如果第一次沒成功,就指數退避。 — Dan Sandler,Google Software Engineer
為什麼人們總忘了要加一點 jitter? — Ade Oshineye,Google Developer Advocate
連鎖故障(cascading failure):因正向回饋而隨時間擴大的故障。例如一個 replica 過載失敗 → 剩餘 replica 負載增加 → 更可能失敗 → 一路骨牌效應。
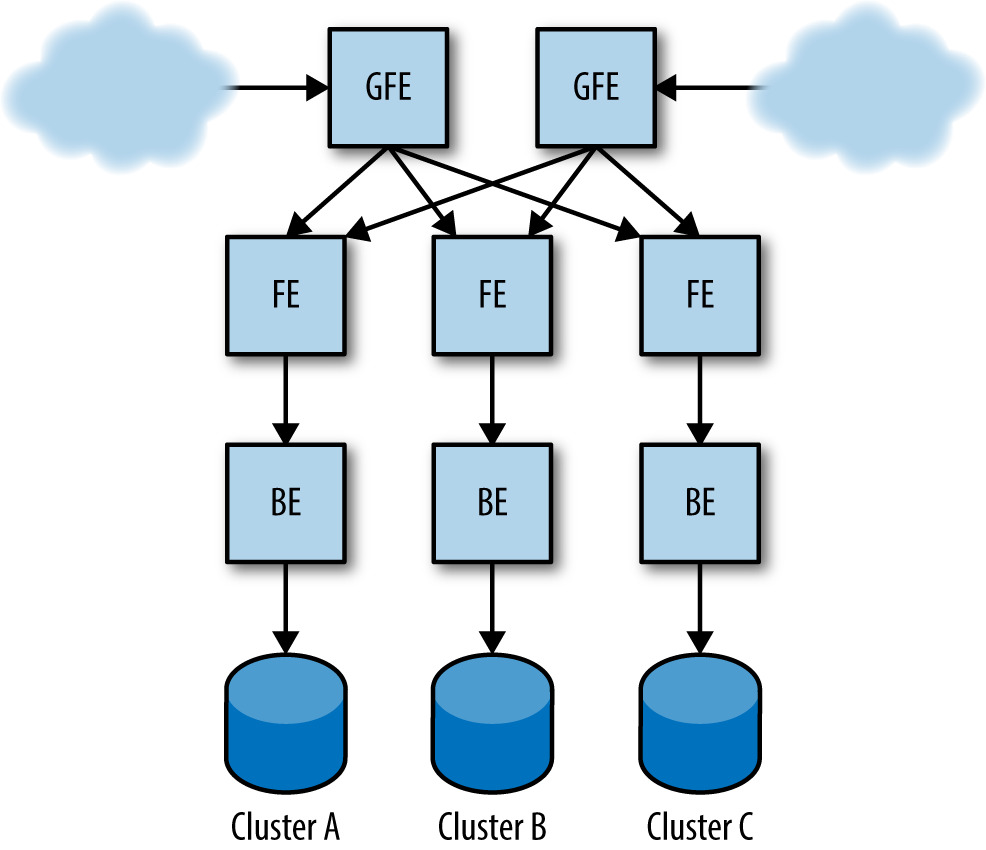
Figure 22.1: Shakespeare 搜尋服務的生產配置範例
連鎖故障的成因與防範設計#
伺服器過載#
最常見的成因。例:cluster A 處理 1,000 QPS、B 處理 1,000 QPS;B 掛掉後 A 突然要扛 1,200 QPS → 資源耗盡 → 崩潰 → load balancer 把流量送往其他 cluster → 全服務級過載。
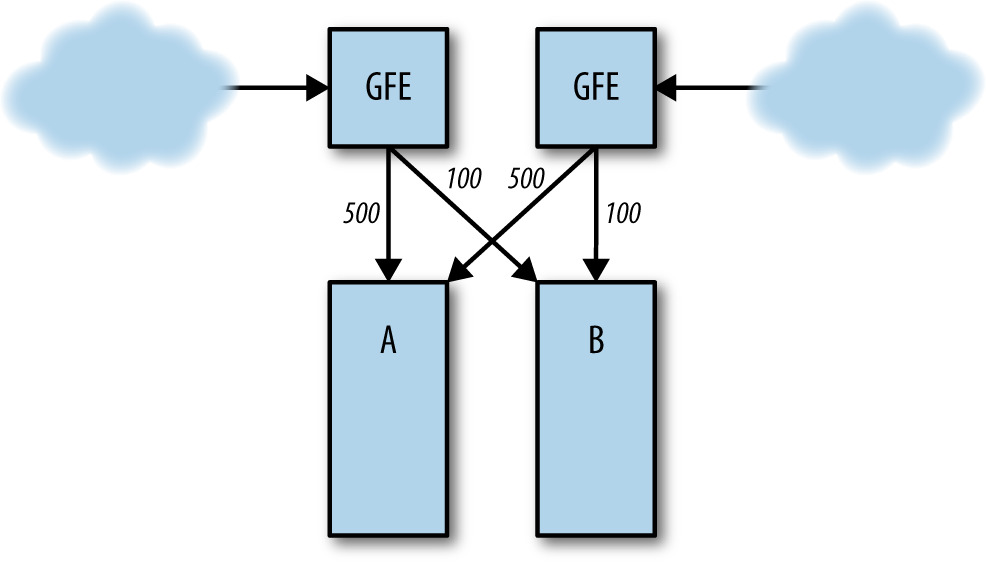
Figure 22.2: Cluster A 與 B 間的正常負載分布
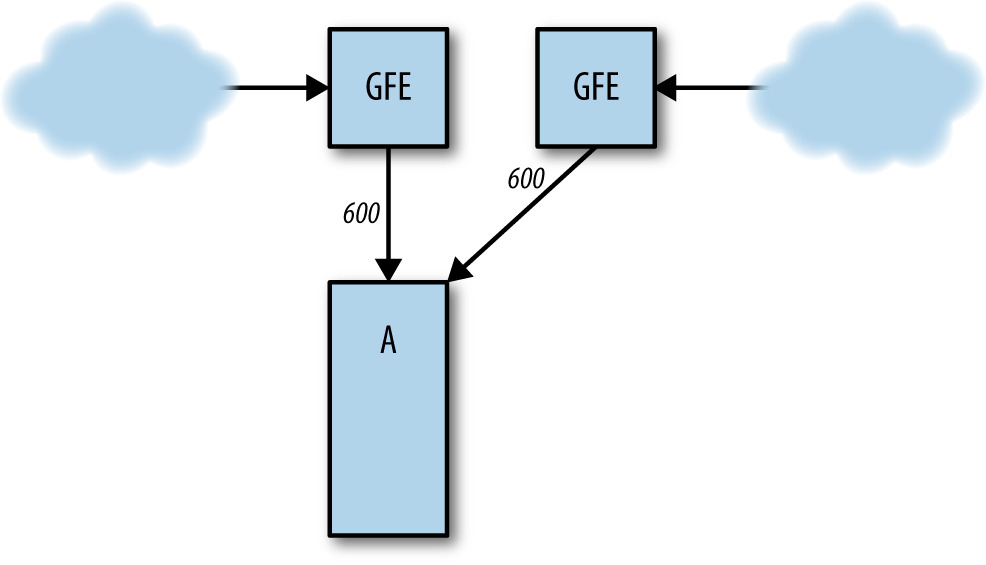
Figure 22.3: Cluster B 失效,所有流量湧向 Cluster A
資源耗盡#
不同資源耗盡造成不同副作用:
- CPU:請求變慢 → in-flight 數增 → 佇列長 → thread starvation → health check 失敗 → 內部 watchdog 殺 task → 超過 RPC deadline 浪費資源 → cache locality 下降
- 記憶體:task 被 container manager 驅逐;Java GC 死亡螺旋——CPU 少 → 請求慢 → 記憶體升 → GC 更頻繁 → CPU 更少;cache hit rate 下降
- 執行緒:starvation 直接造成錯誤或 health check 失敗;極端時耗盡 PID
- 檔案描述符:耗盡無法建立連線、health check 失敗
資源耗盡情境互相餵食。例:Java GC 失調 → CPU 滿 → 請求慢 → 記憶體升 → cache 變小 → 後端負載升 → 後端 CPU 滿 → health check 失敗 → 啟動連鎖故障。
在停機現場幾乎不可能追完整個因果鏈。
服務不可用#
伺服器一旦進入 crash-loop 很難脫身——新啟動的 task 一上線就被打爆。10,000 QPS 健康、11,000 QPS 開始崩潰,降到 9,000 QPS 也不一定能恢復——只剩少數健康 task 在硬撐。
預防伺服器過載(優先順序)#
- 負載測試容量上限,並測試過載時的失敗模式——這是最重要的一件事
- 降級回應:返回較便宜但較不精準的結果
- 過載時自我拒絕:早失敗、便宜失敗
- 更高層系統的速率限制:在反向代理(限 IP)、LB(全服務過載時丟)、個別 task(防止 LB 隨機抖動打爆)
- 容量規劃 + 效能測試
佇列管理#
