本章由 Steven Thurgood 和 David Ferguson 撰寫,是全書最重要的章節之一。SLO (Service Level Objectives) 是 SRE 實踐的核心,為可靠性決策提供資料驅動的框架。本章提供了從零開始建立 SLO 的完整步驟指南,並涵蓋如何利用 SLO 做出有效的商業決策。
為什麼 SRE 需要 SLO#
工程師是稀缺資源,工程時間應投入在最重要服務的最關鍵特性上。在贏得新客戶的功能開發與維持客戶滿意的可靠性之間取得平衡非常困難。精心制定並被採納的 SLO 是做出可靠性工作機會成本相關資料化決策的關鍵。
- SRE 的日常任務和專案由 SLO 驅動:確保短期內 SLO 得到保障,中長期內能夠維持
- 沒有 SLO,就沒有 SRE 的存在必要
- SLO 是決定工程工作優先順序的工具
入門指南#
可靠性目標與 Error Budgets#
SLO 為服務客戶設定目標可靠性水平。高於此門檻,幾乎所有使用者都會滿意;低於此門檻,使用者可能開始抱怨或停止使用服務。100% 可靠性是錯誤的目標,原因包括:
- 即使有冗餘組件和快速故障轉移,仍有非零的同時失敗機率
- 客戶不會體驗到 100% 可靠性,因為你與客戶之間有很長的系統鏈
- 維持 100% 可靠性意味著永遠無法更新或改善服務
- 100% 的 SLO 意味著只能被動反應,而非主動工程改善
一旦有了低於 100% 的 SLO 目標,就需要由組織中有權在功能速度與可靠性之間做權衡的人來擁有它。在小型組織中可能是 CTO,在大型組織中通常是產品負責人。
該測量什麼:使用 SLI#
SLI (Service Level Indicator) 是服務等級的指標。建議將 SLI 視為兩個數字的比率:
SLI = 好事件數 / 總事件數
例如:
- 成功 HTTP 請求數 / 總 HTTP 請求數(成功率)
