本章探討 Google 如何管理監控系統,並為選擇與運行監控系統時可能遇到的問題提供指引。監控涵蓋多種資料類型,包括 metrics(指標)、文字日誌、結構化事件日誌、分散式追蹤和事件內省(event introspection),其中 metrics 和結構化日誌最適合 SRE 的基本監控需求。
監控的核心目的#
SRE 監控系統的五大用途:
- 告警:在需要關注的狀況發生時發出通知
- 調查與診斷:探究並診斷問題根因
- 視覺化呈現:以圖形化方式展示系統資訊
- 趨勢洞察:了解資源使用或服務健康度的長期趨勢,供容量規劃之用
- 變更比較:比較系統在變更前後的行為差異,或實驗中兩組的表現
監控策略的理想特性#
選擇監控系統時,應根據以下面向評估和取捨:
速度(Speed)#
- 資料新鮮度直接影響告警的反應速度;超過四到五分鐘的陳舊資料可能嚴重拖慢事件回應
- 在事件回應期間,若因果之間的時間差過長,可能導致錯誤的因果推斷
- 監控系統若能預先計算常見查詢的結果並建立新的 time series,可加速較慢的圖表載入
計算能力(Calculations)#
- 至少應支援數月級別的資料保留,以利長期趨勢分析和成長規劃
- 建議使用**單調遞增計數器(monotonically incrementing counters)**來記錄事件或資源消耗的指標,可據此計算時間窗口函數(如每秒請求率),並支撐 SLO burn-based alerting
- 支援統計函數如**百分位數(percentiles)**計算(第 50、95、99 百分位)比簡單的算術平均更有價值,因為平均值可能掩蓋不良行為
- 若系統不直接支援百分位數,可透過加總請求耗時再除以請求數取得平均值,或掃描日誌記錄來計算
介面(Interfaces)#
- 應支援多種圖表格式:heatmap、histogram、logarithmic scale 等
- 針對不同受眾(管理層 vs. SRE)提供不同的 dashboard 視圖
- 團隊應熟練進行即時的 ad hoc drill-down,在資料中切片、尋找相關性和模式
告警(Alerts)#
- 支援告警分類和不同嚴重等級:低頻錯誤可開 ticket 調查,100% 錯誤率則需要立即回應
- **告警抑制(alert suppression)**功能避免不必要的雜訊,例如:
- 所有節點出現相同高錯誤率時,只發送一次全域告警而非逐節點告警
- 當依賴服務已有告警時,不需要對自身服務的錯誤率重複告警
監控資料來源#
Metrics vs. Logs#
| 面向 | Metrics(指標) | Logs(日誌) |
|---|---|---|
| 粒度 | 較低粒度 | 高度精細 |
| 時效性 | 近即時 | 有固有延遲 |
| 主要用途 | 告警和 dashboard | 根因分析 |
| 資料準確性 | 較低(聚合後) | 較高(完整記錄) |
- Google 的告警和 dashboard 通常使用 metrics,因為近即時特性讓工程師能快速收到問題通知
- 使用 logs 來尋找問題的根因,因為所需資訊往往不以 metric 形式存在
- 即使需要基於特定事件告警,仍建議使用 metrics-based alerting(在事件發生時遞增計數器),保持所有告警設定在同一處
實務案例#
案例一:將資訊從 Logs 遷移到 Metrics
App Engine 團隊將 HTTP 狀態碼作為 metric label 匯出(如 requests_total{status=404})。由於 HTTP 狀態碼數量有限,不會造成不切實際的資料量膨脹,卻能讓圖表顯示不同錯誤類別的獨立趨勢線,並為 client error 和 server error 設定不同告警閾值。
案例二:同時改善 Logs 和 Metrics
一個 Ads SRE 團隊維護約 50 個服務,各使用不同語言和框架。他們建立了一個共用函式庫,在請求處理時判斷錯誤是否影響用戶,同時寫入 logs 並匯出 metric,確保一致性。結果:跨服務統一了工具和告警邏輯,告警直接綁定 SLO 後,可操作性提高,false-positive 率大幅下降。
案例三:保留 Logs 作為資料來源
當實體 ID 可能有數百萬種不同值時,不適合作為 metric label。團隊改為撰寫腳本執行一次性日誌查詢,並將腳本指令記錄在告警郵件中,減少認知負擔並加速問題調查。
管理你的監控系統#
將設定視為程式碼#
- 強烈建議將監控設定納入版本控制系統,享有變更歷史、回滾能力、linting 檢查和程式碼審查流程
- 偏好**意圖導向(intent-based)**的設定方式,而非僅提供 Web UI 或 CRUD-style API 的系統
- 開源工具如 grafanalib 可為傳統透過 UI 設定的元件啟用此模式
鼓勵一致性#
- Google 的做法已趨向收斂至單一集中式框架:工程師轉換團隊時能更快上手,跨團隊除錯協作更容易
