本章描述 Google 的分散式 cron 服務——一個看似基本但設計起來充滿挑戰的系統。
單機 Cron 回顧#
Cron 是 Unix 工具,可在指定時間或週期執行任意 job。實作通常是 daemon crond 讀取 crontab 設定並依時啟動。
從可靠性角度:
- 失效域 = 一台機器;機器死了排程器與 job 都不會跑
- crond 重啟僅需 crontab 設定還在;launch 是「fire-and-forget」,不追蹤
- 例外是 anacron:嘗試補跑系統下線期間漏掉的 job(限每日或更低頻率)
Cron Job 的冪等性#
Cron job 性質差異極大:
- 有些冪等(GC、定期分析):多執行幾次安全
- 有些非冪等(發郵件電子報):絕不能執行兩次
又:
- 有些可接受漏 launch(每 5 分鐘的 GC 漏一次無妨)
- 有些不能漏(每月一次的發薪 job)
Google 偏好 fail closed——寧可漏跑也不雙跑。從「漏跑」復原通常比從「雙跑」復原可行(雙發新聞稿幾乎無法回收)。
大規模 Cron 的挑戰#
擴展基礎建設#
- 單機架構:放在 1,000 台機房中的一台 → 1/1000 機器故障就失效
- 解法:解耦行程與機器——只宣告服務需求,由 datacenter scheduler(Borg)負責找機器、處理機器死亡
- 但 reschedule 需要時間(health check timeout + 程式安裝 + 啟動)——一兩分鐘的延遲對「每 5 分鐘的 cron」可能不可接受
- 對策:hot spare 快速接手;local state 寫到分散式檔案系統(如 GFS)
擴展需求#
- 機房部署必然走容器(隔離)→ 必須預先宣告資源需求
- 啟動 cron job 可能涉及多個 RPC→ 必須處理「部分 RPC 成功部分失敗」
- Datacenter 比單機更複雜:應在機房內分布到不同失效域(避免單一 PDU 故障擊垮所有副本)
- 部署在單一 datacenter 而非全球——延遲低、與 datacenter scheduler 命運共擔
Google 的設計#
Paxos 與 leader / follower#
用 Paxos(Fast Paxos 變體)讓多副本保持一致狀態。
- Leader replica 是唯一能啟動 cron job、修改共享狀態的副本
- Leader 死亡時健康檢查在數秒內偵測 → follower 升為 leader → 接手未完成的工作
- 失效切換時間應 < 1 分鐘
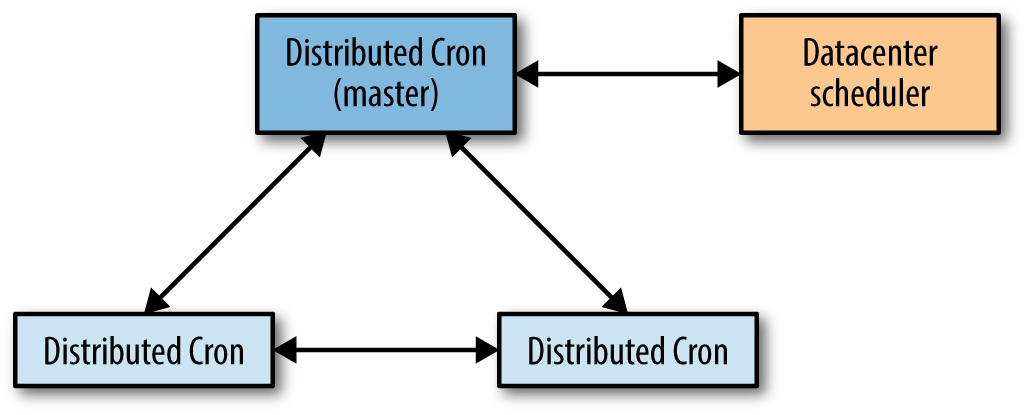
Figure 24.1: 分散式 cron 副本間的互動
關鍵狀態(透過 Paxos 同步):
- 哪些 job 正在啟動 / 已完成
