無論負載平衡再聰明,系統總有部分會被打爆。優雅處理過載是可靠服務的基礎。
兩個基本緩解手段:
- 提供降級回應(degraded responses):較不精準或資料較少,但成本低
- 只搜尋全部 corpus 的一小部分而非全部
- 用本地過期副本而非主儲存
- 跨資料中心做容量上限的流量分配:每 DC 都不會收到超過自身可處理量的流量
但這些都不夠。Client 與 Backend 都該優雅處理資源限制:能轉就轉、必要時降級、最後才回錯誤。
QPS 不是好指標#
以 QPS 或「請求讀取了多少 key」這類靜態特徵模擬容量,現在準確不代表以後準確——同一比例會隨 client 行為與軟體版本飄移。
更好的方式:用 CPU 消耗直接量。
- GC 平台中記憶體壓力會自動翻譯成 CPU
- 其他平台可把非 CPU 資源 over-provision 到「不會先於 CPU 耗盡」
「請求成本」就是它消耗的 CPU 時間(跨 CPU 架構正規化後)。
每客戶配額#
全球過載時,只應該對「行為失當」的客戶回錯誤,其他客戶不受影響。
服務擁有者依協商使用量設定 per-customer quota。例:10,000 CPU 配額下:
- Gmail:4,000 CPU·s/s
- Calendar:4,000 CPU·s/s
- Android:3,000 CPU·s/s
- Google+:2,000 CPU·s/s
- 其他:500 CPU·s/s
加總 > 10,000 沒關係——假設不會同時打滿。
實作上:
- 即時聚合全球用量,推送有效上限到各個 backend task
- 對非 thread-per-request 的伺服器(用 nonblocking I/O thread pool),逐請求精確計算 CPU 並不容易
Client 端節流(Adaptive Throttling)#
拒絕請求並非完全免費——若大量拒絕也會把 backend 打爆。
解法:當 client 偵測自己近期請求被大量拒絕,自我節流,不再送往網路。
Adaptive throttling 演算法(每個 client 維護過去 2 分鐘的數據):
requests:應用層嘗試的次數accepts:backend 接受的次數
當 requests > K × accepts 時,client 以下列機率本地拒絕:
$$\max\left(0, \frac{\text{requests} - K \times \text{accepts}}{\text{requests} + 1}\right)$$
K 通常用 2:略過量地把流量送到 backend,可加速 backend 「停止拒絕」的狀態傳播。
K 較小(如 1.1)會更積極節流,但 backend 對節流解除的反應較慢。
重要度(Criticality)#
Google 把每個 RPC 都標一個 criticality(共四級),並在 RPC 系統做為一等公民。
- CRITICAL_PLUS:失敗會嚴重影響使用者
- CRITICAL:production job 預設;影響使用者但較輕
- SHEDDABLE_PLUS:可預期部分不可用(batch job 預設)
- SHEDDABLE:可預期經常性部分不可用、偶爾完全不可用
使用方式:
- 客戶配額用盡時,backend 只在「所有低 criticality 都已拒絕」後才拒絕高 criticality
- Task 自身過載時,較低 criticality 先被拒絕
