本章說明如何將 SLO 轉化為可操作的告警,在消耗過多 error budget 之前回應問題。章節以一系列由簡到繁的實作方式,展示告警 metrics 和邏輯的演進,最終推薦 multiwindow, multi-burn-rate 告警作為最佳方案。範例使用簡單的 request-driven 服務和 Prometheus 語法,但概念適用於任何告警框架。
告警評估的四大屬性#
從 SLI(Service Level Indicator)和 error budget 產生告警時,目標是在**顯著事件(significant event)**發生時收到通知——即消耗大量 error budget 的事件。評估告警策略時應考量:
- Precision(精確度):偵測到的事件中,有多少比例是真正顯著的。100% 精確度代表每個告警都對應一個顯著事件
- Recall(召回率):顯著事件中有多少比例被偵測到。100% 召回率代表每個顯著事件都觸發告警
- Detection time(偵測時間):在各種條件下發送通知所需的時間。過長的偵測時間會消耗更多 error budget
- Reset time(重置時間):問題解決後告警持續多久才停止。過長的重置時間會造成混淆或導致問題被忽略
六種告警方式的演進#
本章提出六種告警方式,按保真度遞增排列。前三種為不可行的嘗試,後三種為可行策略,第六種最受推薦。
以下討論中的「error budgets」和「error rates」適用於所有 SLI,不僅限於名稱中含有 “error” 的指標。Error budget 給出允許的 bad events 數量,error rate 是 bad events 佔 total events 的比率。
方式 1:Target Error Rate >= SLO Threshold#
最簡單的做法:選擇一個小時間窗口(如 10 分鐘),當該窗口內的錯誤率超過 SLO 閾值時告警。
