本章專注於資料中心內部的負載平衡——也就是把進到 DC 的請求流分配給各個後端 task 的演算法。
場景與名詞#
假設:
- 進入 DC 的請求流不超過 DC 容量(或僅短暫超過)
- 服務由多個同質、可互換的後端進程組成
- 最小服務通常 ≥ 3 個進程(少於此單機壞了就掉 50% 以上容量)
- 典型服務 100–1,000 個進程
- 最大可達 10,000+
- 後端稱 backend task;持有與後端連線並決定如何派發的稱 client task
- Client 與 backend 走 TCP / UDP 上的 RPC 協定
實務上請求進到 GFE(Google Frontend) 後,可能觸發長串的下游依賴呼叫。
理想狀態#
理想情況:所有後端 task 的 CPU 使用相等。
跨 DC 負載平衡只能送流量到「最高載 task 抵達容量上限」為止——之後就會浪費「其他 task 與最高載差距」的 CPU。
例:保留 1,000 CPU,實際只能用 700 CPU——這就是壞 LB 的隱性成本。
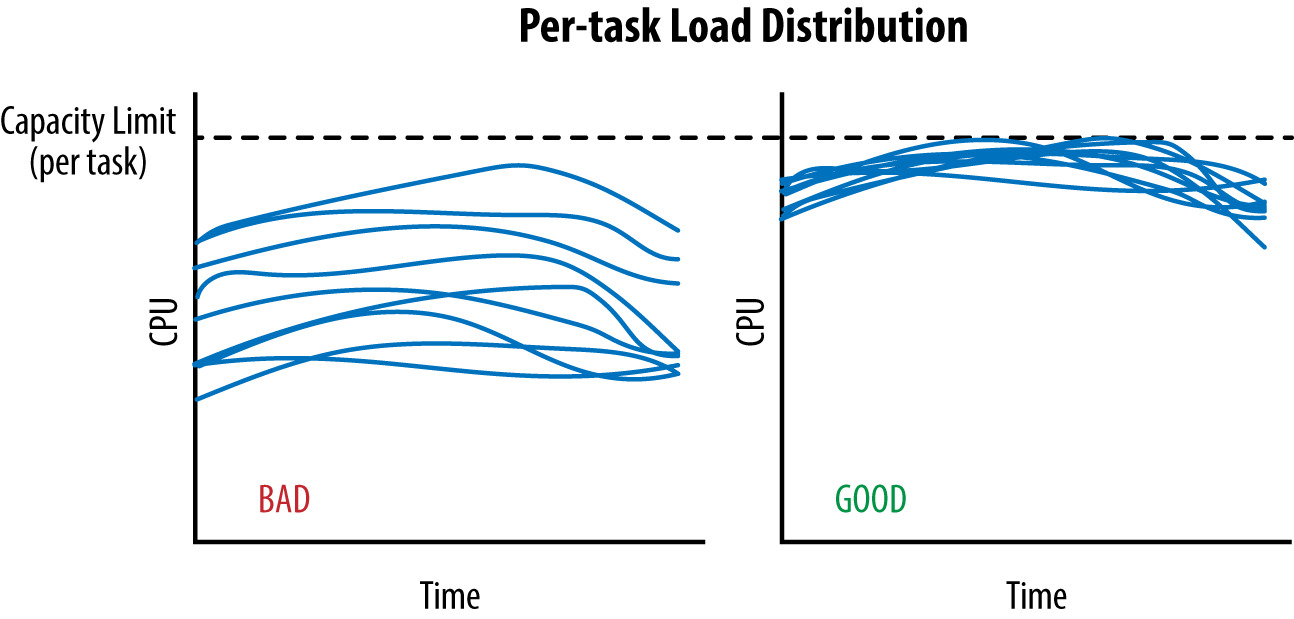
Figure 20.1: 跨時間的兩種 per-task 負載分布情境
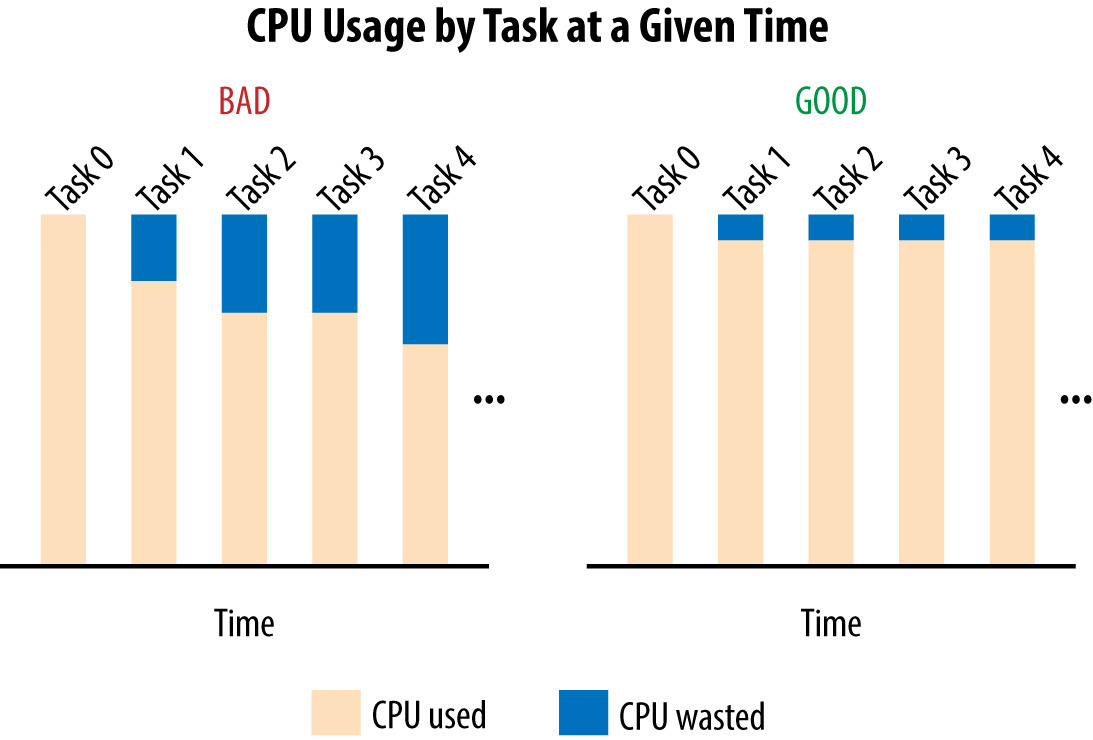
Figure 20.2: 兩種情境下 CPU 使用與浪費的直方圖
識別並避開壞 task#
流量控制(簡單版)#
- Client 追蹤對每個後端的進行中請求數
- 超過閾值(如 100)→ 視該後端為不健康、停送
- 副作用:簡易的負載分散
太簡單——後端可能在到達閾值前就已過載;某些長尾請求會占滿 active count 但其實只是慢,未必壞。
Lame Duck 狀態(堅實版)#
從 client 角度,後端有三種狀態:
