「資料完整性」是什麼?以使用者為先時,使用者覺得它是什麼,它就是什麼。
即使資料根本沒丟,Gmail 的 UI bug 讓信箱長時間空白,使用者就會「相信資料丟了」——Google 守護資料的能力與雲端可信度雙雙受損。
「太久」的尺度:Gmail 2011 年事件顯示 4 天太久;24 小時是 Google Apps 對外承諾的起點。
嚴格的需求#
99.99% uptime → 一年僅約 1 小時 downtime;99.99% 「good bytes」於 2 GB artifact → 高達 200 KB 損壞 → 執行檔變垃圾、資料庫無法載入。
每個服務都有獨立的 uptime 與資料完整性需求。最差的時機就是在使用者資料消失後才去釐清這些需求。
資料完整性的真正定義:服務於雲端對使用者保持可訪問,且資料形態完好。
通往「卓越資料完整性」的祕訣是主動偵測 + 快速修復與復原。
雲端應用的取捨#
雲端應用需在以下五者間取捨:
- Uptime(可用度)
- Latency(延遲)
- Scale(規模)
- Velocity(速度):能多快創新提供更高價值
- Privacy(隱私):使用者刪除資料後須在合理時間內銷毀
ACID 與 BASE API 混合使用——BASE 換來更高可用度,但僅承諾「最終一致」。
高速度文化下,應用常混合多個資料儲存(Blobstore 存 BLOB + Megastore 存權威 metadata + Bigtable + client-side cache)→ 跨儲存的 referential integrity 成為運維挑戰。
備份 vs. 封存#
沒人真的想要備份;大家想要的是還原。
- 備份:能被應用載回——支援災難復原(disaster recovery)
- 封存:用於審計、合規——可能花一週才取回,但這是可接受的
關鍵差別決定排程:
- 備份應頻繁(小時、甚至連續串流)
- 封存可以是每月一次
Google SRE 的目標:資料可用度才是目的#
「資料完整性」是手段,「資料可用度」才是目標。
即使資料完好,若使用者長時間取不到,從使用者視角等於資料根本不存在。
不要強迫團隊「演練備份」——而是:
- 為各種故障模式定義資料可用度 SLO
- 演練並證明可達標
24 種失敗模式#
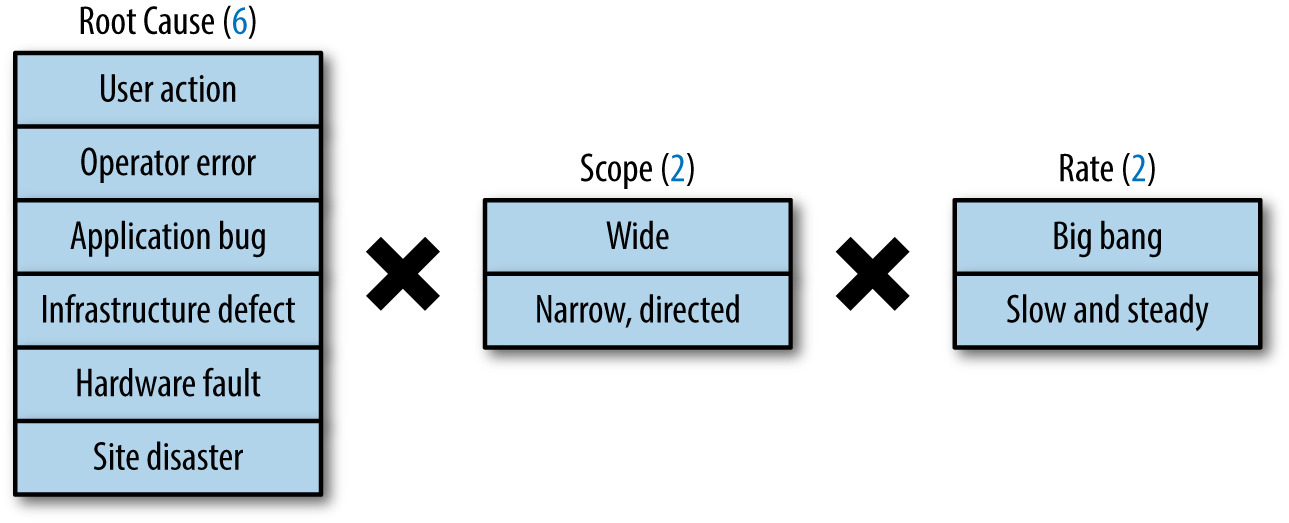
Figure 26.1: 資料完整性失敗模式的三個維度
資料完整性故障的三個維度組合出 24 種模式:
- 根因:使用者操作、運維者錯誤、應用程式 bug、基建瑕疵、硬體故障、機房災難
- 範圍:廣(多數實體)vs. 窄(少數)
- 速率:瞬時大事件(1M 行被 10 行取代)vs. 緩慢侵蝕(每分鐘消失 10 行,持續數週)
Google 19 起資料復原案例研究:最常見的是軟體 bug 造成的資料刪除或 referential integrity 損失,最棘手的是數週至數月後才被發現的低速侵蝕。
Point-in-time Recovery(時光旅行)#
復原時可能要從不同時點為不同使用者復原。point-in-time recovery + 跨 ACID/BASE 儲存 + 滿足 uptime、延遲、規模、速度、成本 在當前是「神獸級」目標。