例如,SLO 為 30 天 99.9%,當前 10 分鐘錯誤率 >= 0.1% 時告警:
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate10m{job="myjob"} >= 0.001此方式偵測的 budget 消耗量 = alerting window size / reporting period。
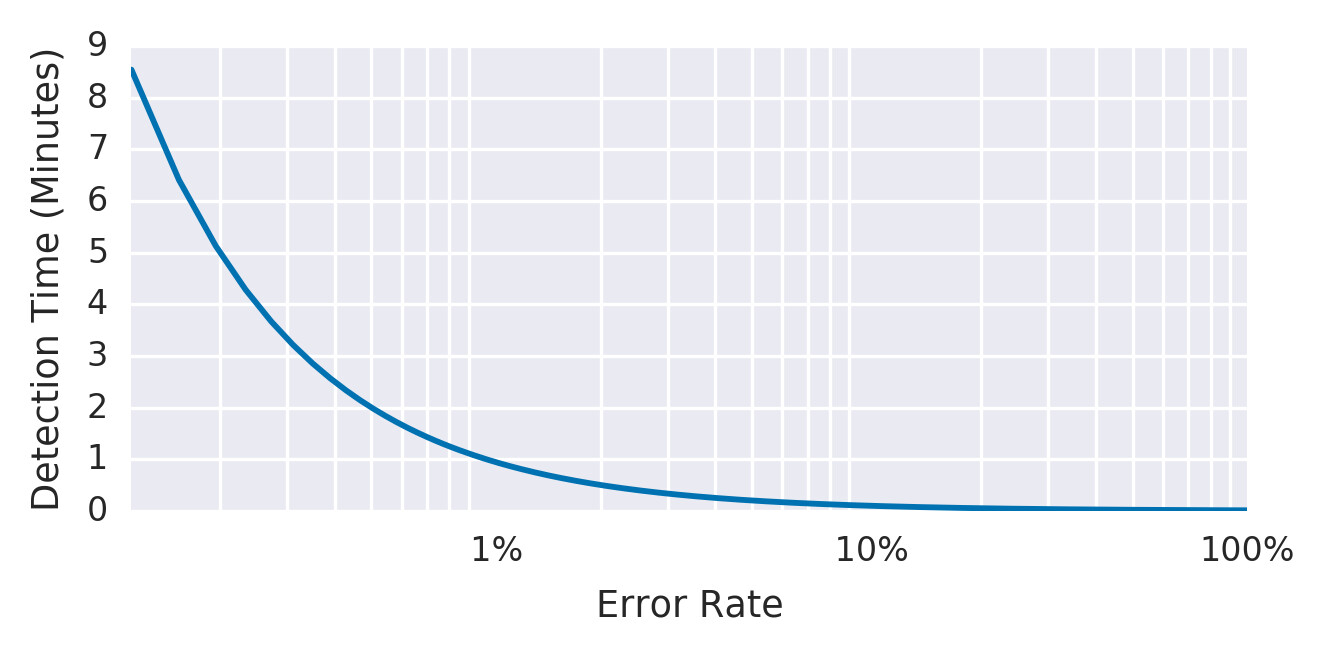
Figure 5.1: Detection time for an example service with an alert window of 10 minutes
| 優點 | 缺點 |
|---|---|
| 偵測時間佳:完全中斷時僅需 0.6 秒 | 精確度低:0.1% 錯誤率持續 10 分鐘僅消耗 0.02% 月度 error budget,卻會觸發告警 |
| 召回率佳:任何威脅 SLO 的事件都會被偵測 | 極端情況下每天可能收到 144 個告警,全部不處理仍能達標 SLO |
方式 2:增大告警窗口#
透過加大時間窗口提升精確度。例如,要求在消耗 5% 的 30 天 error budget 後才告警,需要一個 36 小時的窗口:
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate36h{job="myjob"} > 0.001偵測時間公式:(1 - SLO) / error ratio * alerting window size
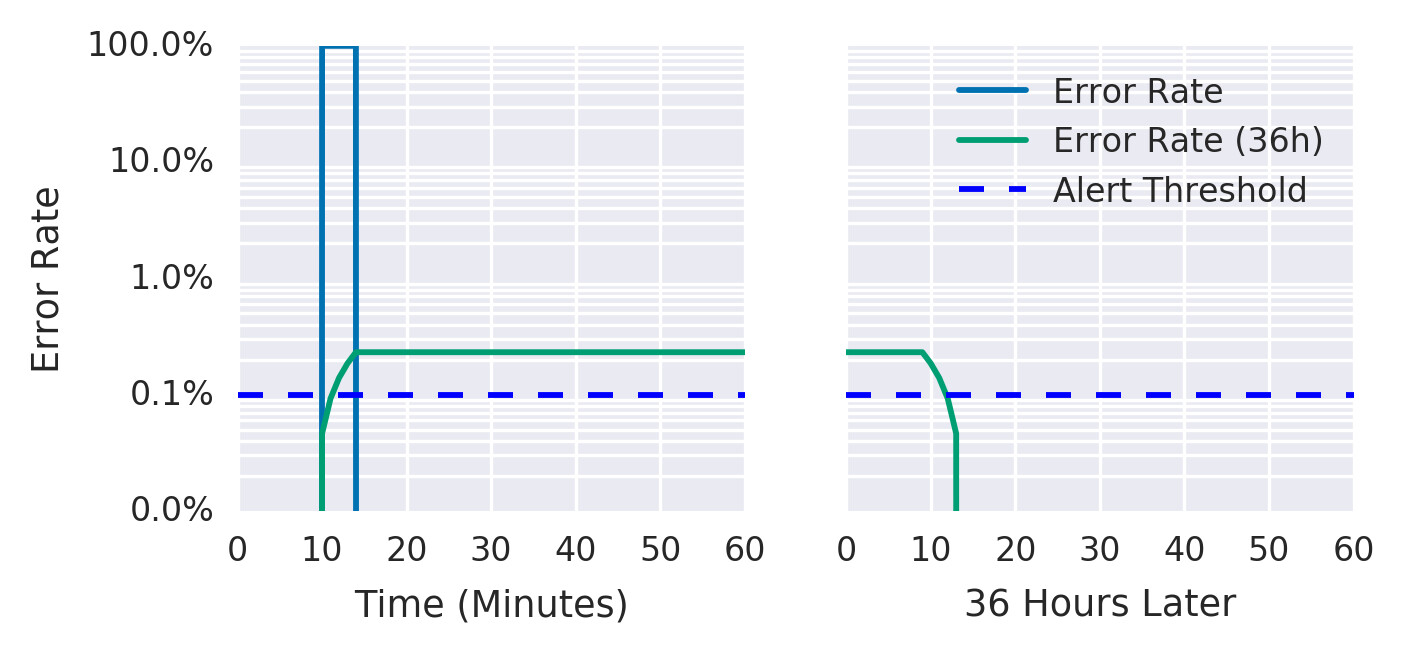
Figure 5.2: Error rate over a 36-hour period
| 優點 | 缺點 |
|---|---|
| 偵測時間仍佳:完全中斷時約 2 分 10 秒 | 重置時間極差:100% 中斷時告警會持續 36 小時 |
