行程會崩、硬碟會壞、整個地區可能斷電。SRE 必須讓系統跨多個位置運行——而跨位置維持一致的系統狀態才是真正困難的部分。
凡是涉及 leader 選舉、共享關鍵狀態、分散式鎖,都應使用已被形式化證明且經過充分測試的分散式共識系統。
分散式系統中常見的「需要共識」的問題:
- 哪個行程是 leader?
- 群組成員是誰?
- 訊息是否已被成功 commit 到分散式佇列?
- 行程是否持有 lease?
- 某 key 在 datastore 中的值是什麼?
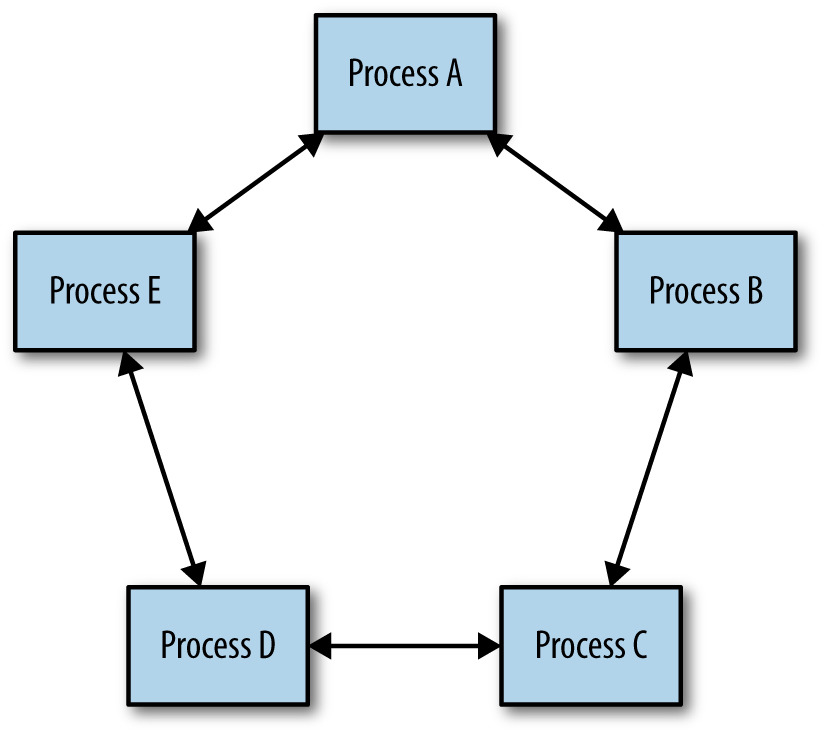
Figure 23.1: 分散式共識:一組行程達成一致視圖
CAP 定理回顧#
三者不可兼得:
- Consistency(節點間一致視圖)
- Availability(節點可用)
- Partition tolerance(容忍網路分割)
網路分割不可避免(線會被剪、封包會遺失、設定會錯)——理解分散式共識就是理解你的應用要在 C 與 A 之間怎麼取捨。
ACID vs. BASE:
- ACID:傳統強一致語意
