沒試過,就假設它壞了。 — 佚名
SRE 的核心任務之一是量化對系統的信心。信心可以分為兩種:
- 過去的可靠性:用監控資料分析歷史行為
- 未來的可靠性:用過去資料做預測
要讓「預測」有用,要嘛系統完全不變(不可能),要嘛所有變更都被充分描述——測試的角色,就是當變更發生時證明「某些等價性仍然成立」。
測試與 MTTR 的關係#
- 通過測試不能證明可靠;但測試失敗可以證明不可靠
- 監控能找到 bug,但反應速度受限於回報流程的 MTTR
- MTTR = 0 的 bug 最理想:當系統測試擋下 push、bug 永遠進不了生產 → MTBF 直接拉長
- MTBF 變長 → 開發者可以更敢推新功能 → 形成正向循環
測試的兩大類#
傳統測試(離線)#
從小到大的層次:
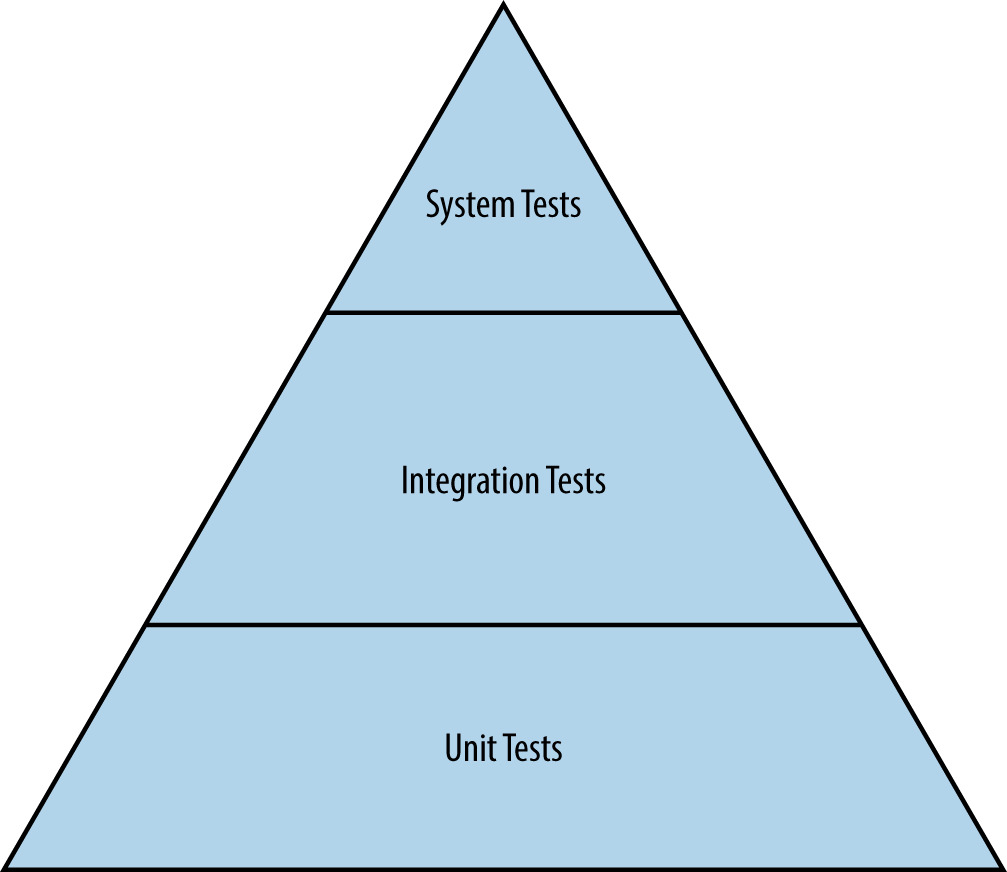
Figure 17.1: 傳統測試的層次
- 單元測試(Unit):最小單位(class、function)的正確性;也可作為規格
- 整合測試(Integration):用依賴注入(Dagger 之類)取代真實相依(mock)測試組裝後的元件
- 系統測試(System):端到端,含多種變形:
- 冒煙測試(Smoke):最簡單的關鍵行為,sanity check
- 效能測試(Performance):避免效能在不知不覺中退化(10 ms → 50 ms → 100 ms)
- 回歸測試(Regression):把歷史 bug 變成測試,防止重新引入
測試有成本:unit test 在 laptop 上毫秒完成,全系統測試可能花數小時並需要專用資源。意識到成本才能讓開發效率與測試資源都有效率。
生產測試(線上)#
對活的服務操作,與黑箱監控相似。
Configuration Test(設定測試)#
Google 把 web service 設定存進版控系統。每份設定有對應的測試,比較生產實際設定與檔案內容,回報差異。
因為作用在沙箱外,這類測試是「非密閉」的——但也因此能反映「實際生產 vs. 工程意圖」的偏差。
Stress Test(壓力測試)#
回答:
- DB 多滿時寫入開始失敗?