- 在 100ms 內完成的 gRPC 呼叫數 / 總 gRPC 請求數
- 使用完整語料庫的搜尋結果數 / 總搜尋結果數
這種形式的 SLI 範圍從 0% 到 100%,直覺且易於理解。Error budget 就是 100% 減去 SLO。
SLI 可進一步分為:
- SLI 規格 (Specification):你認為對使用者重要的服務結果評估,與測量方式無關
- SLI 實作 (Implementation):SLI 規格加上測量方式
組件類型與對應的 SLI#
不同類型的服務組件有不同的建議 SLI:
- 請求驅動型 (Request-driven):可用性(成功回應比例)、延遲(快於某門檻的請求比例)、品質(在未降級狀態下提供的回應比例)
- Pipeline 型:新鮮度 (Freshness)、正確性 (Correctness)、覆蓋率 (Coverage)
- 儲存型 (Storage):耐久性 (Durability)——寫入的記錄能成功讀取的比例
實作範例#
本章以一個手機遊戲的簡化架構為例,展示如何從頭建立 SLO。
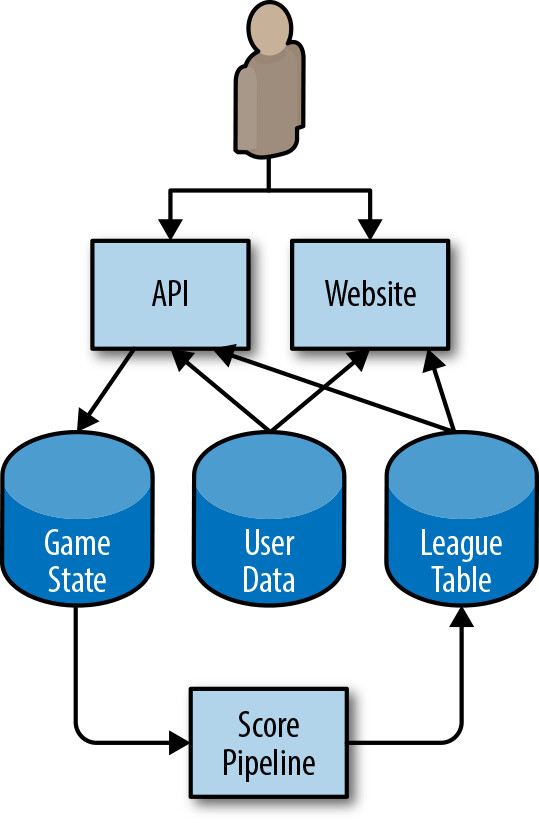
Figure 2.1: 手機遊戲範例架構
該架構包含:手機 App 透過 HTTP API 與雲端互動,API 將狀態變更寫入永久儲存,Pipeline 定期處理資料生成排行榜,結果可透過 App 和網站存取。
SLI 實作選項#
- API 與 HTTP 伺服器的可用性和延遲:以 HTTP 狀態碼為基礎,5XX 回應計入 SLO 違規。範例使用負載平衡器監控,因為指標已可用且更接近使用者體驗
- Pipeline 的新鮮度、覆蓋率和正確性:透過客戶端實作追蹤資料新鮮度,透過 pipeline 匯出的記錄數計算覆蓋率,透過手動維護的測試資料驗證正確性
測量 SLI#