- BASE:Basically Available、Soft state、Eventually consistent;通常以 multi-master + 衝突解決(如「最新 timestamp 勝出」)實現
- 最終一致性容易在 clock drift 或網路分割時帶來意外
- Jeff Shute:「最終一致性把過重的負擔丟給開發者——應該在資料庫層解決」
不能為了「可靠性 / 效能」犧牲「正確性」,特別是關鍵狀態(如金流)。分散式共識演算法是這類同步的工具。
真實案例:為什麼需要共識#
Split-Brain(腦裂)#
兩台檔案伺服器互為主從,用 heartbeat 監控,失聯時送 STONITH(Shoot The Other Node in the Head)。網路慢時:兩邊都超時、各自發 STONITH、各自上位——若命令未被傳達,可能變「兩主同時寫」或「兩邊都被 shutdown」。
用 timeout + heartbeat 解 leader 選舉根本上是錯誤——leader election 是分散式非同步共識問題的另一種表述,不能用 heartbeat 解決。
Failover 需要人類介入#
分片資料庫 primary/secondary 通訊失敗時叫人——避免 split-brain。但這把運維負擔放大:人類在大規模事件中常已過載,且不會比正確的共識系統做得更好。
群組成員演算法失靈#
用 gossip 協定發現成員、選 leader。網路分割時兩邊各選 leader → 各自接受寫入與刪除 → split-brain → 資料毀損。
許多「分散式系統問題」其實都是分散式共識的變形:master 選舉、群組成員、分散式鎖 / lease、可靠分散式佇列 / 訊息、跨群組關鍵共享狀態。
臨時起意的解法(heartbeat、gossip)永遠會在實務上出問題。
分散式共識如何運作#
關注非同步分散式共識(訊息傳遞延遲無上限)。實務上多採 crash-recover(崩潰後可回來)而非 crash-fail。
Byzantine(拜占庭)故障(行程因 bug 或惡意送錯訊息)較罕見,處理成本高。
FLP 不可能性:嚴格證明在有限時間內無法保證非同步共識,但實務上靠「夠多健康副本 + 隨機退避」絕大多數時候能 make progress。
Paxos 概觀#
Lamport 提出的協定,後續還有 Raft、Zab、Mencius。
