本章談大規模、深層資料處理管線的真實挑戰:從週期性管線到連續性管線,以及在分散式環境中可能引發的「驚群」「擺紋負載」等運維災難——並介紹 Google 用 Workflow(leader-follower + system prevalence)取代週期性管線的設計。
管線設計模式的源起#
經典做法:寫一支程式讀資料、轉換、輸出;由 cron 週期排程。
隨 Big Data 興起變成「多階段管線」——前一程式的輸出餵給下一程式。連起來的程式數稱為「管線深度」,深者可達數十至上百個程式。
週期性管線的問題#
不均工作分配#
「Embarrassingly parallel」演算法把 workload 切成小塊;但若塊間資源需求差異大,整體執行時間會被「最大客戶」拖累。
「Hanging chunk」問題:某 chunk 卡住 → 引擎或人類本能反應是「kill & restart」→ 但週期性管線沒 checkpoint → 所有 chunk 從頭跑,浪費前一輪的全部投入。
在分散式環境的劣勢#
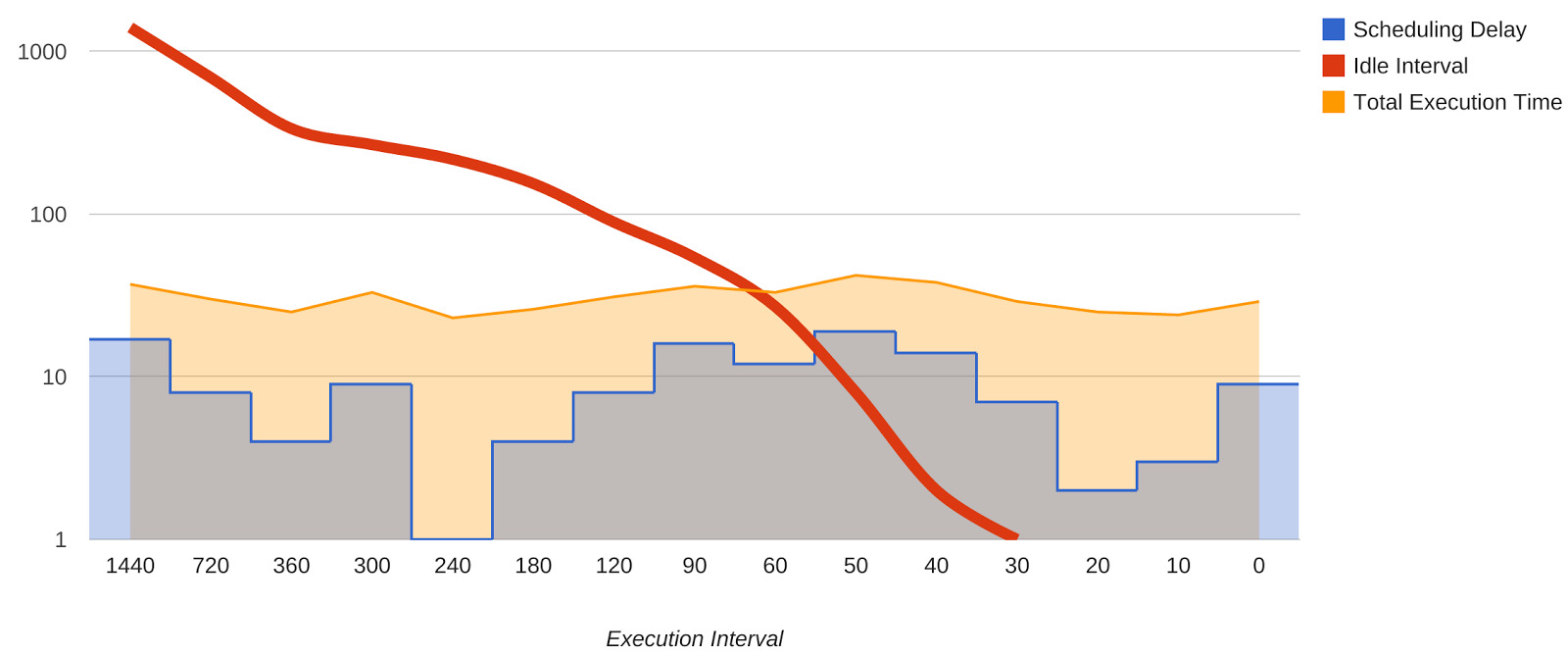
Figure 25.1: 週期性管線執行間隔 vs. 閒置時間(對數刻度)
- 週期性管線通常以低優先級 batch 跑(不像 web service 對延遲敏感)
- Borg 把 batch 安排到閒置機器以最大化使用率 → 啟動延遲長
- 高負載時可能被 preempt → 沒進度
- 執行頻率提高到接近平均延遲時 → 下一輪在前一輪結束前堆積 → 甚至殺掉接近完成的前一輪
- 解法:給予足夠的「production 優先級」資源——但配額管理本身就是難題
監控盲點#
