SRE 在 Google 的組織位置很特殊——
- 種類多樣:基建團隊、服務團隊、橫向產品團隊
- 與產品團隊的相對規模從遠大、相當、到自己就是產品團隊都有
- 成員背景跨越系統工程、軟體工程、PM、領導力、不同產業
- 不是 command-and-control 組織:服務 / 基建 SRE 通常「侍奉兩個主人」——產品團隊與整個 SRE
文化與共享價值產生強烈一致的問題解法,這是有意設計的。
生產會議(Production Meetings)#
一種特別有用的會:以「服務」為中心、由 SRE 主持、討論該服務的所有面向,目的是讓彼此知道目前重要的事。
生產會議的兩個主要目的:
- 在 SRE 隊內、跨團隊間共享狀態
- 透過引入產品團隊與其他利害關係人來改善服務
主持與參會#
- 通常 SRE 內部輪流主持
- 跨地點時兩邊都安排主持人(小 / 弱勢一方有平等發聲)
- 強制 SRE 出席;產品團隊、PM、stakeholder 應出席
- 太多人時可:分頻、分群、輪流
建議議程#
- 即將到來的生產變更:版本、設定、容量、實驗
- 故障:每件 page 與非 page 事件均需檢視
- 沒 page 的事件:可能是「監控漏」或「應變不需要 page」的好案例
- 遠期生產主題
文件#
把 meeting agenda 與紀錄寫進共享文件——好處:
- 下次會議的議程是上次紀錄的延伸
- 多人並行協作(多游標、評論)讓會議更高效
SRE 內部協作#
Google 全球分散,各地團隊也因此分散。SRE 團隊組織傾向:
- 核心專家彼此就近(多人專案多在同一座辦公室)
- 「follow the sun」On-Call 採跨地點輪值
- 跨地點專案需要更高的成本(溝通延遲)但有更高的吞吐潛能
角色#
- Tech Lead(TL):技術方向
- SRE Manager(SRM):團隊管理
- Technical Program Manager(TPM):跨團隊計畫管理
偉大的 TL/SRM/TPM 能跨角色協作——這也是 SRE 重視能力多元的具體展現。
有效協作的原則#
- 單兵專案多半失敗(除非天才或問題簡單)
- 跨時區需要:優秀書面溝通 或頻繁出差,否則「久而久之你只剩下一個 email 地址」
- 不能避免實體碰面——團隊 summit 在中立地點舉辦能避免「主場優勢」
案例:Viceroy 監控儀表板#
多年來 SRE 各團隊重複造輪:每隊都被獎勵自製,跨隊合作難,整體 SRE 提供的多是工具包而非產品——導致一片燒毀的監控框架殘骸。
2012 年 Monarch 新監控系統推出後仍缺好用的 console——多個團隊各自啟動專案(含 Consoles++)。直到工程師發現彼此後合併為 Viceroy。
