少工作量。
消除 toil 並非總是最佳解決方案。應考量識別、設計和實作 toil 消除方案的可衡量成本。一旦識別出 toil,必須透過指標、ROI 分析、風險評估和迭代開發來判斷何時消除 toil 是合理的。
Toil 通常從小處開始,但可能迅速增長到吞噬整個團隊。SRE 團隊必須堅持不懈地消除 toil——即使任務看似艱鉅,好處通常超過成本。本章描述的每個專案都需要團隊的堅持和奉獻,有時需要對抗懷疑論或組織阻力,並始終面臨競爭性的高優先事項。即使今天無法投入大型專案,也可以從小型概念驗證開始,幫助改變團隊對處理 toil 的意願。