當專家不只是了解系統「應該怎麼運作」——專業是從研究「為什麼它沒運作」中累積的。 — Brian Redman
事情走對的方式,只是事情走錯的方式的一個特例。 — John Allspaw
疑難排解常被視為某些人「天生會」的能力——其實是可學、可教的。本章拆解疑難排解的通用方法,讓新手也能系統化地處理問題。
理論:假設—演繹法(hypothetico-deductive)#
把疑難排解理解為反覆假設與測試:以系統的觀察為起點,依領域知識提出可能原因,逐一驗證或否證。
理想流程:
- 問題回報 → 取得症狀
- 檢視(Examine):看遙測、日誌
- 診斷(Diagnose):結合系統知識提假設
- 測試 / 處置(Test / Treat):對照觀察驗證假設,或安全地改動系統觀察結果
- 找到根因 → 修復 → 寫事後檢討
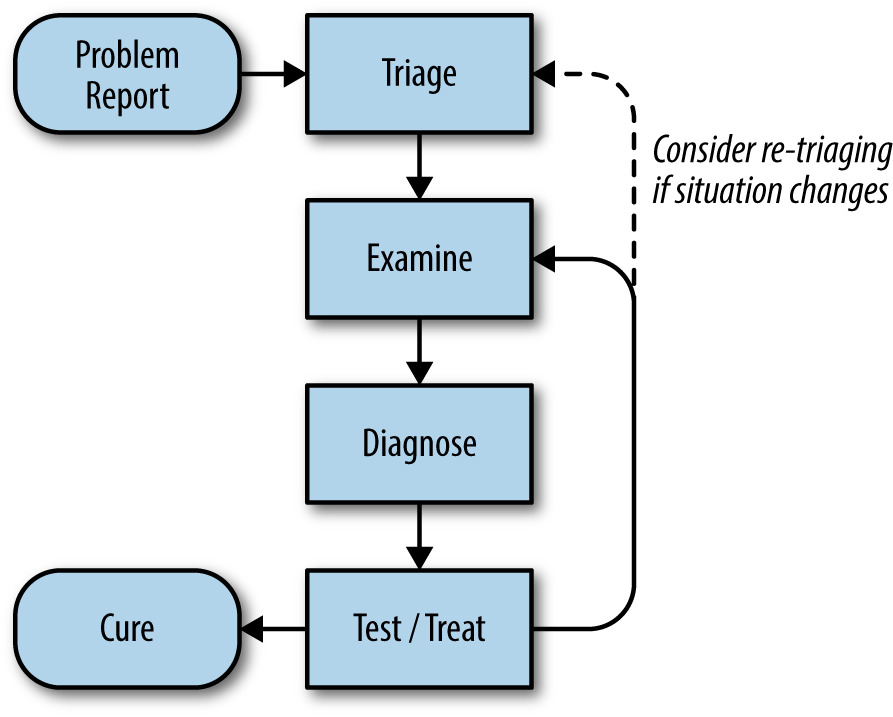
Figure 12.1: 疑難排解流程
常見陷阱#
- 看到不相關的症狀或誤解指標的意義 → 追錯方向
- 不知道如何安全地改動系統與輸入做測試
- 假設過於離奇;或抓住「過去某次原因」就認為這次也是同一個
- 把「相關」當成「因果」——大型系統的指標多到必有巧合相關
醫學箴言:「聽到馬蹄聲先想馬,不要先想斑馬」——失敗的機率不均勻,偏好簡單解釋(Occam’s razor),但也要記得多個小毛病加總可能比單一稀有原因更可能。
實務步驟#
1. 問題回報#
好的問題回報應包含:
- 預期行為
- 實際行為
- 如可能,重現步驟
用 bug 系統儲存,可搜尋。
Google 的習慣是「每個問題都開 bug」,即便來自郵件或 IM。避免直接私訊找特定工程師——這會:
- 多一步轉錄
- 報告品質較低且不可見
- 把負擔集中在「報告者剛好認識的人」而非當值者
2. Triage(分流)#
大型事件的第一直覺常是「快點找根因」——忽略它。
第一要務是讓系統在當前情況下盡可能運作:切流量、丟流量避免連鎖故障、關非必要子系統。先止血,再找根因。
新手飛行員的第一守則:先把飛機開穩,疑難排解次之。如果 bug 可能導致不可逆的資料毀損,凍結系統好過繼續惡化。
3. Examine(檢視)#
工具箱:
- 監控(第 10 章):時序圖、跨指標相關性
- 日誌:跨多個 process 拼出時間軸;用 Dapper 追蹤分散式請求
- 暴露當前狀態:Google 伺服器內建端點,顯示近期 RPC 樣本、錯誤率與延遲直方圖、設定值
- 儀器化 client:實際發請求觀察元件回應
日誌設計建議:
- 多層 verbosity,且可動態調整而不需重啟
- 高量服務考慮統計取樣(如 1/1000 取樣)
- 設計「選擇語言」讓你可以即時拉出「
Set RPC payload < 1024 bytes 的請求」這類查詢
4. Diagnose(診斷)的通用技巧#
簡化與化約#
- 元件間應有清晰介面與已知轉換
- 對每個元件注入已知測試資料,檢查輸出是否符合預期(黑箱測試)
- 二分法(bisection):在大型系統中,把系統對半切、檢查中間通訊路徑
- 大量階層時用「線性走完整堆疊」較慢但保證;超大型則 bisection
「什麼、哪裡、為什麼」#
故障系統通常仍在做某件事——只是不是你要的。問:
- 它正在做什麼?