- Adaptive throttling 各 criticality 分開統計
- 透過 RPC 自動傳播:A → B → C 時,B、C 的 criticality 預設與 A 相同
Criticality 與 QoS / 延遲需求正交:搜尋打字建議是高 SHEDDABLE 但低延遲。
利用率訊號(Utilization Signals)#
Task 自我保護以「利用率」為基礎——通常是 CPU rate(也可加入 memory)。
越接近上限,越積極拒絕——criticality 高的可拒絕門檻較高。
Executor Load Average:
- 計算進程中「active」執行緒數(執行中或等待 CPU 的)
- 指數加權平滑
- 超過 task 可用 CPU 數時開始拒絕請求
- 短促 fan-out 因平滑而被吸收;持續高負載則會觸發拒絕
處理過載錯誤#
兩種情境:
- DC 大部分後端都過載:retry 沒用——讓錯誤往上傳到使用者
- DC 中只有少量後端過載(更常見):retry 通常有用——多半會打到別的可用 task
Google 不刻意保證 retry 落到不同 task——依機率自然分散到 subset 內的其他成員。
何時 retry#
三層保險:
- Per-request retry budget:最多 3 次
- Per-client retry budget:retry 比例不超過 10%——若全 DC 都壞,retry 不會放大 3 倍而是 ~1.1 倍
- Backend 回傳特殊錯誤:在請求 metadata 帶上「已嘗試次數」直方圖;若 backend 看到很多 high-attempt 請求 → 改回「overloaded; don’t retry」防止組合爆炸
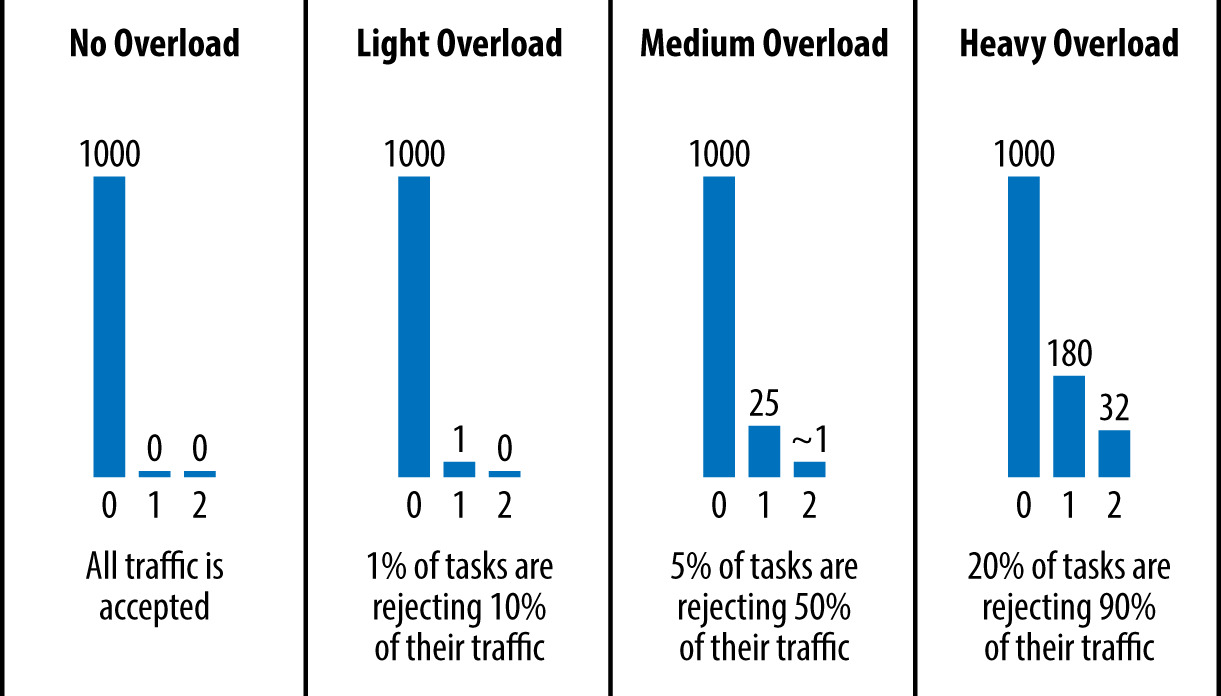
Figure 21.1: 不同情境下請求嘗試次數的直方圖
多層相依時的 retry#
失敗請求只在「緊鄰失敗那一層之上」retry。
例:Frontend → Backend A → Backend B → DB Frontend。若 DB Frontend 過載:
- B retry DB Frontend(依規則)
- B 放棄後對 A 回「overloaded; don’t retry」或降級回應
- A 對 Frontend 同樣處理
多層 retry 會引發指數爆炸。
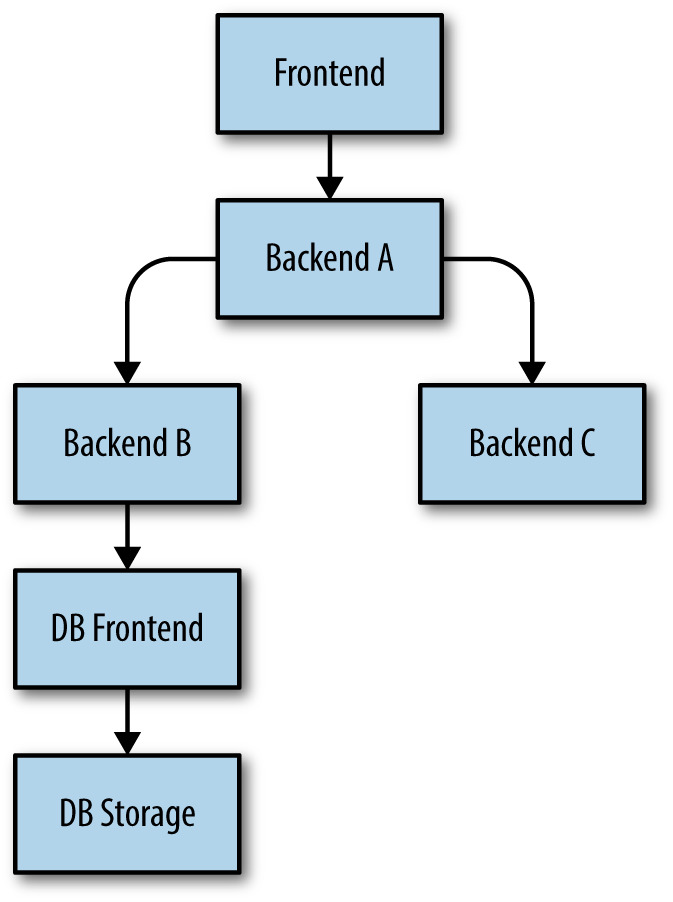
Figure 21.2: 相依層級堆疊
連線本身的負載#
大量 client 但每個都很少送請求時,health check 的 CPU 可能比實際處理請求還多。
緩解策略:
- 細調連線參數(降低 health check 頻率)或動態建/毀連線
- 對 batch job 突發建立大量連線:
- 把連線負載納入 LB 訊號 → 把流量導到其他 DC
- 強制 batch client 透過 batch proxy backend 轉送:proxy 變成 fuse,連線數對真正後端可控
結語#
個別 task 必須能保護自己:在 2x 甚至 10x 配置容量的流量下,仍要穩定服務該服務的部分,不能因 OOM 或 thrashing 而崩潰。
過載後端不該「全關」——應該繼續接受它能處理的份量,優雅拒絕其他。
負載平衡沒有銀彈——需要對系統與請求語意的深入理解。本章與第 20 章描述的技術會隨 Google 系統的演化繼續演化。