| 精確度較方式 1 改善 | 對大量資料點計算長窗口的率值,記憶體或 I/O 成本高 |
方式 3:遞增告警持續時間(Duration)#
使用 for 參數要求錯誤率在閾值以上持續一段時間才觸發:
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate1m{job="myjob"} > 0.001
for: 1h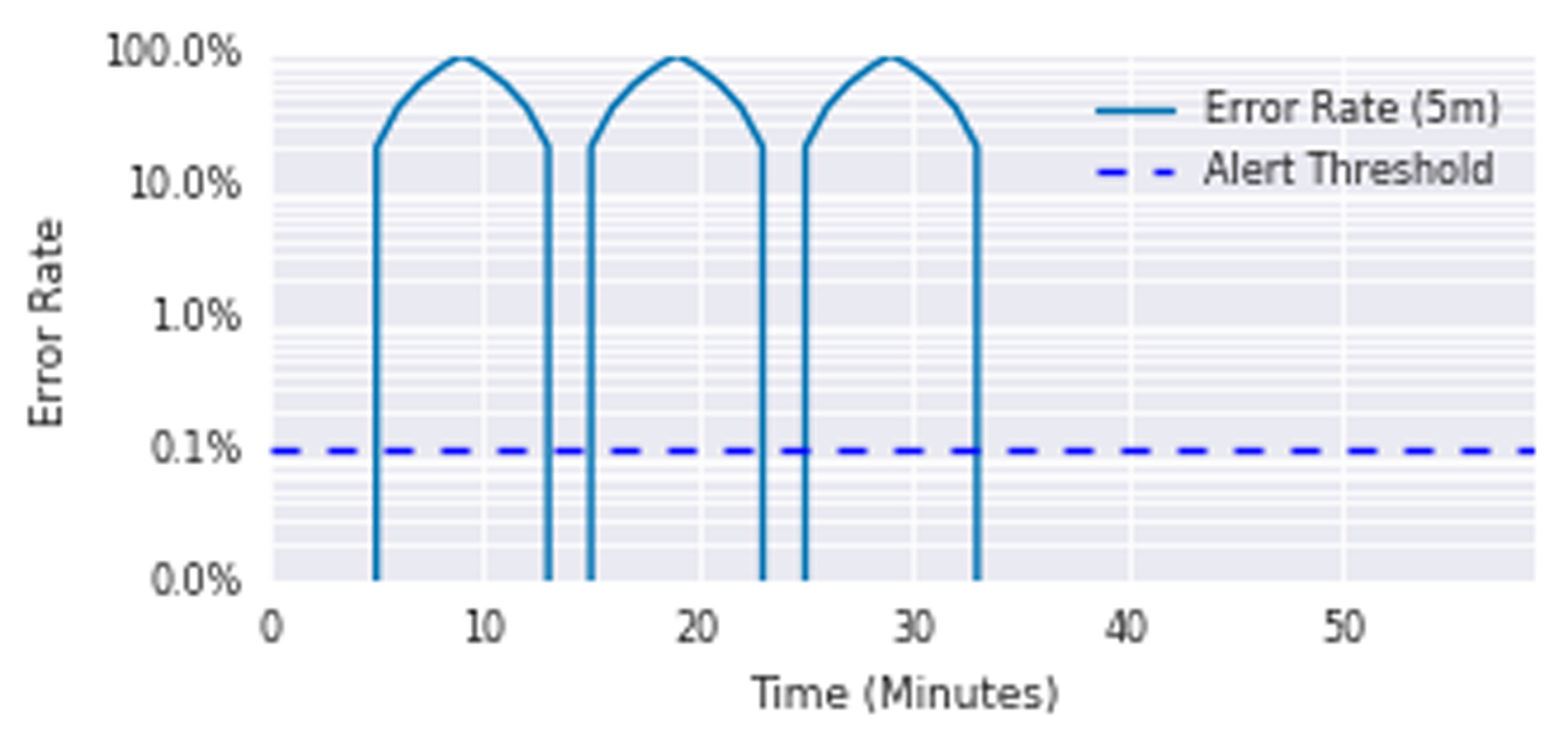
Figure 5.3: A service with 100% error spikes every 10 minutes
| 優點 | 缺點 |
|---|---|
| 要求持續錯誤率才觸發,精確度較高 | 召回率和偵測時間皆差:100% 中斷也要等一小時才告警,會消耗 140% 月度 budget |
| 指標暫時回到 SLO 內就會重置計時器,波動性 SLI 可能永遠不告警 |
上圖展示:每 10 分鐘出現一次持續 5 分鐘的 100% 錯誤尖峰,消耗了 35% 的 error budget,告警卻從未觸發。
不建議將 duration 作為 SLO-based alerting 的一部分。Duration 不會隨事件嚴重程度調整,且波動性指標可能導致告警永遠不觸發。
方式 4:基於 Burn Rate 告警#
**Burn rate(燃燒率)**是服務相對於 SLO 消耗 error budget 的速度。
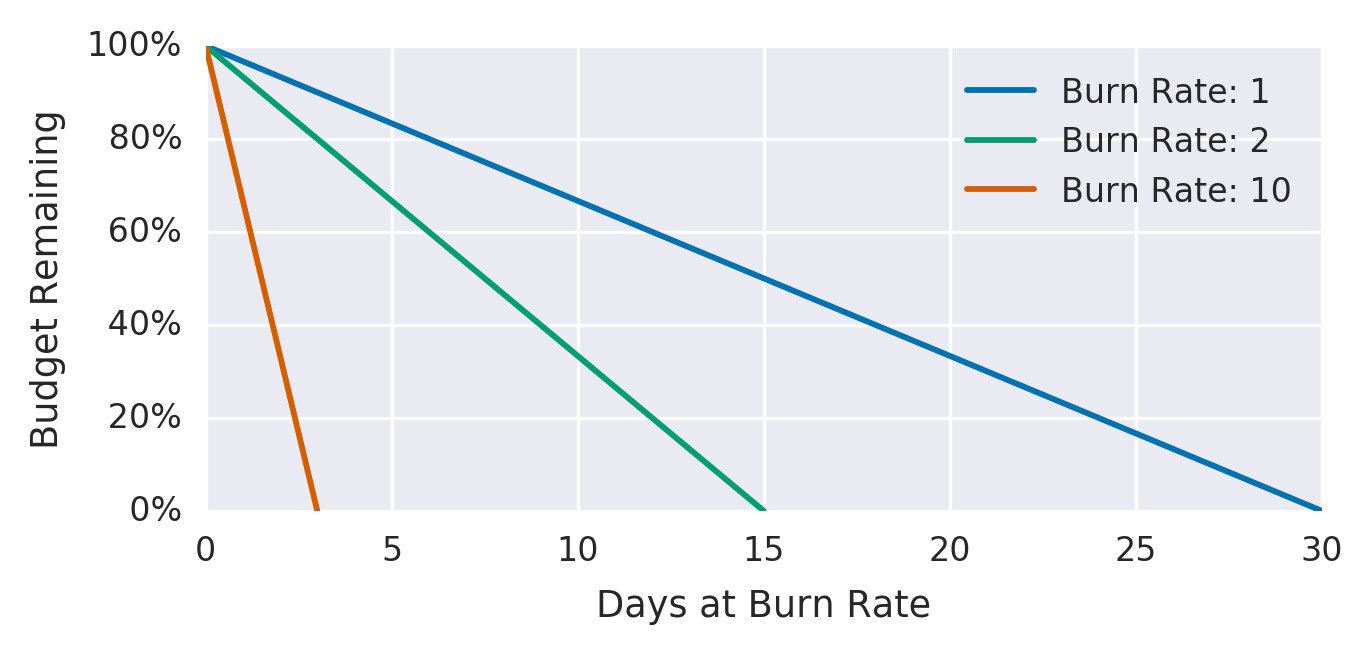
Figure 5.4: Error budgets relative to burn rates
以 SLO 99.9% / 30 天為例:
| Burn Rate | Error Rate | 耗盡時間 |
|---|---|---|
| 1 | 0.1% | 30 天 |