- 每個 job 的啟動時間(用於唯一識別此次 launch——高頻 job 尤其需要)
Paxos 訊息必須同步——leader 必須等到 quorum 確認,才能真正執行 launch。
若 leader 死前未通知 follower,新 leader 會以為沒跑過、重複啟動。
一旦失去 leadership 必須立刻停止與 datacenter scheduler 互動,避免新舊 leader 互相衝突。
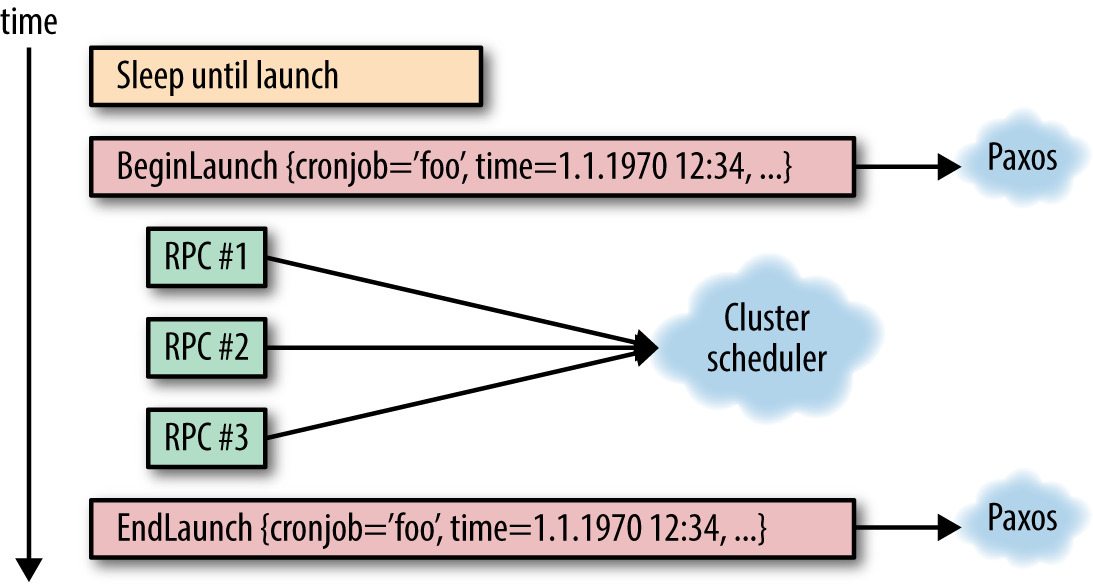
Figure 24.2: 從 leader 角度看 cron job 啟動的流程
解決部分失敗#
每個 launch 有兩個同步點:
- 即將執行
- 已完成
若 leader 在中間死掉,新 leader 必須能判斷上一次 RPC 是否真的發出。可選:
- 所有外部系統操作冪等
- 能查詢外部系統判斷操作是否完成
實作方式:預先構造 job 名稱(不需真實 mutate 即可確定名稱)→ 傳給所有副本 → 新 leader 上任時,查詢這些名稱的狀態、補跑缺少的。
名稱裡含「預期 launch 時間」,避免「上次成功了但 failover 太慢,新 leader 看不到狀態而重跑」。
儲存狀態#
Paxos log + snapshot 雙軌:
- Snapshot:最關鍵——丟了等於從零開始
- Log:丟了只損失「上次 snapshot 後的小段狀態」
Google 的選擇:
- Logs:本地磁碟(3 個副本各一份)——同時寫到 DFS 太慢且效益不大
- Snapshots:本地磁碟 + 備份到分散式檔案系統(保護「3 台同時掛」的情境)
- 新副本啟動時可從現有副本拉 snapshot 與 logs,與本地 state 解耦——換機器零負擔
大規模運行的副作用#
Thundering Herd#
預設「每天午夜」
0 0 * * *的 job 若有 30 個團隊都這樣設,且都會起千 worker 的 MapReduce → 機房瞬間爆炸。
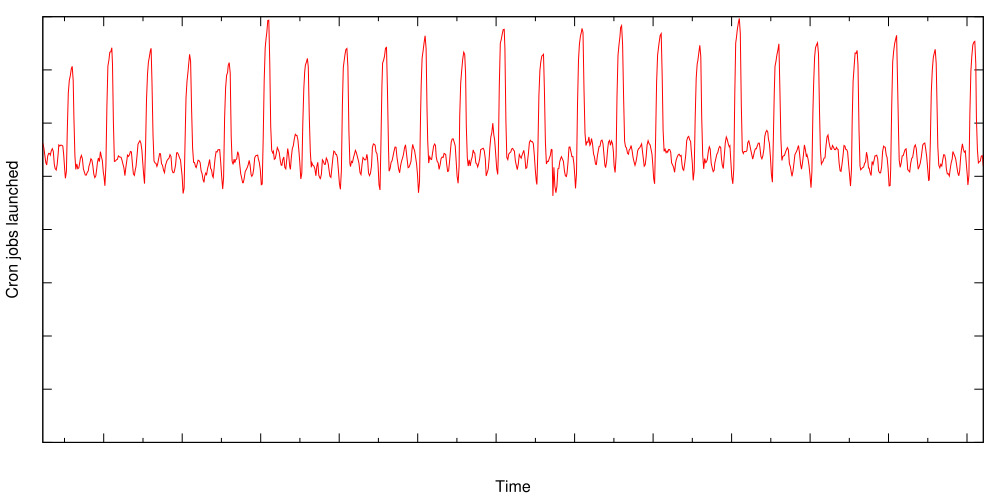
Figure 24.3: 全球 cron job 啟動數量
Google 的解法:擴充 crontab 格式——以 ? 取代特定欄位,讓 cron 系統依 job 設定 hash 自動挑分散的時刻。
即便如此,cron 啟動仍呈現尖峰圖樣——許多 job 必須對齊外部事件的特定時刻。
結語#
Cron 看似基本,但大規模分散式環境徹底翻轉它的可靠性設計:
- 強一致需求 → Paxos
- 嚴格分析 fail mode → 區分冪等 / 非冪等、漏跑 / 雙跑風險
- 跨機器與機房的部署 → 解耦 + datacenter scheduler 整合
結果是 Google 內部廣泛使用、可靠的 cron 服務。