- 若所有服務匯出一致的基本 metrics 集合,可自動收集並提供統一的 dashboard,新上線的元件自動具備基本監控
偏好鬆耦合#
- 監控系統各元件(收集、儲存、告警、視覺化)應透過穩定介面連接,方便替換
- 現代設計趨勢:將功能分拆為獨立元件(如 Prometheus server + InfluxDB + Alertmanager + Grafana),而非像舊式 Zabbix 將所有功能合併
- 兩大開放標準:statsd(Etsy 開發的 metric 聚合 daemon)和 Prometheus(彈性資料模型、支援 metric labels 和 histogram)
- Google 實際經驗:將 dashboarding 從監控系統中獨立出來(Viceroy),使新舊監控系統(Borgmon → Monarch)的遷移更加順暢
有目的的指標(Metrics with Purpose)#
SLI metrics 是 SLO-based alert 觸發時首要檢查的指標,應顯著出現在服務 dashboard 的首頁。但 SLO dashboard 只顯示「正在違反 SLO」,不一定顯示原因。以下是額外應監控的面向:
預期變更(Intended Changes)#
當診斷 SLO-based alert 時,需要能從告警指標追溯到造成問題的原因。建議監控:
- Binary 版本
- 命令列旗標(command-line flags),特別是用於啟停功能的旗標
- 動態設定的版本(若設定資料是動態推送的)
- 若系統未版本化,至少監控最後建置或打包的時間戳
將這些資訊以圖表/dashboard 的形式連結到告警中,比事後翻找 CI/CD 系統日誌來嘗試關聯 outage 與 rollout 容易得多。
依賴項(Dependencies)#
- 監控所有直接依賴的回應:request/response 大小(bytes)、延遲、回應碼
- 遵循四大黃金信號(four golden signals),以額外 labels 細分(response code、RPC method name、peer job name)
- 理想做法:在底層 RPC client library 層級一次性 instrument,確保一致性並自動覆蓋新依賴
- 對於使用單一不透明 API(如只有
Get或Query)的關鍵依賴,需匯出額外專門的 metrics 或請依賴方重寫為更細粒度的 API
飽和度(Saturation)#
監控服務依賴的每一項資源的使用狀況:
- 硬性限制:RAM、磁碟、CPU quota
- 軟性限制:open file descriptors、thread pool 中的活動執行緒數、佇列等待時間、日誌寫入量
- 語言特定資源:Java 的 heap 和 metaspace 大小、Go 的 goroutine 數量
- 當接近資源耗盡或跨越使用閾值導致效能降級時,設定告警
服務流量狀態(Status of Served Traffic)#
- 以 metric labels 細分所有回應碼,包括不足以觸發告警但由錯誤客戶端行為引起的狀態碼
- 若有 rate limit 或 quota limit,監控因配額不足被拒絕的請求聚合數
實作有意義的指標#
- 每個匯出的 metric 都應有明確目的,抵制「因為容易產生就匯出」的誘惑
- 告警用指標:在系統正常時穩定不變,進入問題狀態時劇烈變化
- 除錯用指標:提供問題發生時的深入洞察,指向可能造成問題的系統面向
- 撰寫 postmortem 時,思考哪些額外指標能更快診斷問題
測試告警邏輯#
監控和告警程式碼應接受與一般程式碼開發相同的測試標準。Google 使用 domain-specific language 建立合成 time series 並撰寫斷言來測試。
建議採用三層測試方法:
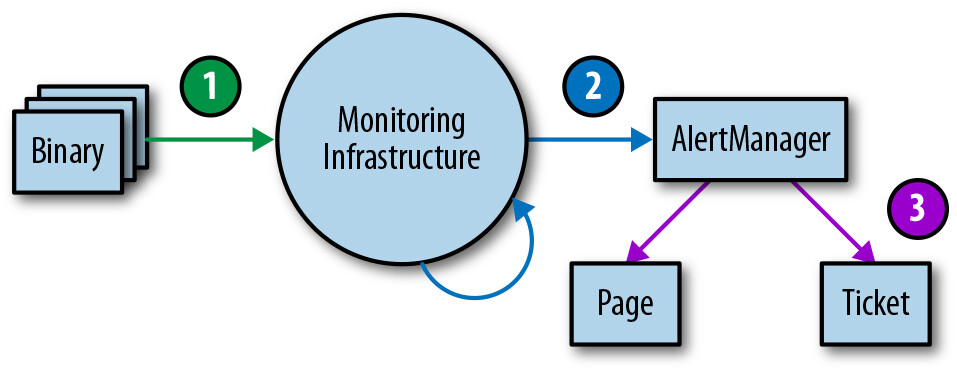
Figure 4.1: Monitoring testing environment tiers
- Binary reporting 測試:驗證匯出的 metric 變數在特定條件下如預期變化
- Monitoring configurations 測試:確保規則評估產生預期結果,特定條件產生預期告警
- Alerting configurations 測試:測試生成的告警根據 label 值被路由到預定目的地
告警規則很可能在設定後數月甚至數年不會觸發。你需要有信心,當 metric 超過某個閾值時,正確的工程師會收到有意義的通知。若無法透過合成方式測試,可建立一個匯出已知 metrics 的運行系統來驗證。
結論#
SRE 必須深入熟悉服務的監控系統及其功能。建議結合 metrics 和 logging 來建構監控策略,確保收集的每個 metric 都有特定用途——無論是容量規劃、輔助除錯或直接通知問題。監控系統建置完成後,需確保其可見且實用,並投資測試你的監控設定。一個好的監控系統值得投入大量思考來選擇最佳方案,並持續迭代直到做對為止。