| 2 | 0.2% | 15 天 |
| 10 | 1% | 3 天 |
| 1,000 | 100% | 43 分鐘 |
固定一小時告警窗口,5% error budget 消耗為顯著事件,推導出 burn rate = 36:
- alert: HighErrorRate
expr: job:slo_errors_per_request:ratio_rate1h{job="myjob"} > 36 * 0.001告警觸發時間公式:(1 - SLO) / error ratio * alerting window size * burn rate
| 優點 | 缺點 |
|---|---|
| 精確度佳:選擇有意義的 budget 消耗比例作為告警條件 | 召回率低:35x burn rate 永不告警,但 20.5 小時耗盡全部 budget |
| 更短的時間窗口,計算成本低 | 重置時間 58 分鐘仍嫌過長 |
| 偵測時間佳 |
方式 5:多重 Burn Rate 告警#
使用多個 burn rate 和時間窗口,根據嚴重程度分級通知:
| SLO Budget 消耗 | 時間窗口 | Burn Rate | 通知類型 |
|---|---|---|---|
| 2% | 1 小時 | 14.4 | Page(即時呼叫) |
| 5% | 6 小時 | 6 | Page |
| 10% | 3 天 | 1 | Ticket(工單) |
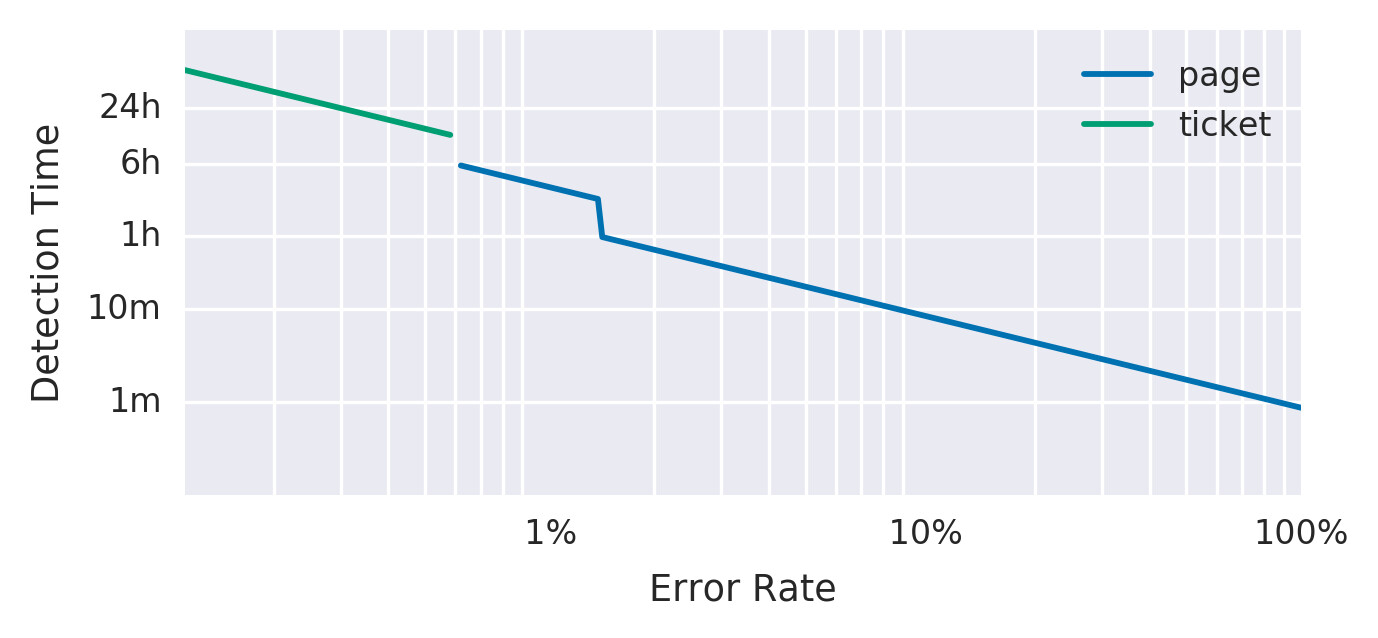
Figure 5.5: Error rate, detection time, and alert notification
| 優點 | 缺點 |
|---|---|
| 可根據緊急程度選擇最適當的告警類型 | 更多數字、窗口大小和閾值需要管理 |
| 精確度佳 | 三天窗口導致更長的重置時間 |
| 因三天窗口而有良好的召回率 | 多個條件同時為真時需實作告警抑制,避免重複通知 |