- 標準做法在 job 完成才報指標
- 若 job 失敗、毫無統計可用
- 連續性管線天生有實時遙測——週期性原則上也可,但實務上常被忽略
驚群(Thundering Herd)#
規模一大,每輪同時拉起上千 worker → 共用基建(cluster service、網路)被打爆。
沒 retry 邏輯 → 工作被丟失;有 retry 但 naive → 雪上加霜。
人類介入會放大:經驗少的工程師發現 job 慢就加 worker → 害死叢集。
擺紋負載(Moiré Load)#
兩條以上週期性管線啟動時段偶爾重疊 → 共用資源瞬間飆高。連續性管線雖較均勻仍可能發生。
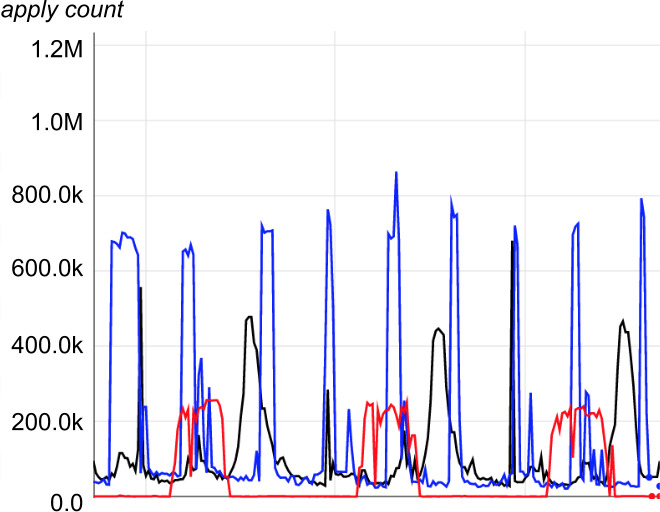
Figure 25.2: 獨立基建上的擺紋負載樣態
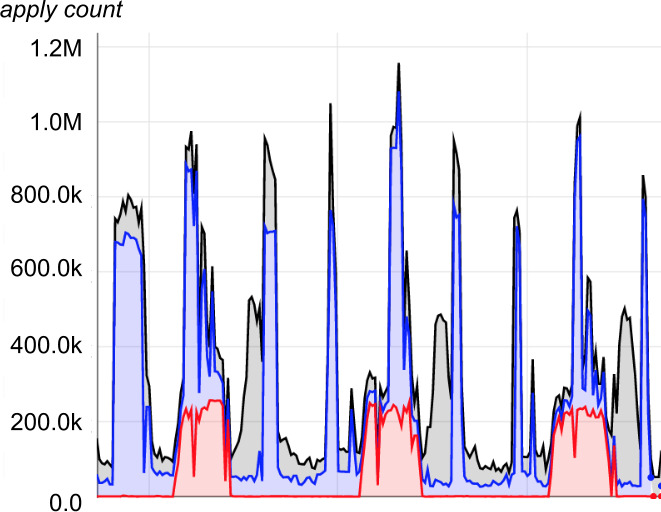
Figure 25.3: 共享基建上的擺紋負載樣態
Google Workflow#
2003 年 Google 開發 Workflow——大規模可連續處理的管線系統。
採用兩個設計模式:
- Leader-Follower(worker)
- System Prevalence:所有狀態放在記憶體以求高速,並同步寫 journal 到磁碟以求持久
結果:exactly-once 語意的超大規模交易式資料管線。
MVC 類比#
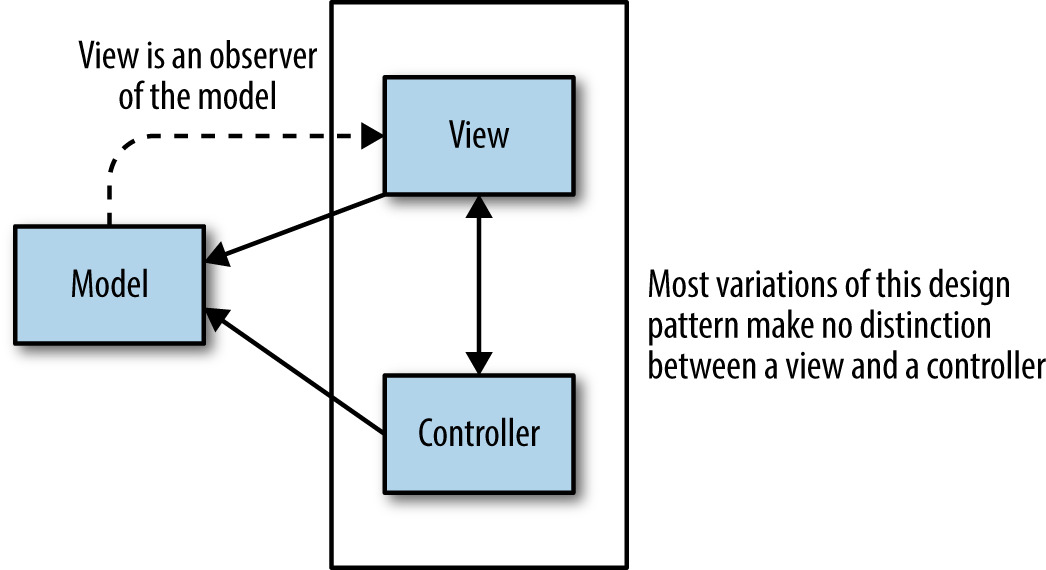
Figure 25.4: 使用者介面設計中的 MVC 模式
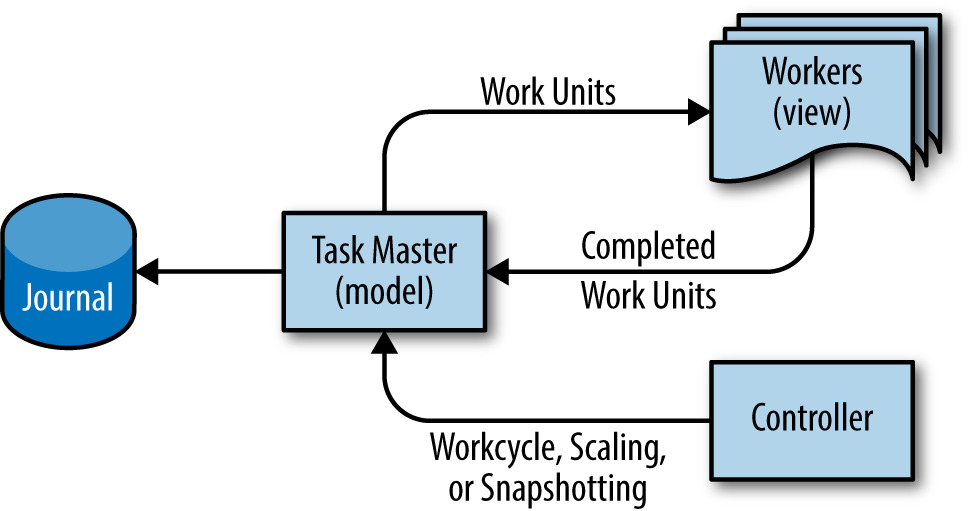