- 應用伺服器多少 QPS 開始超載?
許多元件不會優雅退化——超過某點就是災難失敗。壓力測試找出這些限制。
Canary Test(金絲雀測試)#
Canary 不是真正的「測試」——它是受結構化的使用者驗收。
把新版部署到一小撮伺服器、孵化一段時間(baking the binary),若無異樣再擴大。它不完美,不會抓到所有 bug。
漸進式 rollout 的合理節奏:第 1 天 0.1%,第 2 天 1%,第 3 天 10%,第 4 天 100%,並換不同地理區。
Bug 階數#
- 一階 bug:使用者請求遇上壞掉的程式碼——可由 log 重組為迴歸測試
- 二階 bug:請求隨機破壞了未來請求會看到的資料
- 三階 bug:破壞的資料剛好是另一個請求的 valid 識別子
多數 bug 是一階。高階 bug 必須在 release 期間抓到——否則運維負擔會爆炸式增加。
建立測試與 build 環境#
當你接手一個現有專案、測試覆蓋很差時,從高影響、低成本處下手:
- 程式庫能優先排序嗎?「全部都高優先 = 都不高優先」
- 哪些功能是業務 / 任務關鍵(如計費)?
- 哪些 API 被其他團隊整合?破壞它會誤導他們
把每個回報的 bug 變成測試——一開始測試會失敗,修完 bug 通過,自然累積回歸測試套件。
基礎建設要件:
- 版控系統
- 持續 build 系統:每次提交都 build 並跑測試
- 一壞就通知並所有人停下手邊事優先修——讓「主線永遠可運行」成為共識
- Bazel 一類工具:建依賴圖,只 rebuild 受影響部分,可重現
規模化的測試#
測試 SRE 工具#
SRE 工具的兩個特徵:
- 副作用都走在主流、有覆蓋的 API 上
- 與使用者前台之間有現有的 release barrier 隔離
屏障防禦危險軟體#
為了縮短維護時間,DB 引擎可能允許「暫停 transaction」——但若批次更新工具誤跑在使用者前台 replica 會災難。
設計:
- 用獨立工具在 replication 設定加屏障,使 replica 無法通過健康檢查 → 不釋出給使用者
- 危險軟體啟動時檢查屏障,只在「不健康」的 replica 工作
- 用既有的健康驗證工具移除屏障
自動化工具#
特徵:
- 對既有 API 操作
- 其目的是 side effect——對其他 API client 而言是不可見的不連續
自動化工具會改變另一個自動化工具運作的環境——甚至兩者同時改對方環境(容器搬移工具被 rebalance、rebalance 工具被升級)。
循環相依要靠 API 的 restart 語意、測試覆蓋、獨立健康檢查避免。
災難測試#
- 離線災難復原工具相對容易測試(計算 checkpoint → 用既有驗證工具載入 → 觸發乾淨啟動)
- 線上修復工具更難:因主流 API 仍在執行,會有競態
- 通常需要打造統一儀器化 binary 才能觀察 transaction
用統計性測試#
Lemon(fuzz)、Chaos Monkey、Jepsen 不是可重現的測試,但仍有價值:
- 記下所有隨機動作(用 RNG seed)
- 用 log 改寫成 release test,多跑幾次可估「修復信心」
- 觀察故障的變形可定位可疑區域
- 後續執行可能暴露更嚴重的衝擊
測試的速度需求#
假設 21,000 個簡單測試、你可以接受每 100 次 patch 拒絕 1 次(含偽陰性)——