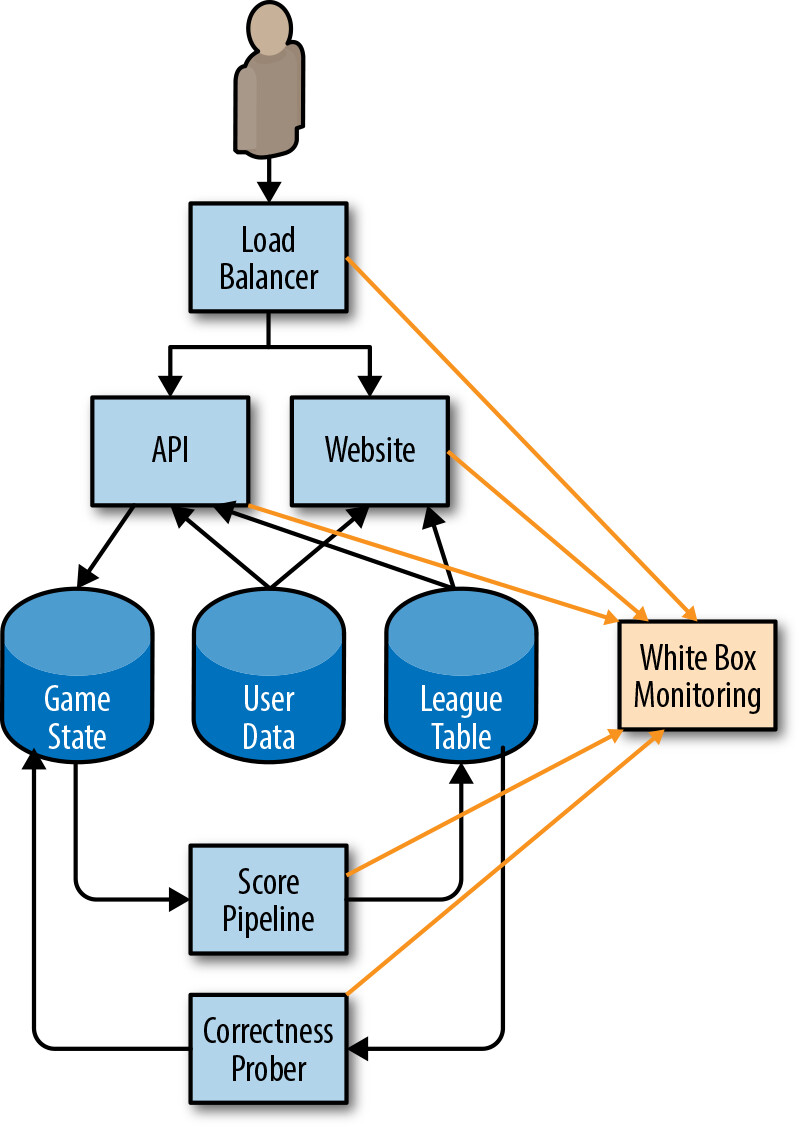
Figure 2.2: 監控系統如何收集 SLI 指標
使用白盒監控系統從應用程式的各組件收集指標。以 Prometheus 表示法為例:
- 依後端和回應碼分類的總請求數:
http_requests_total{host="api", status="500"} - 累積直方圖形式的總延遲:
http_request_duration_seconds{host="api", le="0.1"}
從 SLI 計算入門級 SLO#
將 SLI 向下取整到可管理的數字,即可得到入門 SLO。例如四週 API 指標顯示:
- 總請求:3,663,253
- 成功請求:3,557,865(97.123%)
- 90th 百分位延遲:432 ms
- 99th 百分位延遲:891 ms
取整後的 SLO 提案為:可用性 97%、90% 請求 < 450ms、99% 請求 < 900ms。
對應的 error budget(四週):可用性允許 109,897 次失敗、90% 延遲允許 366,325 次、99% 延遲允許 36,632 次。
選擇適當的時間窗口#
- 滾動窗口 (Rolling window):更貼近使用者體驗,建議使用整數週數避免週末流量差異
- 日曆窗口 (Calendar window):更貼合業務規劃和專案工作,但中途無法確定季度剩餘的 error budget
- 較短窗口:允許更快做出決策(如每週)
- 較長窗口:適合更策略性的決策(如季度)
四週滾動窗口是良好的通用區間,搭配每週摘要進行任務優先排序,以及每季彙總報告進行專案規劃。
取得利害關係人同意#
SLO 要有用且有效,需要所有利害關係人同意:
- 產品經理:同意此門檻對使用者足夠好,低於此值時值得投入工程時間修復
- 產品開發者:同意當 error budget 耗盡時,會採取措施降低使用者風險