初期 Viceroy(少 JS)與 Consoles++(多 JS)技術差異大,未能立刻合併。一年後 Viceroy 開始用 JS 畫圖、Consoles++ 轉而從 Viceroy 取資料 → 2014 年完成整合,被 SRE 推薦為通用方案(推薦而非強制)。
學到的事#
- 跨地點協作的早期常因書面溝通與口語暗示的誤解遇到困難
- 「Casual contributor」貢獻有用但也稀釋擁有權——人走了功能就被棄置
- 範圍會自然擴大——需強化專案管理避免失焦
- 遠端擁有的元件總會被「就近討論、就近決策」侵蝕
推薦#
- 必要時才跨地點協作——成本高但回報也高
- 確認貢獻者是「真有目標」而非為履歷上一筆而來
- 重視 leader:定方向、保持優先序、約定決策方式(最好能就地決策)
- 「Divide and conquer」:拆成小元件,盡量讓每元件由單一站點負責;但警惕 Conway’s law——別讓組織結構扭曲軟體結構
- 為元件寫設計文件 + review,留下書面紀錄
- 設定 coding standard 與決策規則:辯論可有但要有時限;達不到共識請仲裁、寫下、繼續走
- 不能完全取代面對面——VC + 良好書寫可部分延後,但 leader 與全員見面一次極為值得
- 專案管理風格隨成長調整:大專案不需從第一天就重磅治理
SRE 與外部協作#
SRE 與產品團隊最佳的協作時點是設計階段、第一行 code 前。
SRE 對架構與軟體行為的建議在事後幾乎無法 retrofit——所以「設計會議裡有 SRE」對所有人都好。
協作用 OKR 流程追蹤。對部分 service team 而言,「跟新設計、提建議、協助實作、看它上線」就是日常。
案例:DFP 從 MySQL 遷到 F1#
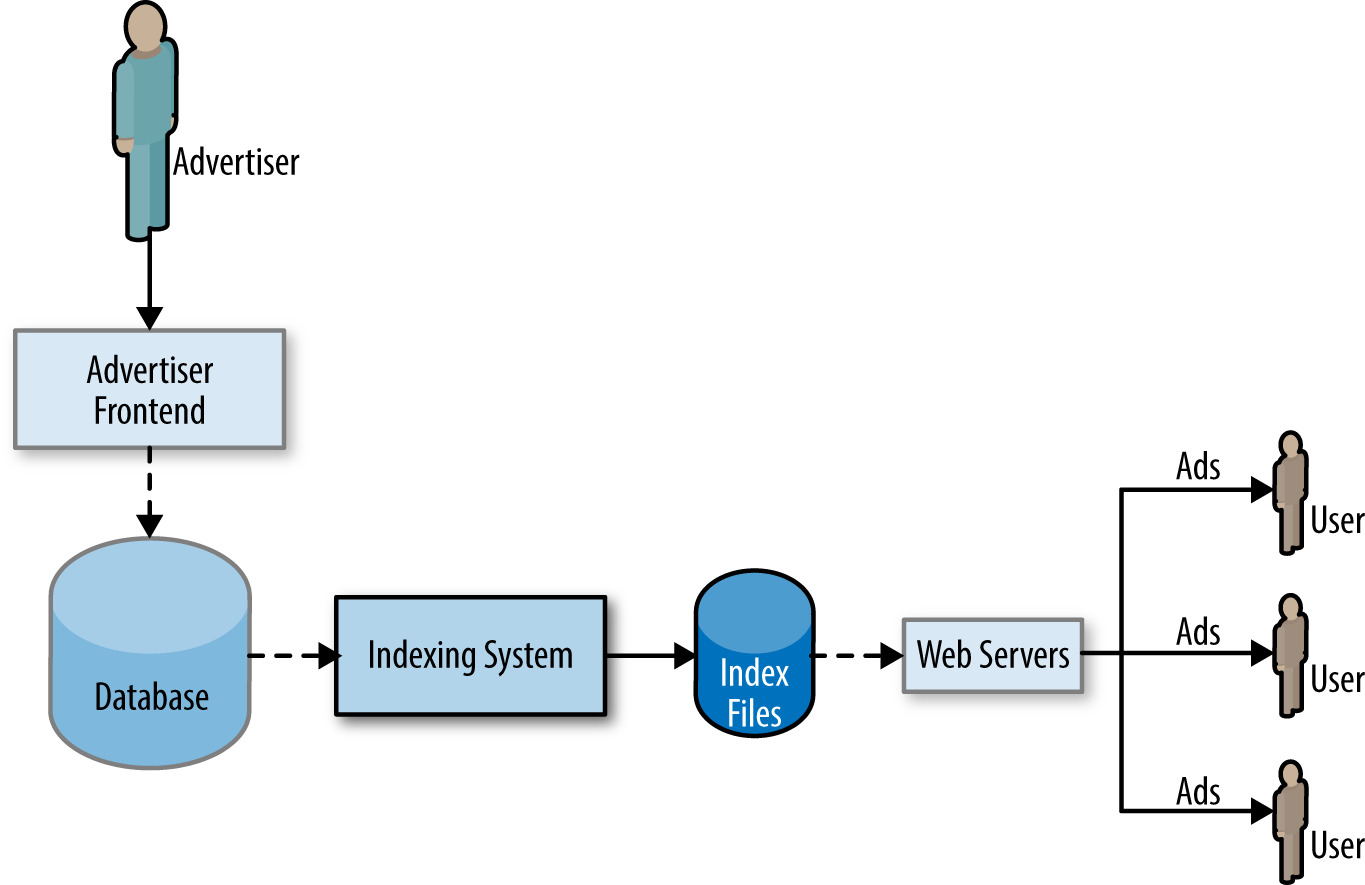
Figure 31.1: 通用廣告服務系統
DoubleClick for Publishers 的主要 DB 從 MySQL 換到 F1:
- 約 1,000 CPU、8 TB RAM,每日索引 100 TB 資料
- 必須零中斷遷移
- DB schema 因 F1 能存 protobuf 而大幅簡化
協作模式:
- 每週 SRE × 產品團隊同步會
- SRE 主導基建設計:表抽取、過濾、join、增量抽取、機器故障容忍、資源線性增長、容量規劃
- 詳細設計文件由 SRE 撰寫,兩邊充分 review
- 識別出 BL 必須的變更
- 嚴格遵守 SRE 標準:監控、自動化、災難演練、容量規劃
這個案例展示了 SRE 與產品團隊深度協作而非「丟過牆」的價值——大型遷移可以零中斷完成。
結語#
SRE 的協作不是 silver bullet——它依靠:
- 規律的生產會議
- 跨地點時的書面紀律與面對面投資
- 早期介入產品設計
- 跨團隊整合而非各自為政
- 對共享價值的承諾