Figure 25.5: 用於 Google Workflow 的 MVC 設計模式
- Model:Task Master——以 system prevalence 把 job state 存在 RAM、同步寫 journal
- View:worker——無狀態,可隨意丟棄
- Controller(可選):負責動態擴容、snapshot、rollback、業務連續性等
Task Master 只存「指向工作的指標」,實際輸入輸出資料放在共同檔案系統——這是效能最佳的安排。
階段與 worker#
- 管線深度透過 Task Master 中的 task group 任意切分
- 每階段對應 worker 類型;worker 可自選類型
- 系統保證每個 work unit 至少永久反映在狀態中、且只執行一次
四個正確性保證#
- Worker 輸出搭配設定 task 創造 barrier
- Commit 需 worker 持有有效 lease
- 輸出檔名由 worker 產生且唯一——即使 orphan worker 也無法覆蓋有效 worker 的輸出
- Client / Server 在每個操作驗證 server token——避免 Task Master 被誤換 IP / port、或負載均衡器誤插導致 task ID 衝突
任務一旦更新或 lease 變更都產生新的唯一 task 取代舊的——所有 in-flight 工作必須 reference 當前設定 task ID 才能 commit。設定變更後,舊 lease 的 worker 即使完成工作也無法 commit,犧牲少量浪費換取設定一致性。
為什麼不直接用 Spanner 之類資料庫?