- 營運團隊:同意 SLO 在正常情況下可以防禦,不會造成過度勞累和倦怠
建立 Error Budget Policy#
Error budget policy 定義了當服務耗盡預算時應採取的行動。常見的擁有者和行動包括:
- 開發團隊將可靠性相關的錯誤列為最高優先級
- 開發團隊專注於可靠性問題直到系統回到 SLO 內
- 實施生產凍結 (production freeze),暫停對系統的某些變更
如果三方(產品經理、開發團隊、SRE)未能就 error budget policy 達成一致,就需要反覆迭代 SLI 和 SLO 直到所有利害關係人都滿意。
文件化與儀表板#
SLO 文件#
應記錄在顯眼位置,包含:作者、審查者和批准者、批准日期和下次審查日期、服務簡述、SLO 目標細節和 SLI 實作、error budget 計算方式、數字背後的理由。
報告與儀表板#
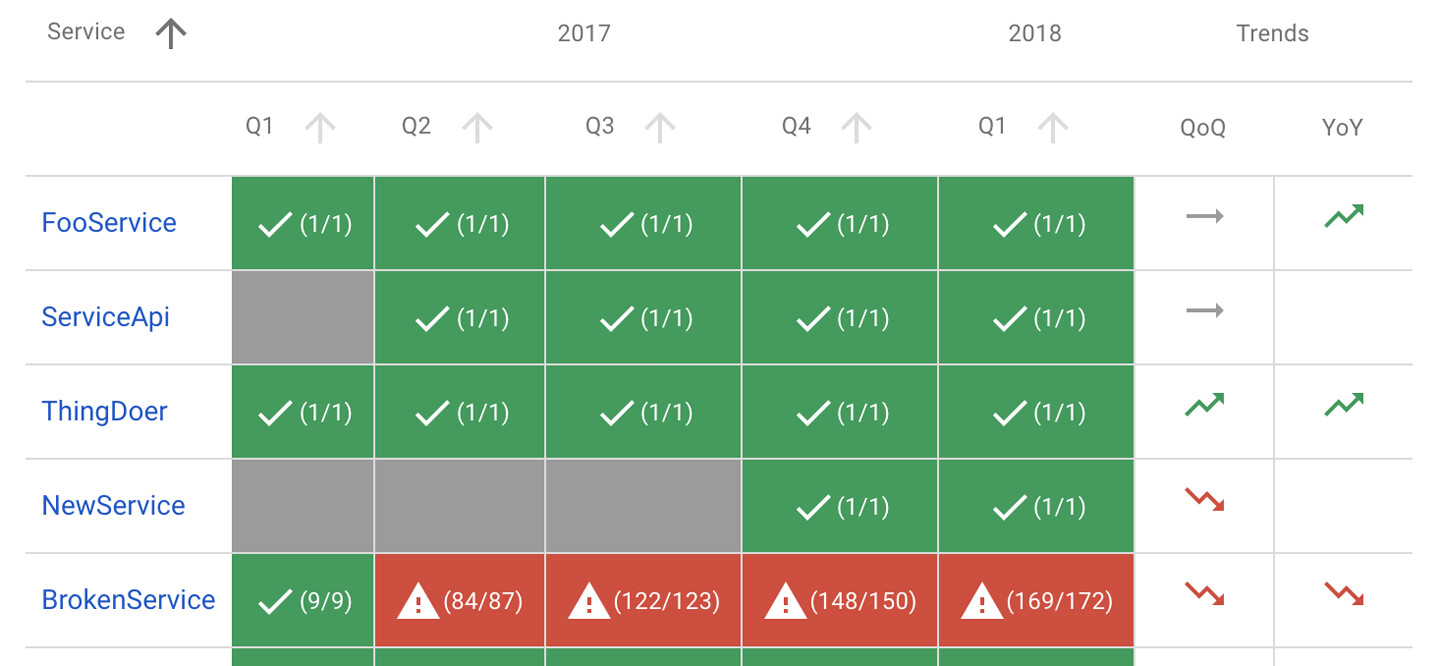
Figure 2.3: SLO 合規報告
合規報告顯示多個服務的整體 SLO 達成情況,以及 SLI 的趨勢方向。
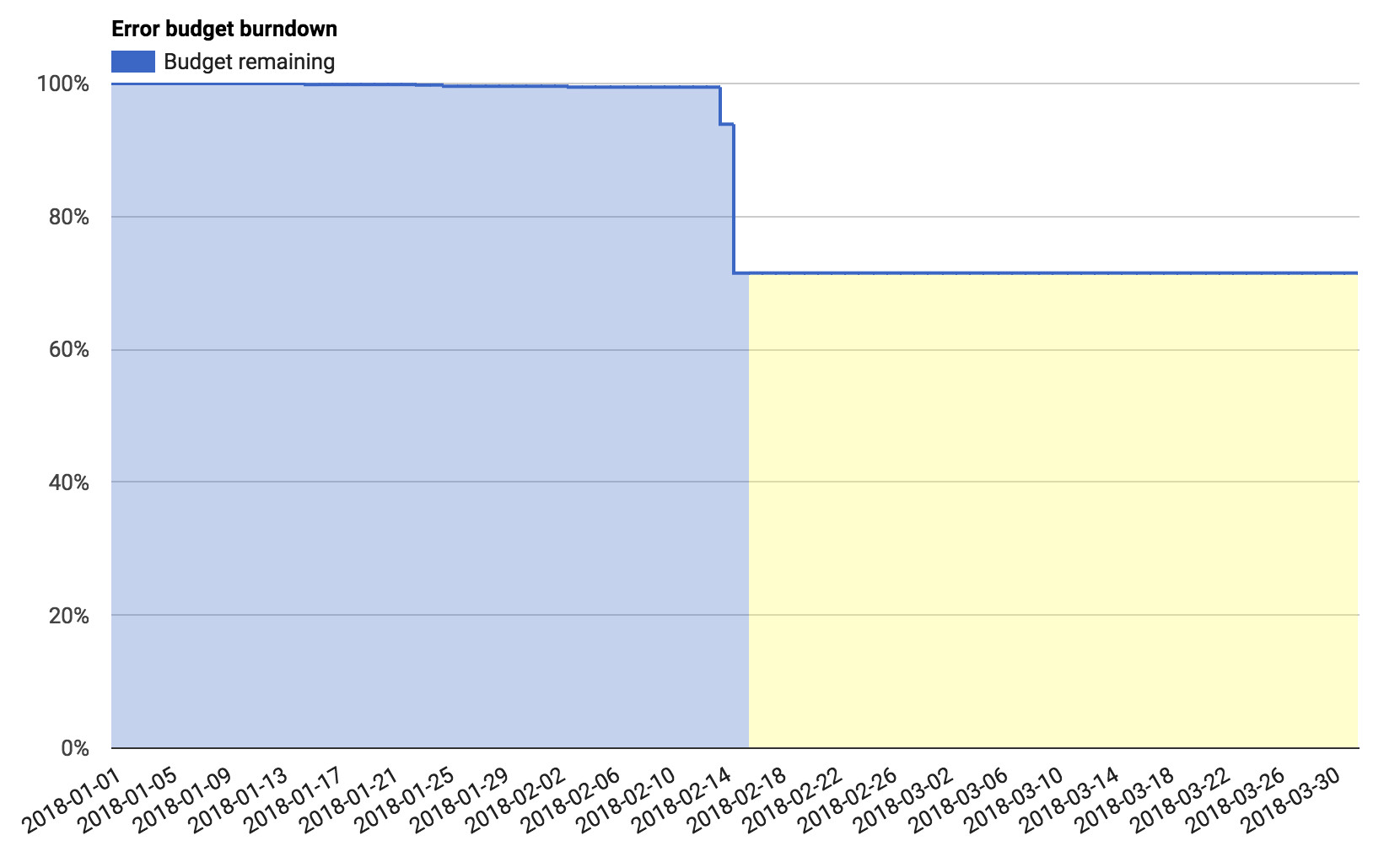
Figure 2.4: Error budget 儀表板
Error budget 儀表板顯示單一季度的 error budget 消耗情況,可用於量化事件的影響。
持續改善 SLO 目標#
改善 SLO 目標前,需要使用者滿意度的資訊來源:手動發現的故障計數、社群媒體情緒、使用者調查等。
改善 SLO 品質的方法#
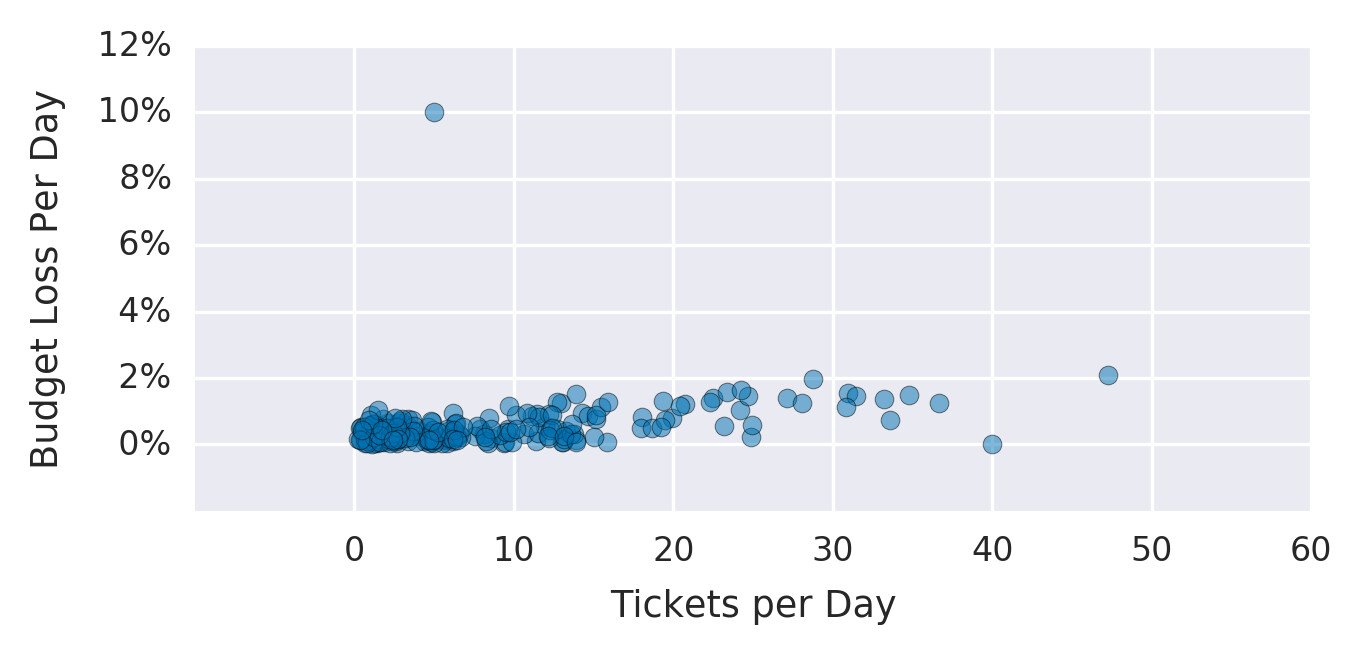
Figure 2.5: 每日支援票數與 error budget 損失的關係圖