- 由一系列**提議(proposals)**組成,每個有 sequence number
- 第一階段:proposer 向 acceptor 送 seq;acceptor 只接受未見過更高 seq 的提議
- 達多數同意 → proposer 送 commit
- 嚴格 sequencing + 多數同意 → 同一提議不會 commit 兩個不同值
- Acceptor 同意時需寫 journal 到持久儲存
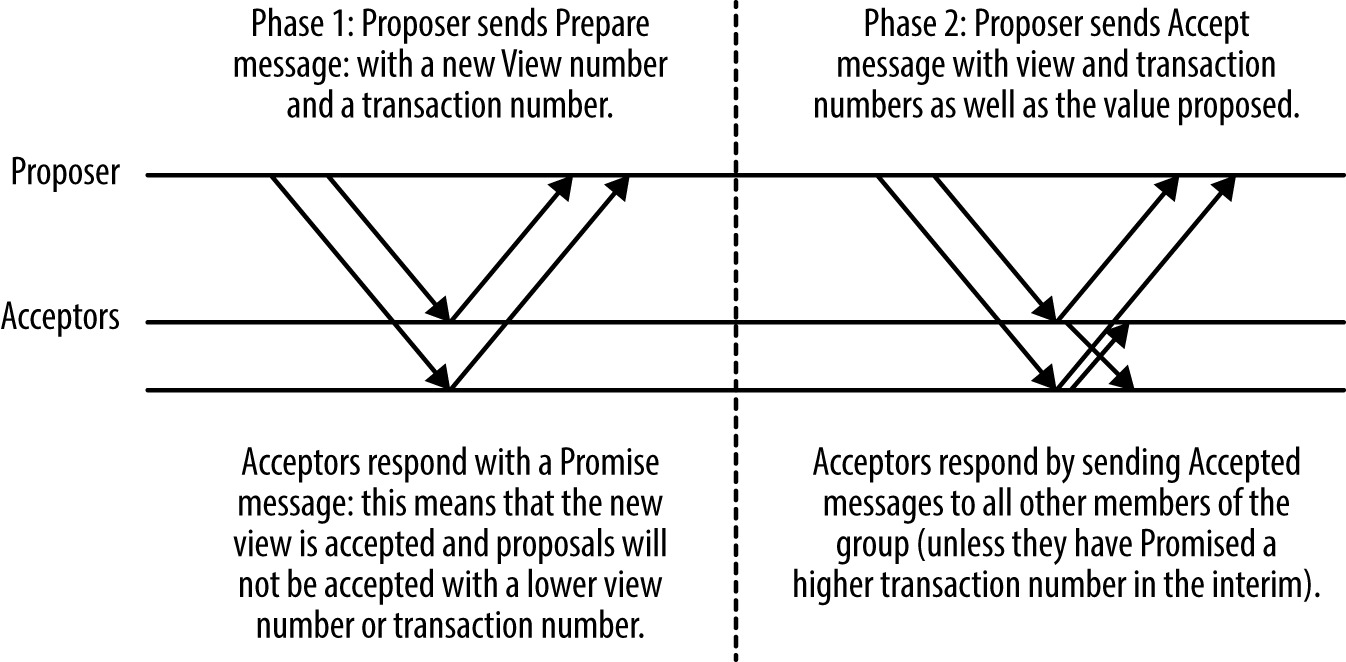
Figure 23.7: Multi-Paxos 的基本訊息流
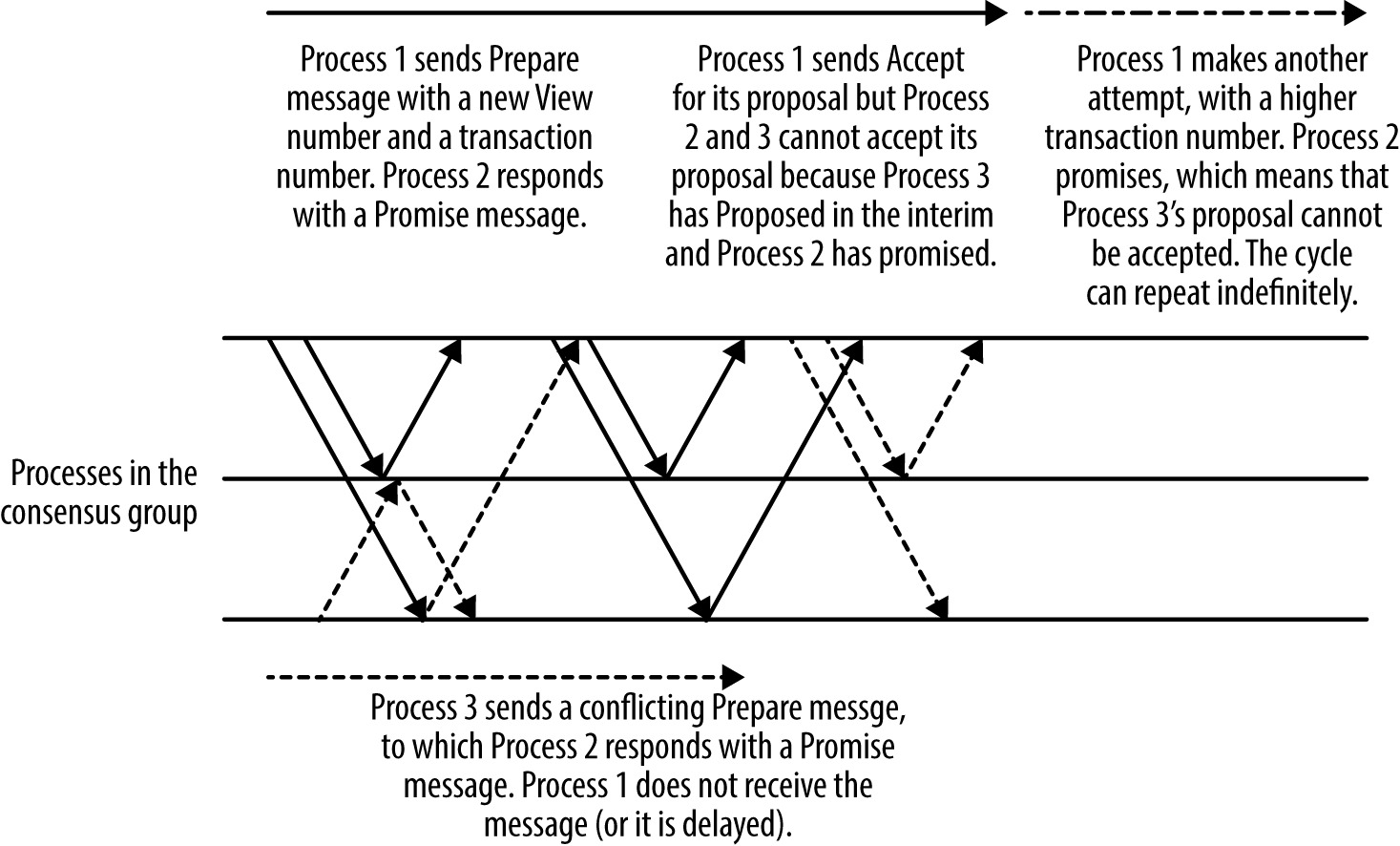
Figure 23.8: Multi-Paxos 中的 dueling proposers
Paxos 本身只能對一個值達成一次共識——實用價值來自把它包進高階系統元件(datastore、configuration store、queue、lock、leader election)。
系統架構模式#
Replicated State Machine(RSM)#