- 穩態下,理想是「沒有佇列」——constant 流量下,constant 執行緒數即足夠
- 佇列消耗記憶體並增加延遲(佇列長 10x 執行緒 + 100 ms 處理時間 → 請求要 1.1s)
- 穩定流量服務佇列長度應 ≤ 執行緒池 50%
- Gmail 用 queueless,依靠 failover 到其他 task
- 突發流量服務可動態調整佇列長度
降載(Load Shedding)與優雅降級#
- 過載時直接回 HTTP 503
- 佇列順序由 FIFO 改 LIFO 或用 CoDel——丟掉「使用者已放棄」的請求
- 配合 deadline 傳播效果更佳
優雅降級進一步:減少需要做的工作量(搜尋只搜部分 corpus、用較不精準但較快的排名)。
- 降級路徑平常不用 = 平常壞了沒人知道:用「讓部分 server 接近過載」定期演練降級路徑
- 監控與告警「進入降級的伺服器數量」
- 過度複雜的降級邏輯本身會出問題,設計快速關閉與調參的能力
Retry 的陷阱#
Retry 是連鎖故障的主要放大器。
假設後端每 task 上限 10,000 QPS,frontend 送 10,100 QPS。失敗的 100 QPS retry → 後端變 10,200 QPS → 200 QPS 失敗 → 更多 retry → 雪球。
設計守則:
- 隨機化指數退避(含 jitter)——「為什麼人們總忘了 jitter?」
- 限制每次請求的 retry 次數(如 3 次)
- 設定伺服器級 retry budget(如每分鐘 60 次)
- 整體系統評估「是否真的需要 retry」——多層級 retry 的乘法效應(4³ = 64 次)會擊垮資料庫
- 用清楚的回應碼分辨可 retry vs. 不可 retry
- 過載時回「overloaded; don’t retry」
延遲與 Deadline#
連鎖故障的常見主題:伺服器花資源處理已經超過 client deadline 的請求——做白工。
- 設 deadline;多階段請求每階段檢查 deadline 是否還有剩
- Deadline 傳播:A 設 30s deadline,處理 7s 後呼 B,B 用 23s deadline;B 處理 4s 再呼 C,C 用 19s deadline——避免「上游已超時、下游仍在做工」
- Cancellation 傳播:上游放棄時,下游也要 cancel
- 留一點 buffer(網路 + post-processing)
Bimodal Latency(雙峰延遲)#
5% 的請求觸碰 deadline(如 100s)→ 用掉 5,000 threads(50 QPS × 100s)→ frontend 只有 1,000 threads → 80.4% 的請求變錯誤。
防範:
- 看分佈而非平均
- 後端不可用時快速失敗,不要等到 deadline
- Deadline 不要比平均延遲大多個數量級
- 對單一 key space 限制 in-flight requests,避免單一惡客戶吃光資源
慢啟動與冷快取#
冷快取常因:新叢集 turn-up、維護後回流、task restart。