將已知故障與 error budget 的陡降進行關聯分析。如果某些故障未被任何 SLI 或 SLO 捕捉,或者 SLI 下降與 SLO 未達標沒有對應到使用者影響,這表明 SLO 的覆蓋率不足。可採取的行動:
- 修改 SLO:收緊或放寬,減少漏報或誤報
- 修改 SLI 實作:將測量點移近使用者以提高品質,或改善覆蓋率以捕捉更多互動
- 設立期望性 SLO (Aspirational SLO):需要更嚴格的 SLO 但產品尚未達標時,可追蹤但明確排除在 error budget policy 之外
- 迭代:選擇投資報酬率最高的改善,特別是初期偏向更快更便宜的方案
使用 SLO 和 Error Budgets 做決策#
當 error budget 耗盡時:
- 依 error budget policy 採取行動(如停止功能發布、專注可靠性問題)
- 極端情況下可宣布緊急狀態,以高層批准的方式降低所有外部需求的優先級
- 依 error budget 消耗比例判斷事件規模,識別最需要深入調查的關鍵事件
SLO 決策矩陣根據三個維度提供建議行動:
| SLO 狀態 | Toil 程度 | 客戶滿意度 | 建議行動 |
|---|---|---|---|
| 達成 | 低 | 高 | 放寬發布流程提升速度,或退出支援專注其他服務 |
| 達成 | 低 | 低 | 收緊 SLO |
| 達成 | 高 | 高 | 降低告警敏感度,或暫時放寬 SLO 並修復產品 |
| 達成 | 高 | 低 | 收緊 SLO |
| 未達成 | 低 | 高 | 放寬 SLO |
| 未達成 | 低 | 低 | 提高告警敏感度 |
| 未達成 | 高 | 高 | 放寬 SLO |
| 未達成 | 高 | 低 | 卸載 toil 並修復產品和/或改善自動化故障緩解 |
進階主題#
建模使用者旅程 (User Journeys)#