- Healthy:正常處理
- Refusing connections:啟動中、關機中或異常
- Lame Duck:仍在監聽,但明確要求 client 停送新請求
Lame Duck 是「優雅關機」的核心:
- Scheduler 送 SIGTERM
- 後端進入 lame duck、要求 client 改送別處
- 已開始的請求繼續處理完
- Active 數降為 0
- 經過設定時間(通常 10–150s)後 clean exit
Google RPC 即使 inactive client 也會週期送 UDP health check,因此 lame duck 訊息可在 1–2 RTT 內傳開。
連線池的子集化(Subsetting)#
每個 client 對後端維持長連線。每條連線在兩端各耗 CPU 與記憶體(health check)——規模一大,浪費可觀。
Subsetting:限制每個 client 只連一小部分後端,避免「N×M 全連」的爆炸。
典型 subset 大小 20–100;下列情境需放大:
- Client 數遠少於 backend 數
- Client 之間有顯著 load 不均(爆量型請求)
隨機 subsetting 的失敗#
300 clients × 300 backends × 30% subset size 模擬:
- 最低載後端只拿到 63% 平均負載
- 最高載拿到 121%
把 subset 縮到 10% 更糟(50% vs. 150%)。
要讓隨機 subsetting 平均化,需把 subset 拉到 75%——已失去 subsetting 意義。
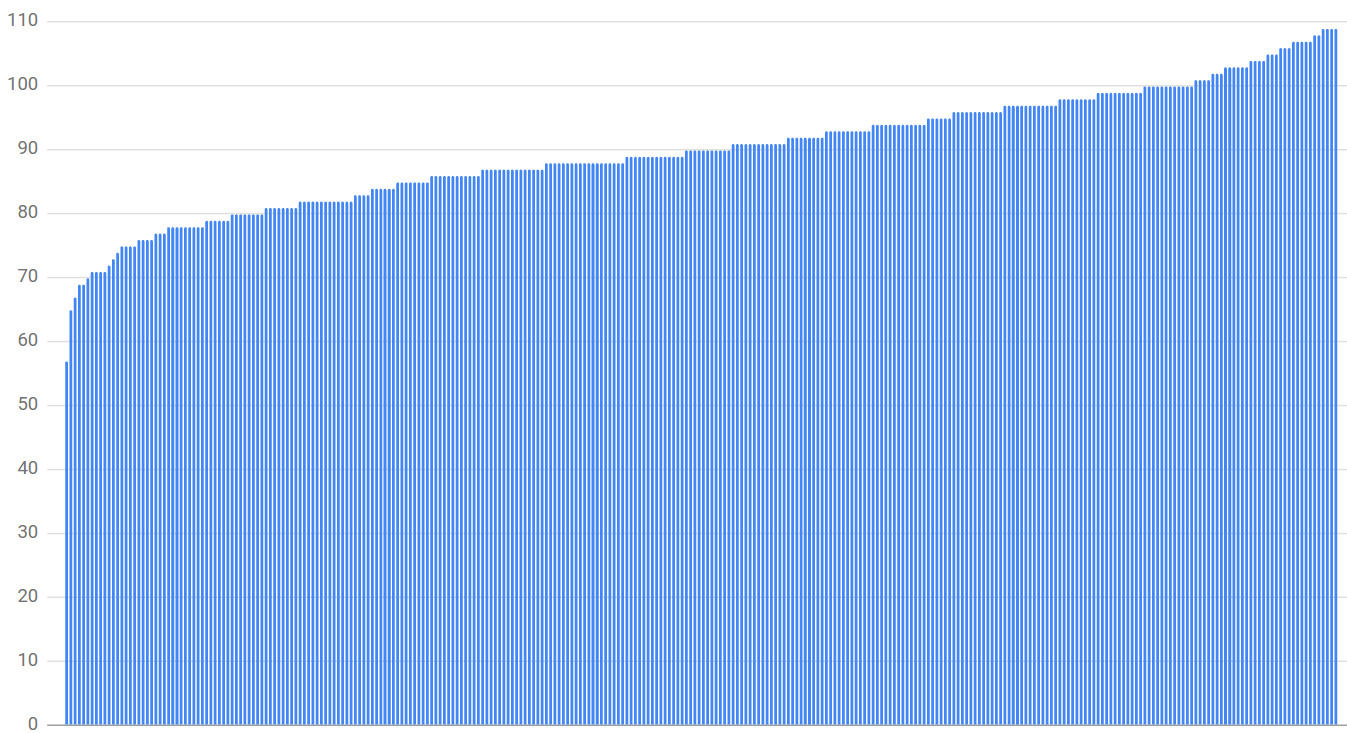