方式 6:多窗口、多重 Burn Rate 告警(推薦)#
在方式 5 的基礎上,增加一個較短的窗口來確認 error budget 是否仍在被消耗,從而減少 false positives。短窗口的最佳經驗值是長窗口的 1/12。
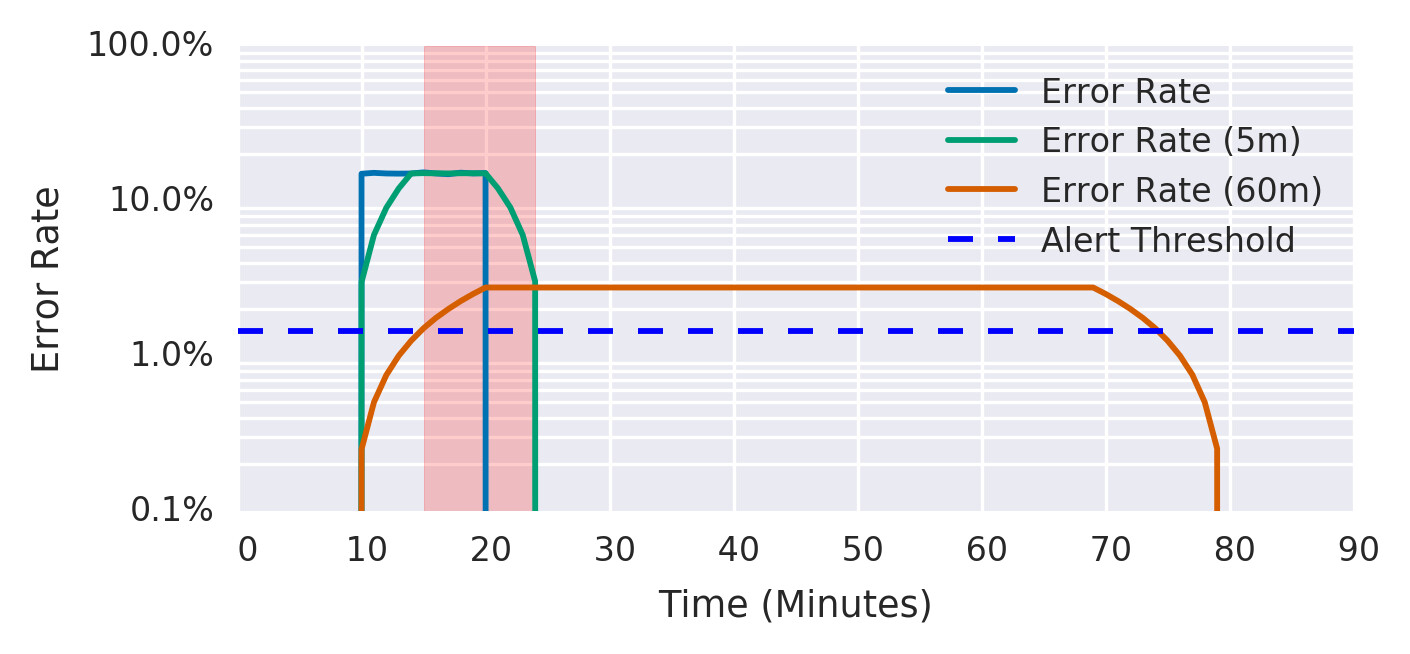
Figure 5.6: Short and long windows for alerting
上圖說明:經歷 15% 錯誤率 10 分鐘後,短窗口平均值立即超過閾值,長窗口平均值在 5 分鐘後超過閾值(此時告警觸發)。錯誤停止 5 分鐘後短窗口降到閾值以下(告警停止),而非等待長窗口的 60 分鐘。
推薦的告警參數起始點(以 99.9% SLO 為例):
| 嚴重程度 | 長窗口 | 短窗口 | Burn Rate | Error Budget 消耗 |
|---|---|---|---|---|
| Page | 1 小時 | 5 分鐘 | 14.4 | 2% |
| Page | 6 小時 | 30 分鐘 | 6 | 5% |
| Ticket | 3 天 | 6 小時 | 1 | 10% |
| 優點 | 缺點 |
|---|---|
| 彈性框架,可依事件嚴重程度和組織需求控制告警類型 | 參數眾多,告警規則可能難以管理 |
| 精確度佳 | |
| 因三天窗口而有良好的召回率 |
低流量服務的告警處理#
Multiwindow, multi-burn-rate 方法在高流量下效果良好,但低流量服務需要特別處理。例如:一個每小時只收到 10 個請求的系統,單一失敗請求就產生 10% 的小時錯誤率,對於 99.9% SLO 來說這是 1,000x burn rate,會立即觸發 page。
解決方案#
產生人工流量(Generating Artificial Traffic)