- 哪裡耗掉了資源?輸出去了哪?
- 為什麼?
範例(Spanner 高延遲):
- 為什麼延遲高?→ Spanner server 把 CPU 用光,無法處理請求
- CPU 用在哪?→ profile 顯示在排序 checkpoint 到磁碟的 log entries
- 哪段程式碼?→ 用正則表達式比對 log 檔名時
- 解法:改寫 regex 避免回溯,或改用 RE2(保證線性時間)
「最後動了什麼」#
系統有慣性——一個正常運作的系統會持續正常,直到被外部力量推動。最近的變更是定位問題的好起點。
在儀表板上標註版本部署、配置變更的開始與結束時間,便於把「錯誤率變化」與「事件」對齊。
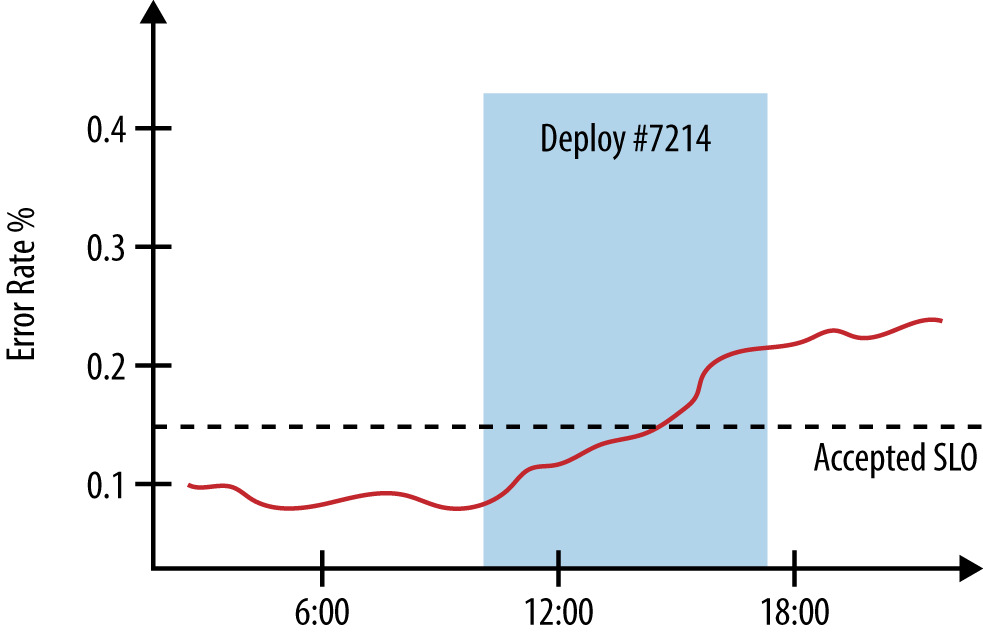
Figure 12.2: 錯誤率與部署起訖時間對照圖
5. Test and Treat(測試與處置)#
設計實驗時的考量:
- 理想的測試互斥——能同時排除一組假設、確認另一組
- 由可能性高的先測,但要考量測試本身的風險(如:先測網路連通,再測 firewall 規則)
- 注意混淆因子:firewall 規則只允許特定 IP,從你自己的 workstation ping 失敗不能下結論
- 主動測試會改變未來結果:開 verbose log 本身可能讓延遲問題更嚴重
- 競態條件、deadlock 難以重現,常只能取「暗示性證據」
**詳細紀錄你想了什麼、測了什麼、結果是什麼。**用共享文件或聊天室寫,自帶 timestamp,事後檢討用得到,也讓其他人看到當下進度。
負面結果是寶#
「沒有達到預期效果」的實驗結果也是寶。負面結果可:
- 解決爭議(兩個看似合理的設計,到底選哪個)
- 替後人省下重做的成本
- 留下工具與基準測試
- 提升業界數據驅動文化
對任何不提及失敗的設計文件、效能評估都要保持懷疑。
Cure(治癒)#
理想上你已縮小到單一根因,但在生產系統中完全證實很困難:
- 系統複雜,多個次因子加總才致命
- 在生產重現問題不一定可行;有非生產環境會比較好
找到根因後,寫事後檢討:哪裡壞了、怎麼追的、怎麼修的、怎麼防止再發。
案例:App Engine 客戶的延遲爆炸#
客戶報告 App Engine 上的 app 延遲、CPU、process 數突增——但既無流量飆升,也無近期變更。