RSM 在多個 process 上以相同順序執行相同操作,是有用分散式系統元件的基本構件——任何決定性程式可由 RSM 實作。

Figure 23.2: 共識演算法與副本狀態機之間的關係
可靠的副本資料儲存與配置儲存#
- 把資料寫入由分散式共識協調的儲存後再回應
- 範例:Zookeeper、Consul、etcd;Google 內部的 Chubby
把共識做成服務而非函式庫,讓使用者不必親自部署高可用共識系統(管副本數、群組成員、效能等)——這是 Chubby 設計的核心理念。
用 Leader Election 做高可用處理#
- 一群 leader / follower 並列,由共識選 leader 處理寫入
- 與多 master 寫入相比,設計顯著簡單——但延遲在 leader 切換時較高
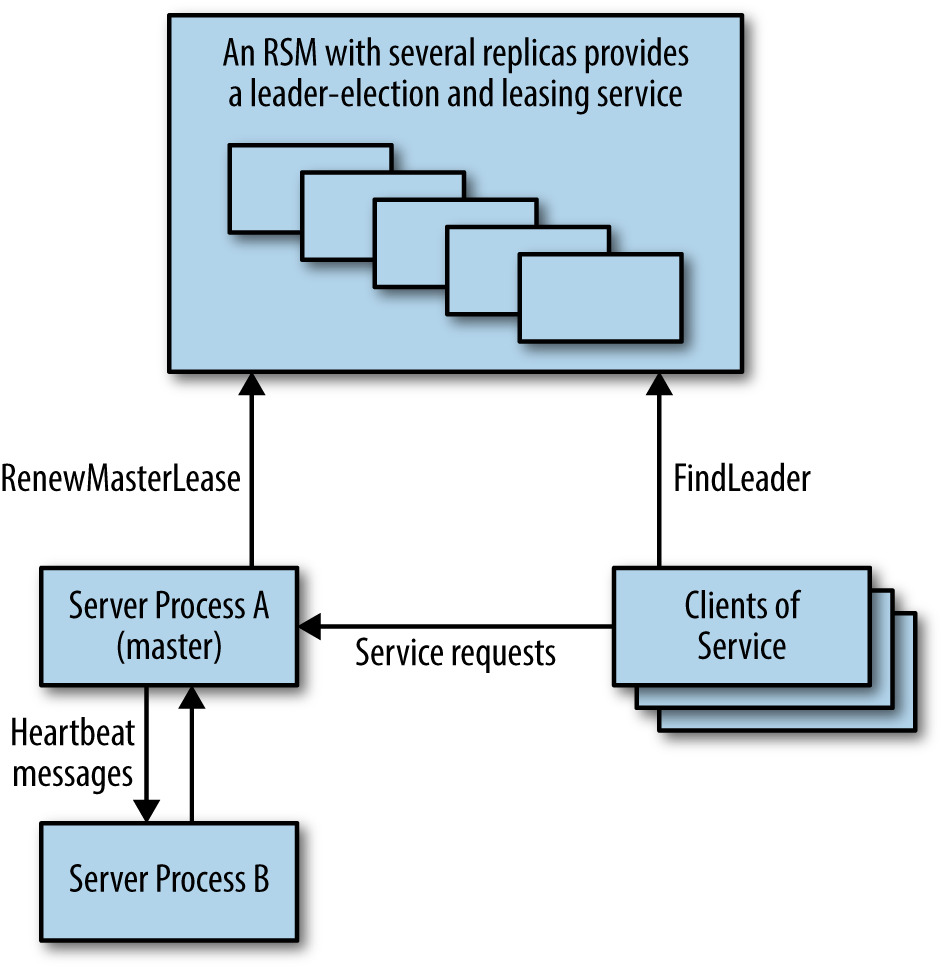
Figure 23.3: 以副本服務做 master 選舉的高可用系統
分散式協調與鎖#
- Lock 過期:避免持有者死掉沒釋放
- Lease:持有者必須週期續租;網路分割時自動釋放
- Chubby 提供類檔案系統 API,許多服務用它做 master 選舉