實務上採分層備份:
- 昂貴的本地 snapshot(時間間隔幾小時,保留幾天)
- 完整與增量複本(每 1–2 天)保留更久
副本不是復原#
「我們有比備份更好的東西——副本!」是錯的。
副本提供地理性與站點容災,但錯誤刪除與資料毀損會立刻被推到所有副本。
三層防護策略#
Google 的資料完整性方案結合三層:
第一層:軟刪除(Soft Deletion)#
任何尊重隱私的產品都須讓使用者刪除自己的資料——但意外刪除(使用者誤刪、帳號被劫持)是消費型產品最大宗的資料災難。
解法:「軟刪除」——
- 刪除後保留可逆時間窗(如 30 天)
- 期間允許 undelete
- 期滿才真正硬刪

Figure 26.2: 物件從軟刪除到銷毀的歷程
對開發者也可考慮提供「自訂軟刪除時長」「垃圾桶」「程式化還原 API」。
第二層:備份及其復原方法#
關鍵問題不是「我們備份了沒?」而是「我們是否能在使用者要求的 RPO / RTO 內復原?」
設計上的取捨:
- 備份頻率
- 還原機制(增量 vs. 完整)
- 儲存層級(本地、近線、離線)
大規模備份的常見技術:將備份本身視為一個高吞吐 pipeline——水平切分到許多 worker,並用垂直切片限制單次工作的範圍。可同時 backup 與 verify。
第三層:早期偵測#
真正可怕的是「資料壞掉幾個月才發現」——此時最早的備份可能已經過期、檔案系統的歷史也沒了。
解法:離線驗證管線,持續地:
- 比對跨資料儲存的 referential integrity
- 檢查 schema invariant
- 抽樣驗證資料正確性
Compute Storage 等服務為「驗證 metadata」設計了大型的並行任務。
知道你的復原機制會成功#
「我們有備份」不是「我們可以還原」。
唯一可靠的證據是定期演練還原:
- 把復原步驟自動化
- 在實機上跑全套還原
- 每次發現 bug 都修,並把驗證加進演練
案例:Gmail 大規模資料復原(2011 年)#
軟體 bug 讓部分 Gmail 帳號的訊息與設定被刪。復原靠的是「Defense in Depth」——多層防護同時上場:
- 線上副本(無法救——壞資料已同步)
- 本地 snapshot
- 離線磁帶備份(最後的救命稻草)
公開承認資料復原靠磁帶讓使用者反而更安心——「Google 有真正的離線備份」。
案例:Google Music 的 Big Bang 資料損失#
一支自動化清理工具誤刪了大量音樂檔案。發現後:
- 評估損失範圍
- 並行從多個離線備份還原
- 修補資料 graph 的 referential integrity
- 把根因(清理工具的決策邏輯)修掉
SRE 通則在資料完整性上的應用#
- 信任但驗證:副本與備份都要主動驗證
- 希望不是策略:演練、演練、演練
- Defense in Depth:多層保護,假設每層都會有破口
- 重視復原時間(RTO)與恢復點(RPO)目標
最簡單的 SRE 信條:「讀到的,就是寫進去的」——
透過主動偵測、軟刪除、備份/復原、與早期驗證的層層防護,把使用者資料的承諾守住。