Workflow 的每個 task 是獨特且不可變的——這對防止大規模分配時的 subtle bug 非常重要。直接用 DB 則每次讀都必須在長交易裡,效能極差。
業務連續性#
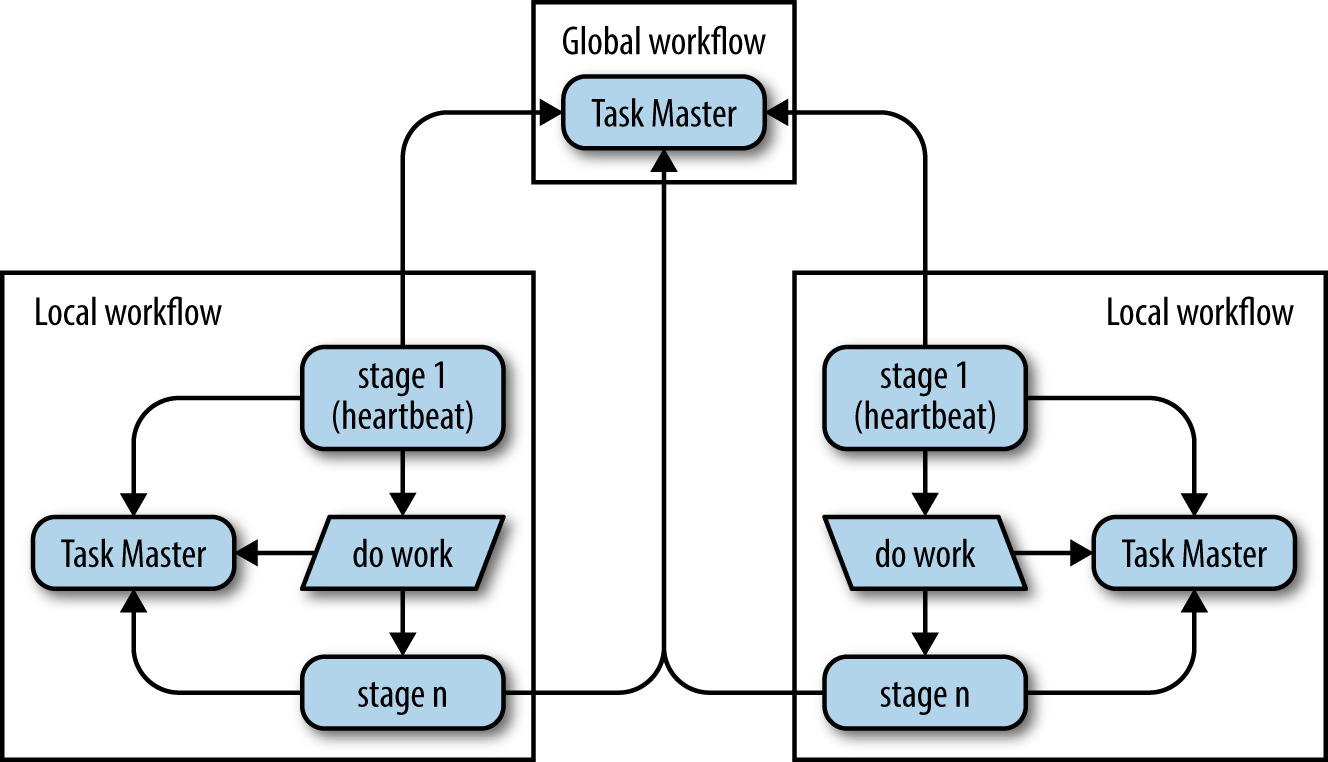
Figure 25.6: 用 Workflow 管線實作分散式資料與處理流程
大型管線必須撐過光纖斷、天災、電網級失效——這些可能廢掉整個 DC。沒採用 system prevalence 的管線通常會進入未定義狀態,業務復原昂貴。
Workflow 的全球設計:
- Task Master journal 寫到 Spanner(全球可用且強一致,但低吞吐)
- 用 Chubby 選舉「誰是寫者」並把結果存 Spanner
- 高吞吐由「兩個以上本地 Workflow」承擔;全球 Workflow 只存「reference tasks」
- 每個本地 Workflow 跑一支 helper(MVC 中的 Controller)
- 心跳停止 → 遠端 Workflow 接管 reference tasks 描述的工作
結語#
週期性管線有其用處——但若資料處理本質連續或會自然演化為連續,不要用週期性管線,請改用 Workflow 之類技術。
在分散式叢集基建上,Workflow 級別的「強保證 + 連續處理」可規模化、可信任,且 SRE 易維護。