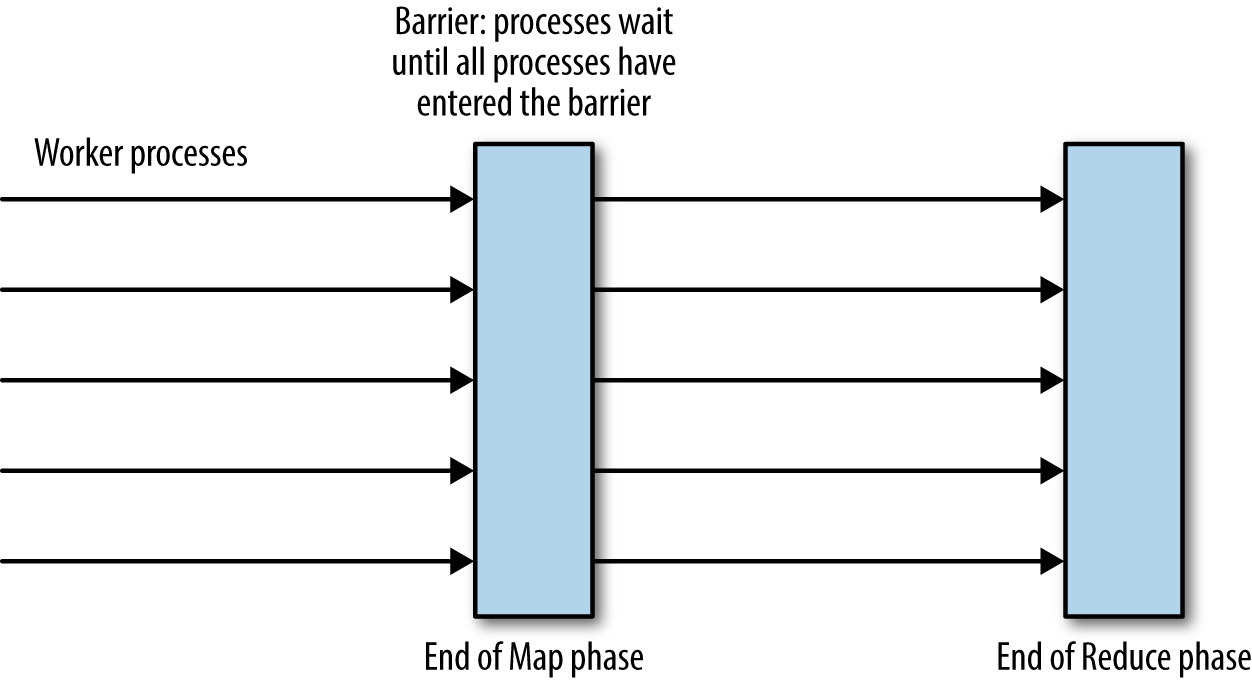
Figure 23.4: MapReduce 運算中的行程協調 barrier
可靠分散式佇列與訊息#
- 訊息至少一次(at-least-once):可重複處理
- 訊息精確一次(exactly-once):需共識協調
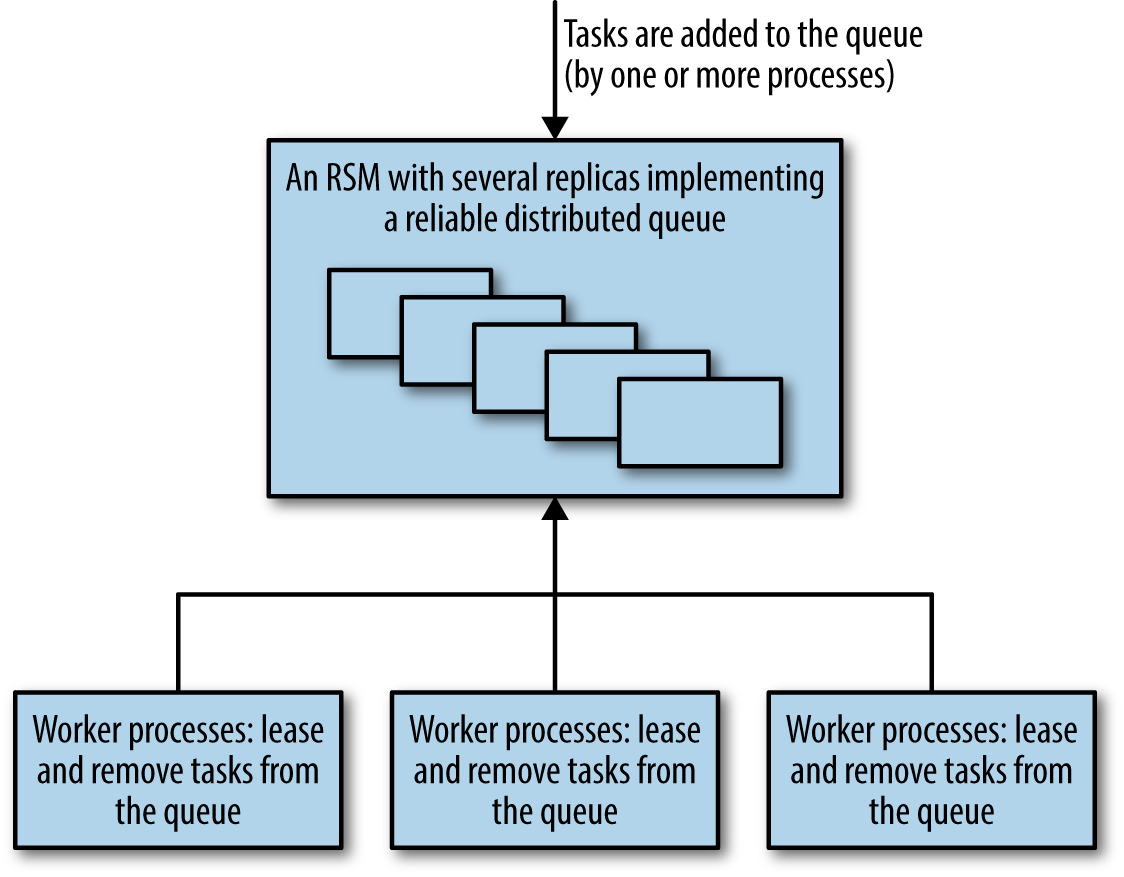
Figure 23.5: 以可靠共識為基礎的佇列式工作分配系統
分散式共識的效能#
共識協定的「貴」常被高估——許多人因「直覺認為慢」而避開,自製不可靠的解決方案。
效能取決於:
- 吞吐量:批次化(batching)+ 管線化(pipelining)效益顯著
- 延遲:
- 本地寫入比跨 DC 寫入快得多
- Quorum lease:把 quorum 集中在某子集,可大幅縮短「常見讀取」延遲
- 網路 round trip 數:Paxos 經典版需 2 round trip,可優化到 1
- 磁碟 fsync:每次共識決策需 fsync——SSD 比 HDD 重要
- 網路分割:協定要能在多數派可達時 make progress