SLO 最終應以使用者為中心。關鍵使用者旅程 (Critical User Journey) 是使用者體驗的核心任務序列。例如線上購物的關鍵旅程包括:搜尋產品、加入購物車、完成購買。這些任務通常無法直接對應到現有 SLI,但識別出使用者關心的事情後,就可以解決測量問題。
互動重要性分級 (Grading Interaction Importance)#
不是所有請求都同等重要。可使用分桶 (Bucketing) 為 SLI 添加標籤,並對不同標籤套用不同 SLO。例如:Premium 客戶 99.99% 可用性、Free 客戶 99.9% 可用性。也可按預期回應速度分桶。
建模依賴關係 (Modeling Dependencies)#
- 關鍵依賴的可靠性保證應至少與依賴方相同
- 如果組件有固有的可靠性限制,需要透過工程手段(快取、離線處理、優雅降級等)來處理
- 不要假設多區域部署能簡單地透過機率計算來提供更高可用性——共同依賴、共同故障域和全域控制平面會使計算具有欺騙性
關於依賴團隊造成的 SLO 未達標,有兩種思路:(1) 不因非自身系統造成的問題而停止發布,(2) 無論原因都實施變更凍結以最小化未來故障風險。第二種方法會讓使用者更開心。
實驗性放寬 SLO#
可以實驗性地降低應用程式的可靠性(如增加頁面載入延遲),測量哪些可靠性變化對使用者行為有可測量的負面影響。但這應在確定有 error budget 可以消耗時才進行,且需謹慎解讀資料——使用者可能不滿意但暫時缺乏替代品。
結論#
本書涵蓋的每個主題都可以追溯到 SLO。即使是部分形式化的 SLO,也能提供一個更清晰地討論系統行為的框架,並在服務未達預期時幫助找出可行的補救措施。
- SLO 是測量服務可靠性的工具
- Error budgets 是平衡可靠性與其他工程工作的工具,也是決定哪些專案影響最大的好方法
- 你應該今天就開始使用 SLO 和 error budgets