Figure 20.3: 300 clients × 300 backends、subset 大小 30% 的連線分布
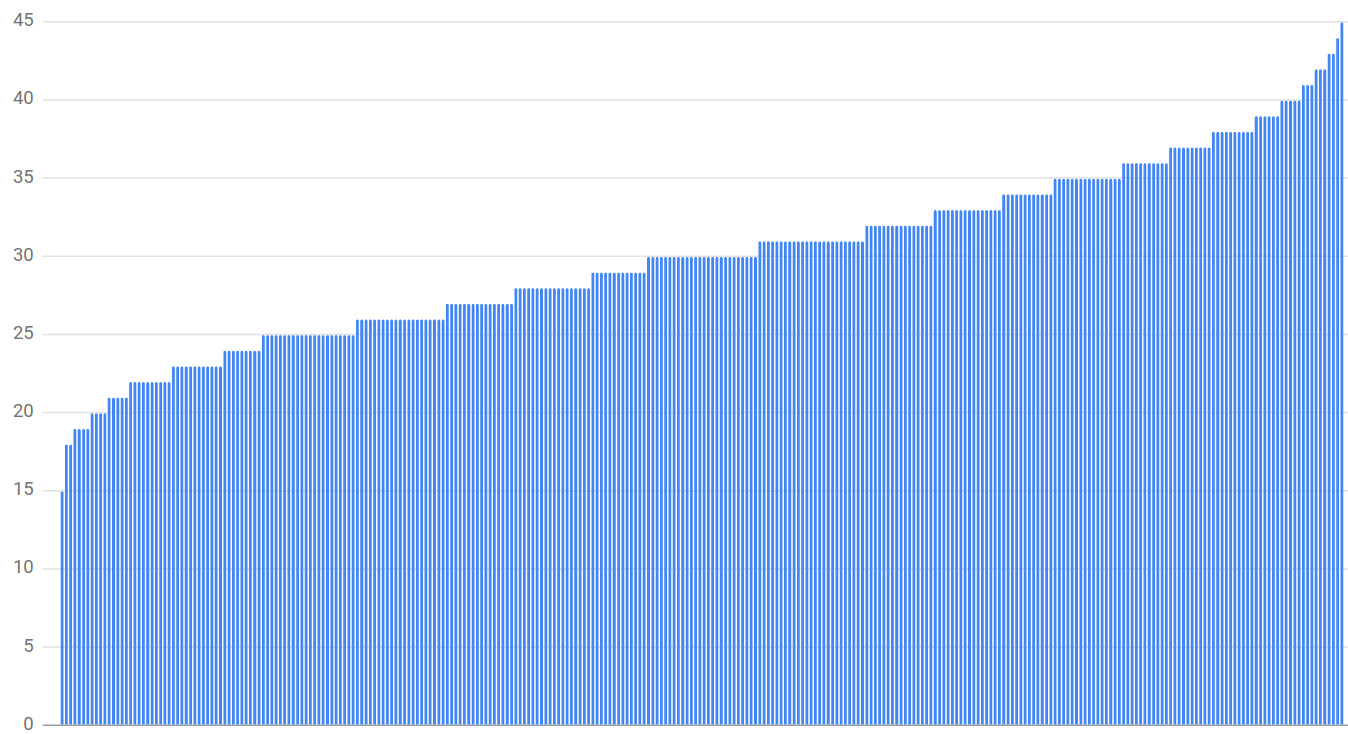
Figure 20.4: 300 clients × 300 backends、subset 大小 10% 的連線分布
確定性 subsetting(Google 的解法)#
把 client 分成「rounds」,每 round 內每個後端恰好分給一個 client(最後一輪可能不滿)。
def Subset(backends, client_id, subset_size):
subset_count = len(backends) / subset_size
round = client_id / subset_count
random.seed(round)
random.shuffle(backends)
subset_id = client_id % subset_count
start = subset_id * subset_size
return backends[start:start + subset_size]不同 round 用不同 seed 洗牌的關鍵理由:當某些後端故障,負載會被分散到「所有」剩餘後端,而不僅是同 subset 內。
此演算法能在 client / backend 數變化(restart、scaling)時,保持連線變動最小化。

Figure 20.5: 300 clients 用確定性 subsetting 連到 10/300 backends 的連線分布
負載平衡政策#
Simple Round Robin#
- 多年來最常見的政策
- 對 backend 狀態無感
- 仍能造成最高載 / 最低載 CPU 相差 2 倍的浪費
四大原因:
- 小 subset:少數重流量 client 連到的後端被打爆
- 請求成本差距大:最貴的請求可能是最便宜的 1,000 倍以上(「列出使用者 XYZ 今天收到的所有郵件」——多寡差很多)
- 機器差異:同 DC 內機器 CPU 不一定同等。Google 用「GCU(Google Compute Unit)」做統一量綱
- 不可預測因素:
- 鄰居(antagonistic neighbors):與不相干的 process 共享機器,效能可差 20%
- 重啟暖機:Java 等動態最佳化平台剛重啟需要更多資源
Least-Loaded Round Robin#
在 subset 中選「目前 active request 最少」的後端做 round-robin。
陷阱:
不健康的 task 可能用極低延遲回 100% 錯誤——「我壞了」回得很快 → Least-loaded 會把更多流量送過去(sinkhole)!
修正:把近期錯誤當成 active request 計入,自然把流量導離不健康 task。
兩大限制:
- Active request 數不是「真實能力」的好代理——I/O bound 的請求耗 CPU 很少,但會佔住 active count
- Client 看不見其他 client 對同一後端的負載
實務上 Least-Loaded RR 的最高 / 最低載差距仍接近 2 倍。
Weighted Round Robin#
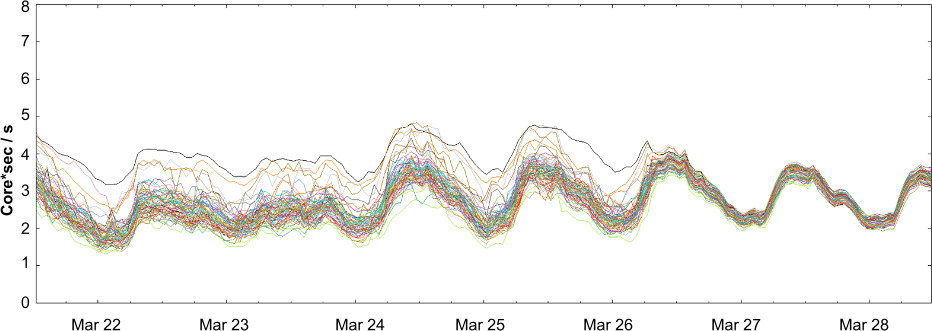
Google 採用:每個後端在回應(含 health check)裡帶回當前 QPS、錯誤率、利用率(通常 CPU)——client 依此週期性調整每個後端的「能力分數」。
成效顯著:切換到 Weighted RR 後,最高 / 最低載差距大幅縮小。