區分「延遲快取」與「容量快取」:
- 延遲快取:空 cache 也能扛預期負載
- 容量快取:空 cache 無法扛——這是危險的隱性依賴
策略:過度配置、緩慢加載流量讓快取暖機、考慮把快取移到 memcache 等共享層。
永遠往下走,不要層內互通#
Backend 之間互相 proxy 會造成分散式 deadlock 與正回饋放大。
例:A 的 thread pool 滿 → B 送請求等 A → B thread pool 也滿 → 飽和傳播。
解法:讓 client 重試到正確 backend,不要在同一層互轉。
連鎖故障的觸發條件#
- 行程死亡:Query of Death、cluster 問題、assertion 失敗
- 行程更新:太多 task 同時被更新;應在離峰或限制同時更新數
- 新版本發佈:請求 profile、資源用量改變
- 有機成長:使用量增加但容量沒跟上
- 計畫性變更 / drain / turndown:跨機房維護
- 請求 profile 變化:流量 mix、平均成本變化(如使用者上傳更多更大的圖)
- 資源 over-commit 的閒置 CPU 不可信:別人開大型 MapReduce 你的 slack CPU 就沒了
連鎖故障的測試#
測到壞掉、再測壞掉之後:
- 在過載時是優雅降級還是崩潰?
- 知道斷裂點 → 知道容量規劃的安全餘裕
- 同時測「漸進增加」與「瞬間衝擊」兩種模式
- 高負載解除後能否自動回到正常?
也要測:
- 大客戶行為:是否會 queue work、用 random exponential backoff、外部觸發是否會清空他們的 cache?
- 非關鍵後端:當它 timeout 或 blackhole,前端會不會也跟著垮?
連鎖故障發生時的應變#
一旦確認連鎖故障,可採用以下手段(且這正是該套用第 14 章事件管理流程的時候):
- 增加資源:若還有閒置容量
- 停掉 health check 殺死:避免「health check 本身造成不健康」
- 重啟伺服器:GC 死螺旋、deadlock、無 deadline 的長請求
- 丟流量:終極大錘——
- 解決觸發條件
- 把流量壓到很低(如 1%)讓伺服器逐步恢復
- 等多數 server 健康
- 慢慢加流量
- 進入降級模式:少做事、丟非重要流量
- 關 batch 作業:索引更新、資料複製、統計蒐集
- 擋掉壞請求:query of death
Shakespeare 案例#
日本紀錄片提到 Shakespeare 服務 → 亞洲流量暴增同時撞上更新 → 任務逐一失敗 → SRE 加 task 暫時擴容 → 事後寫 postmortem,加上 GSLB 跨 DC 流量重導 + 自動擴容。
結語#
系統過載時必須有東西讓步。超過斷裂點後,讓部分使用者看到錯誤或較差品質比硬撐所有請求好。
提醒:許多「改善穩態」的改動(retry、shift load、kill unhealthy server、加 cache)反而可能放大連鎖故障的風險。評估每個變更時,留意不要「用一場故障換另一場故障」。