- 合成用戶活動以檢查潛在錯誤和高延遲請求
- 優點:提供更多信號,可重用現有監控邏輯和 SLO 值
- 缺點:只能合成一小部分用戶請求類型;若問題影響真實用戶但不影響人工流量,成功的人工請求會掩蓋真實信號
合併服務(Combining Services)
- 將多個低流量服務的請求組合成一個高層級群組
- 條件:服務必須有某種關聯性(同一產品的微服務,或同一 binary 處理的多種請求類型)
- 選擇有共同故障域(如共用的 backend 資料庫)的服務可提高效果
- 缺點:個別服務的完全故障可能不被視為顯著事件
變更服務與基礎設施
- 修改 client 端加入指數退避重試(exponential backoff with jitter)
- 設置 fallback 路徑捕獲請求以便最終執行
- 這些變更允許 error budget 中容納更多失敗事件,增加監控信號,並延長回應時間
降低 SLO 或增大時間窗口
- 若少量錯誤對 error budget 的影響不成比例,考慮與利害關係人協商降低 SLO(如從 99.9% 降到 99%)
- 缺點:涉及產品決策,影響系統行為預期和 error budget policy 的執行
實務上通常組合使用以上方法:盡可能產生假流量、修改 client 減少短暫故障的影響、聚合共享故障模式的小型服務、設定與失敗請求實際影響相稱的 SLO 閾值。
極端可用性目標#
極低可用性目標(如 90%)#
以 Table 5-8 的參數,100% 中斷在一小時內只消耗 1.4% budget,低於 2% 的 page 閾值,告警永遠不會觸發。需要調整告警參數。
極高可用性目標(如 99.999%)#
100% 中斷在 26 秒內就會耗盡所有 budget——這比許多監控服務的 metric 收集間隔還短。收到「只剩 26 秒 budget」的通知本身並非壞策略,但無法用來防禦 SLO。唯一的方法是從系統設計層面確保 100% 中斷的機率極低,例如先對 1% 的用戶進行 rollout,將 burn rate 降至 1%,從而獲得 43 分鐘的反應時間。