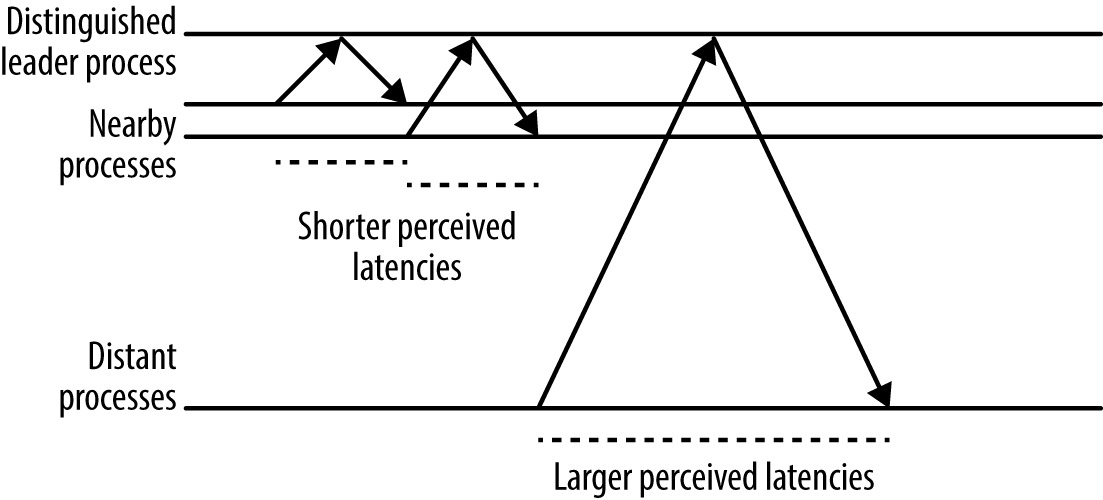
Figure 23.6: 伺服器距離對 client 感受到的延遲的影響
部署考量#
- 副本數至少 3 個,常為 5 個(容忍 1 個維護 + 1 個失敗)
- 跨 DC 部署:使用獨立失效域;但延遲較高
- 量身設計副本拓撲:3 個於本區 + 2 個於遠區,避免常見 quorum 跨遠路徑
- Witness(見證者)副本:只保留 metadata,協助達 quorum 但不負責資料
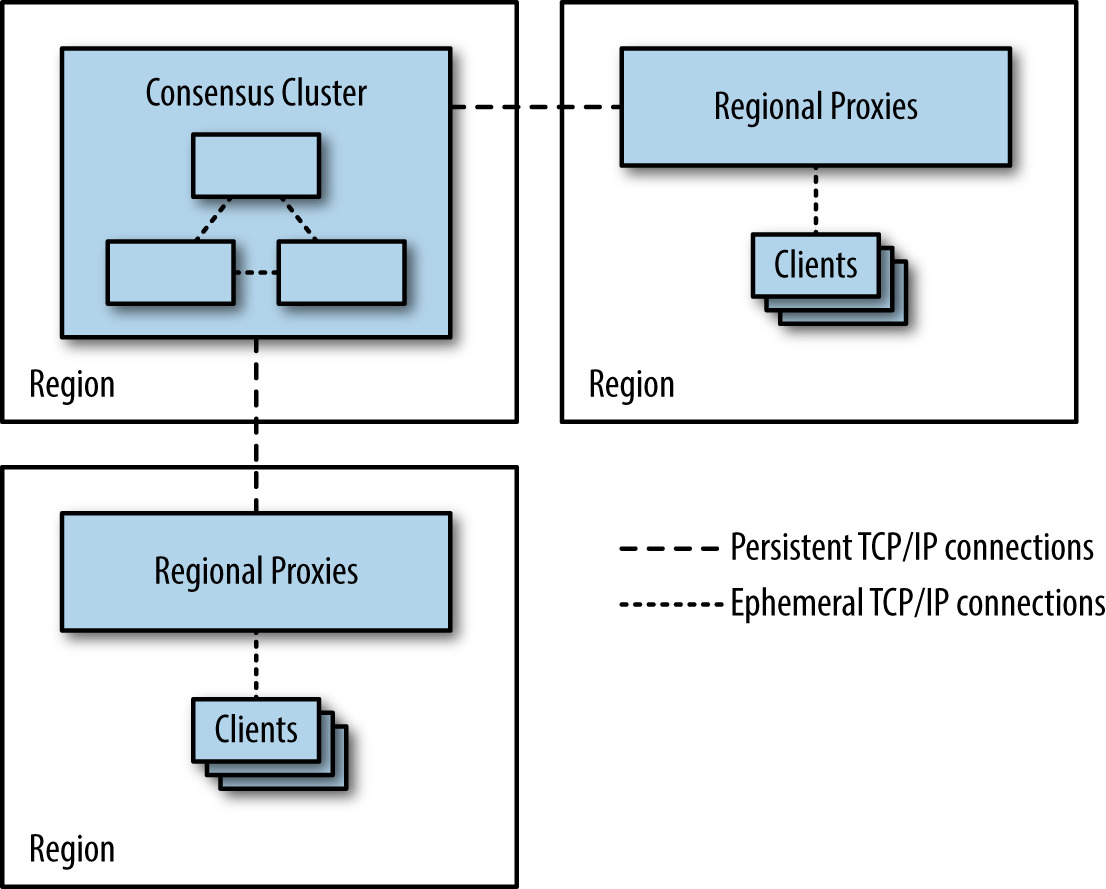
Figure 23.9: 用 proxy 減少 client 跨區開啟 TCP/IP 連線的需求
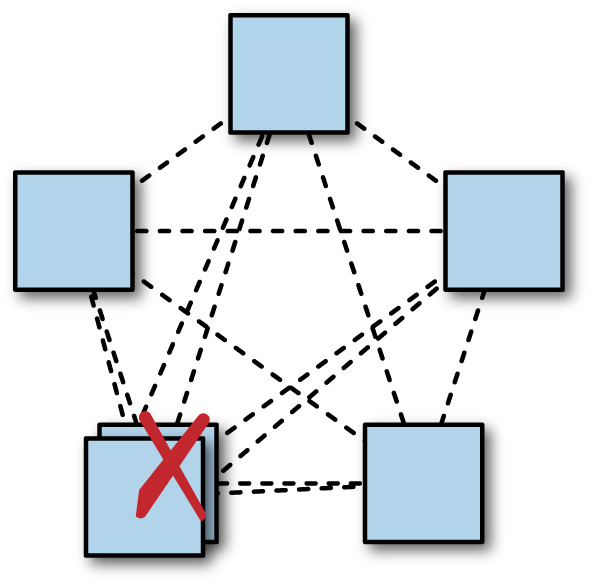
Figure 23.10: 在一個 region 增加一個副本反而可能降低系統可用度
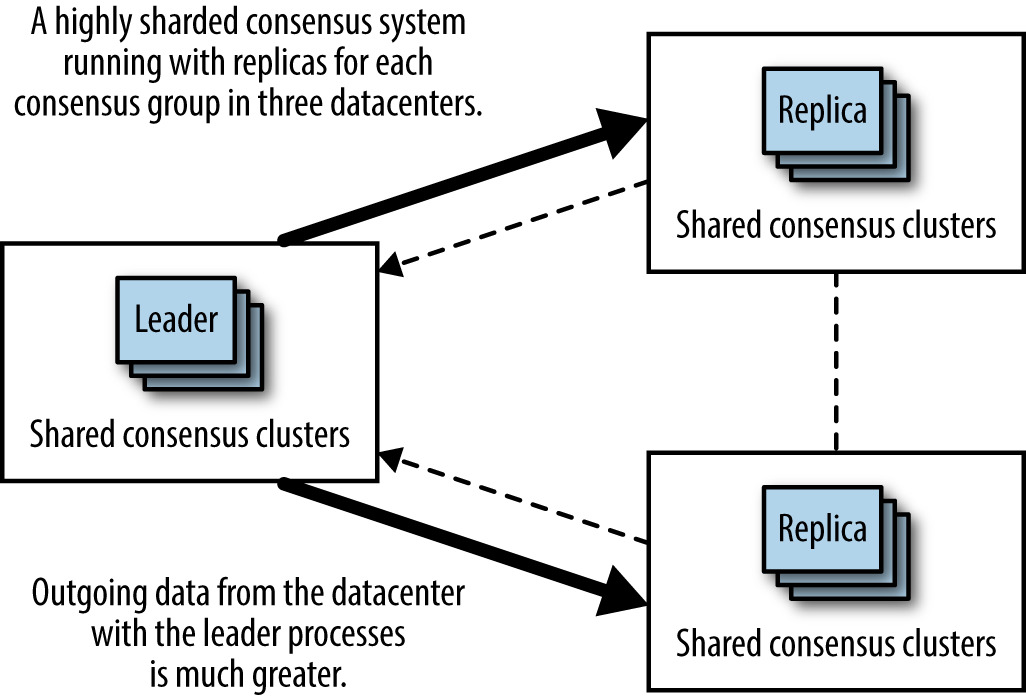
Figure 23.11: leader 行程集中部署造成頻寬使用不均
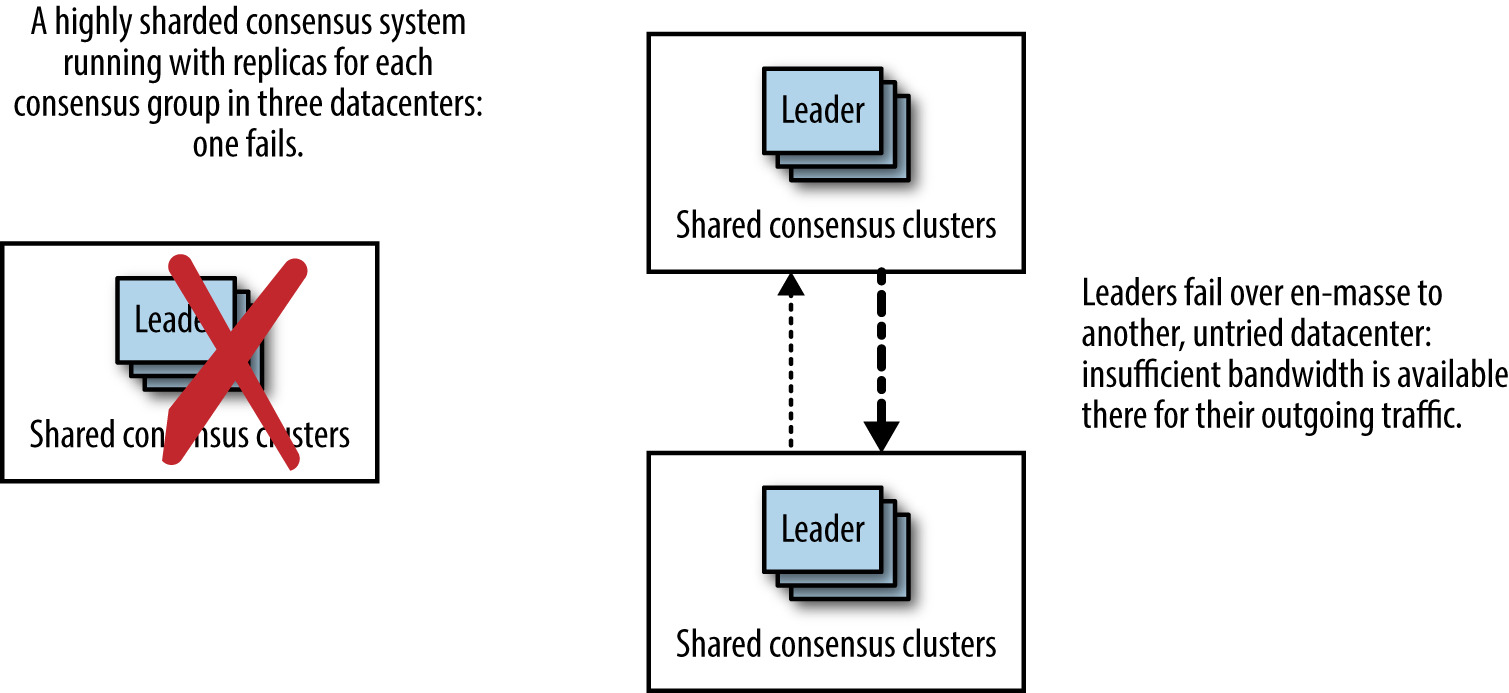