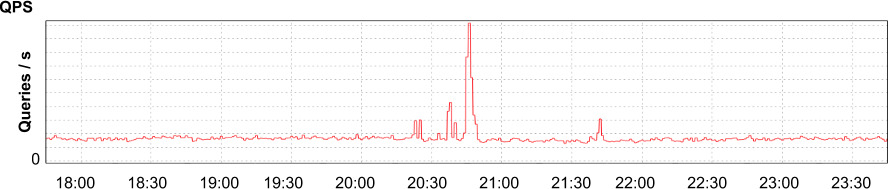
Figure 12.3: 應用的每秒請求數:短暫尖峰後恢復正常
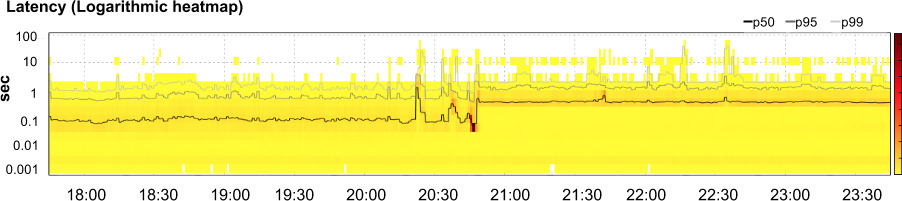
Figure 12.4: 應用延遲:50/95/99 百分位(線)與請求落入各延遲分桶的 heatmap
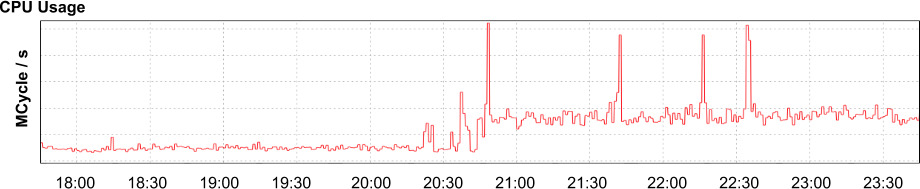
Figure 12.5: 應用的整體 CPU 使用率
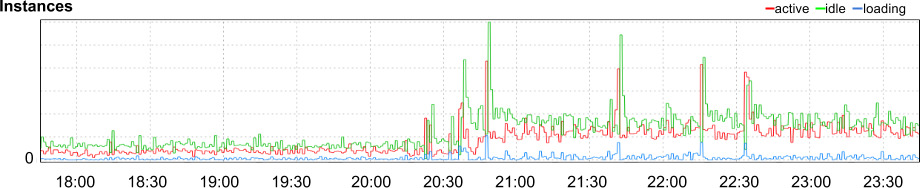
Figure 12.6: 應用的實例數
排查流程:
- 看遙測:延遲增近一個量級,CPU 與 process 數約 4 倍
- 排除流量說與環境變更說(時間對不上、其他 app 沒事)
- App Engine 開發者注意到一個資料儲存 API call(
merge_join)爆增——通常代表索引不佳 - 但用 Dapper 追蹤後發現:靜態資源(圖片)也變慢——
merge_join假設被推翻 - RPC 都很快(到 memcache),但 app 開始處理請求到第一個 RPC 之間有 250 ms 空檔——做了「某些事」
- 因 App Engine 不能 profile 使用者程式碼,Dapper 也只追 RPC——這段空白無從得知
短期止血:建議客戶換更高 CPU 規格的實例,延遲回到可接受水準(但不理想),客戶完成新版上線後再深入。
最終根因:
- 一個長期 bug——某特定路徑被存取時會在 datastore 建立一個 whitelist 物件
- 上線前自動安全掃描器在半小時內產生了上千個 whitelist 物件
- 每次請求都要對全部 whitelist 物件做檢查(in-memory for-loop,O(n))
- 修 bug、清掉那些物件 → 效能恢復
教訓:從記憶體 cache 為了避開 RPC 開銷而 in-memory linear scan 是常見反模式——資料少時不影響,多了就指數惡化延遲。
讓疑難排解更簡單#
從設計階段就為可觀察性投資:
- 每個元件內建白箱指標與結構化日誌
- 元件間用可觀察、定義明確的介面
- 跨服務沿用同一個 request ID,省去「對 log 比 RPC」的力氣
程式碼變更與環境變更的簡化、控制、記錄會直接降低未來疑難排解成本。