規模化告警(Alerting at Scale)#
當服務擴展時,告警策略也需要相應擴展。強烈建議不要為每個服務獨立指定告警窗口和 burn rate 參數。
請求類型分級(Request Class Buckets)#
將請求類型歸入相似可用性需求的群組:
| 請求類別 | Availability | Latency @ 90% | Latency @ 99% |
|---|---|---|---|
| CRITICAL | 99.99% | 100 ms | 200 ms |
| HIGH_FAST | 99.9% | 100 ms | 200 ms |
| HIGH_SLOW | 99.9% | 1,000 ms | 5,000 ms |
| LOW | 99% | None | None |
| NO_SLO | None | None | None |
- CRITICAL:最重要的請求類型,如用戶登入
- HIGH_FAST:高可用、低延遲的核心互動功能
- HIGH_SLOW:重要但對延遲較不敏感的功能(如產生歷史報表)
- LOW:需要一定可用性,但中斷對用戶幾乎不可見的功能
- NO_SLO:完全對用戶不可見的功能,如 dark launch 或 alpha 功能
這種分級提供足夠的保真度來保護用戶滿意度,同時比為每種請求類型設定獨特目標的方式更省力、更容易管理。
結論#
若你設定了有意義、可理解且以 metrics 表達的 SLO,就能設定告警僅在可操作的、針對 error budget 的具體威脅出現時通知 on-call 工程師。告警技術的演進從簡單的錯誤率閾值到多層級的 burn rate 和窗口大小,multiwindow, multi-burn-rate 告警技術在大多數情況下是防禦應用程式 SLO 最合適的方式。