Figure 23.12: 集中部署的 leader 集體 failover 時網路使用樣態劇變
Figure 23.13: 以一個副本作為連結的重疊 quorum
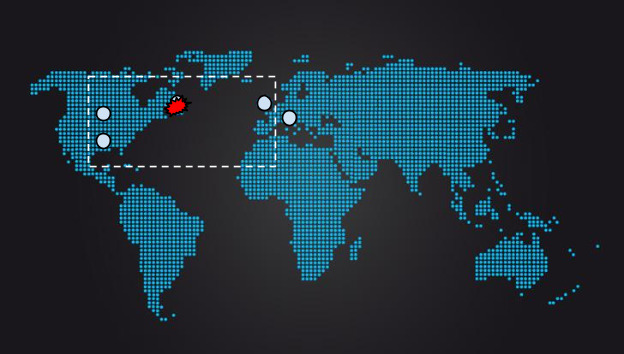
Figure 23.14: 連結副本一旦失效,任何 quorum 的 RTT 立即拉長
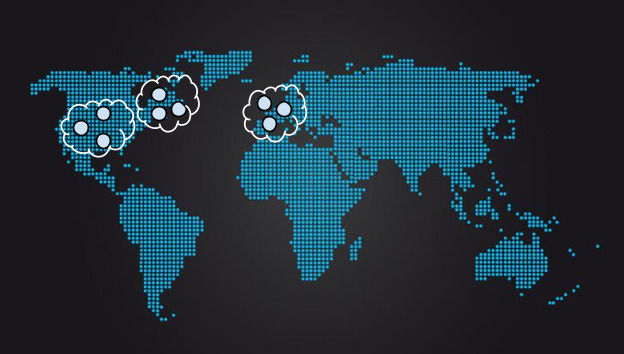
Figure 23.15: 用階層式 quorum 降低對中央副本的依賴
監控分散式共識系統#
關鍵指標:
- 每個成員看到的群組成員數
- 是否認為自己是 leader
- 已接受 / 提議 / commit 的提議數
- 因衝突拒絕的提議數
- 達成共識的延遲分佈
- 持久儲存層的延遲(log write)
- 持久儲存層的位元組吞吐量
結語#
不要自製分散式共識——使用 Zookeeper、Consul、etcd 等已驗證系統,或內部的 Chubby。
共識協定看似低層,但放進高層服務(RSM、leader election、locking、queue)後能大幅簡化分散式系統的設計與推理。