反推每個測試需在 99.9999% 的時間正確執行。這個準確度極高。
測試的「截止時間」#
- 簡單測試:自帶完整環境、幾秒完成 → 給工程師互動式回饋
- 大型測試:跨多 binary、多容器,啟動需以秒計 → 改說「這份程式碼還沒準備好被 review」
- 重點:測試結果要在工程師切換上下文之前到位,否則「下個 context 可能是 xkcd compiling」
推到生產#
生產設定常與開發者 source code 分開儲存與測試。在 SRE 模式下,這種分離會妨礙描述「生產實情 vs. 應用行為」的一致模型——導致無法消除遷移風險、架構無法演進。
解法:統一版控、統一測試。
配置檔的風險分類#
配置檔有兩種類型:
- 為了壓低 MTTR 而存在:僅在故障時修改 → 修改頻率低於 MTBF;每次修改是否最優都帶有不確定性
- 每次應用發佈都會跟著改:頻率高 → 必須與應用發佈受同等嚴格的測試,否則它會主導整站可靠性
對策:
- 每份配置檔分類清楚
- 每份配置檔測試覆蓋足以支援例行編輯
- 發佈前等待 release test 完成
- 提供「break-glass」機制讓緊急時可直接推:但要很吵(如自動開 bug)
Break-glass 不該停測試——讓測試繼續跑、把推送事件與測試結果關聯,事後可快速跟進第二次修正推送。
設定檔的整合測試#
- 用解譯式語言(Python)寫設定 → 載入即執行 → 執行時間沒有上限,需嚴格 deadline
- 用 YAML + 嚴格 parser(Python 的
safe_load)→ 有限上限,但 schema 錯誤仍需另外處理 - 用 protocol buffers:schema 預先定義、載入時自動驗證 → 最少瑣事 + 有界執行時間 → 推薦
期待測試「會」失敗#
一年一次發佈時,前一次 release 的可靠性資料對下一次幾乎無關。
發佈頻率越高,間隔變更越小,問題可被精準對應回根因。
適度提高頻率反而提升可靠性——但提高頻率本身會增加使用者可見的失敗機會,需用測試覆蓋與監控配合控制節奏。
生產 Probe:填補測試與監控之間的空白#
對請求做三分:
- 已知壞請求
- 已知好請求、可重放到生產
- 已知好請求、不可重放到生產
同一份請求集可同時當成整合測試、release test、與監控 probe。但 probe 跑在生產,意味著它測試的是「真正活著的設定組合」——而那是 release test 沒測過的。
Probe 永不該失敗。失敗代表 frontend / backend API 在生產與 release 環境不等價——通常等於系統壞了。
更新器會逐步替換應用與 probe,使「新 / 舊 probe × 新 / 舊應用」共四種組合持續產生:
- 偵測到某組合錯誤即可自動 rollback
- 在新版實例變健康前不導使用者流量過去
- 等工程師有空慢慢診斷
Release test 常用「假後端」與真實前端組合;但 release 用的是建構時的 hash,生產卻是前後端各自獨立發佈節奏。只有監控 probe 才能涵蓋真實的版本組合。
結語#
測試是工程師能投資的、最有回報的可靠性手段。它不是專案一兩次的活動——而是持續性的工作。
寫好測試需要可觀的工程量;建立並維護鼓勵測試文化的基礎建設同樣需要。但在工程裡:沒有量測就沒有理解,沒有理解就無從修復。