願請求滾滾流,願 pager 永靜默。 — SRE 傳統祝福語
監控是「生產需求金字塔」的最底層;本章透過 Google 內部的時序監控系統 Borgmon(開源近親是 Prometheus)來說明如何從時序資料做有效告警。
為什麼舊的「腳本巡檢」做法不夠#
在 Google 規模下,為單機故障發告警是不可接受的——噪音太高、無從採取行動。系統設計應該天生對單機故障有韌性,監控也應能聚合訊號、剔除離群點。
舊範式:自製腳本檢查回應 → 觸發告警;視覺化與告警分屬兩個系統。
新範式(Borgmon):
- 時序資料蒐集為一等公民
- 告警與圖表都從同一份時序計算出來
- 用「白箱監控」共通格式批次採集,省掉建立子行程與網路連線的成本
應用程式打點#
Borgmon 不主動探測,而是各 binary 透過 HTTP
/varz端點以鬆散的 key=value 格式自曝指標。例:
http_requests 37 errors_total 12 http_responses map:code 200:25 404:0 500:12程式裡只需要一個 declaration,因此加新指標的成本極低。
支援 map-valued 變數(自帶 label 與直方圖),其代價是「指標定義與規則使用解耦」,需用驗證工具與規則生成器維持品質。
蒐集與儲存:時序資料的多維矩陣#
- Borgmon 以服務發現得到目標清單,週期性抓取
/varz,並把抓取時間錯開以避免同步效應 - 每個目標還會額外記錄「synthetic 變數」:是否解析成功、是否回應、是否健康、何時抓完——這些都可被規則直接拿來用
- 資料以「時序」儲存:每筆是
(timestamp, value),每條時序由一組 labelset 唯一識別 - 記憶體中以固定大小的 time-series arena 存放,過舊資料被 GC
- 一個資料點約 24 bytes
- 12 小時、每分鐘一筆、100 萬條時序 ≈ 17 GB RAM
- 更舊的資料定期 archive 到 TSDB(外部時序資料庫):較慢但便宜得多
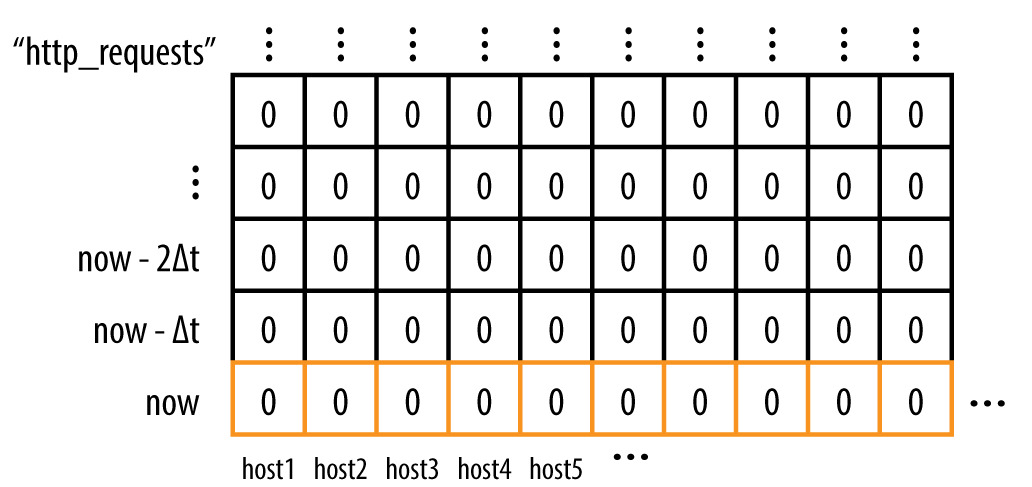
Figure 10.1: 依原始主機標記錯誤的時序
Label 與向量#
{var=http_requests, job=webserver, instance=host0:80, service=web, zone=us-west}
Figure 10.2: 時序示意
省略部分 label 即可查詢一個 vector(多條時序),加上 [10m] 可拉出過去 10 分鐘的歷史視窗。
Label 可來自:
- 目標名稱(job、instance)
- 目標本身(map-valued 變數)
- Borgmon 設定(位置標註、重新標籤)
- Borgmon 規則本身的運算結果
規則運算#
Borgmon 本質上是一台可程式化計算機——資料蒐集與儲存只是讓這台計算機適合做監控用。
規則用簡單代數表達式從現有時序計算新時序,可跨時間軸(歷史)與空間軸(不同 label 子集)。
聚合(aggregation)是核心#
例:算「叢集等級 HTTP 錯誤率」步驟:
- 將所有 task 各 response code 的 rate 聚合
- 把非 200 的 rate 加總
- 除以總請求 rate 得到比率
{var=task:http_requests:rate10m,job=webserver} =
rate({var=http_requests,job=webserver}[10m]);
{var=dc:http_requests:rate10m,job=webserver} =
sum without instance({var=task:http_requests:rate10m,job=webserver});命名約定:
聚合等級:變數名:操作——可讀性極佳。例:dc:http_errors:ratio_rate10m讀作「datacenter HTTP errors 10-minute ratio of rates」。
Counter 比 Gauge 好#
採集 Borgmon 風格資料時優先用 counter(單調不減),不用 gauge(任意值)。
兩次取樣之間發生的活動會被 gauge 漏掉,counter 不會。
告警#
{var=dc:http_errors:ratio_rate10m,job=webserver} > 0.01
and by job, error
{var=dc:http_errors:rate10m,job=webserver} > 1
for 2m
=> ErrorRatioTooHigh特性:
- 規則為 true 才觸發告警;可設「最短持續時間」(建議至少兩個規則執行週期),避免漏抓造成的偽告警
- 觸發時填入上下文模板(job、值、規則名等),透過 RPC 送往 Alertmanager
Alertmanager 的職責:
- 路由告警到正確的人或工單
- 在某些告警發生時抑制另一些
- 從多個 Borgmon 收到相同 labelset 時去重
- 依 labelset 做 fan-in / fan-out
告警分類(呼應第 6 章):
- Page-worthy → On-Call
- 重要但非緊急 → 工單
- 其他 → 留作儀表板資訊
監控拓撲的分片#
不要用一台 Borgmon 統管全球——會成為瓶頸與單點。
典型部署:
- 每個資料中心一台 Borgmon
- 兩台以上 global Borgmon 做頂層聚合(避免單點與維護期間斷線)
- 超大型服務再切「純抓取層 + 聚合層」
Borgmon 之間以串流協定傳輸時序資料,比抓 /varz 文字格式省 CPU 與頻寬。上層 Borgmon 可過濾下層的資料以免 arena 爆掉,形成可下鑽的多級聚合快取。
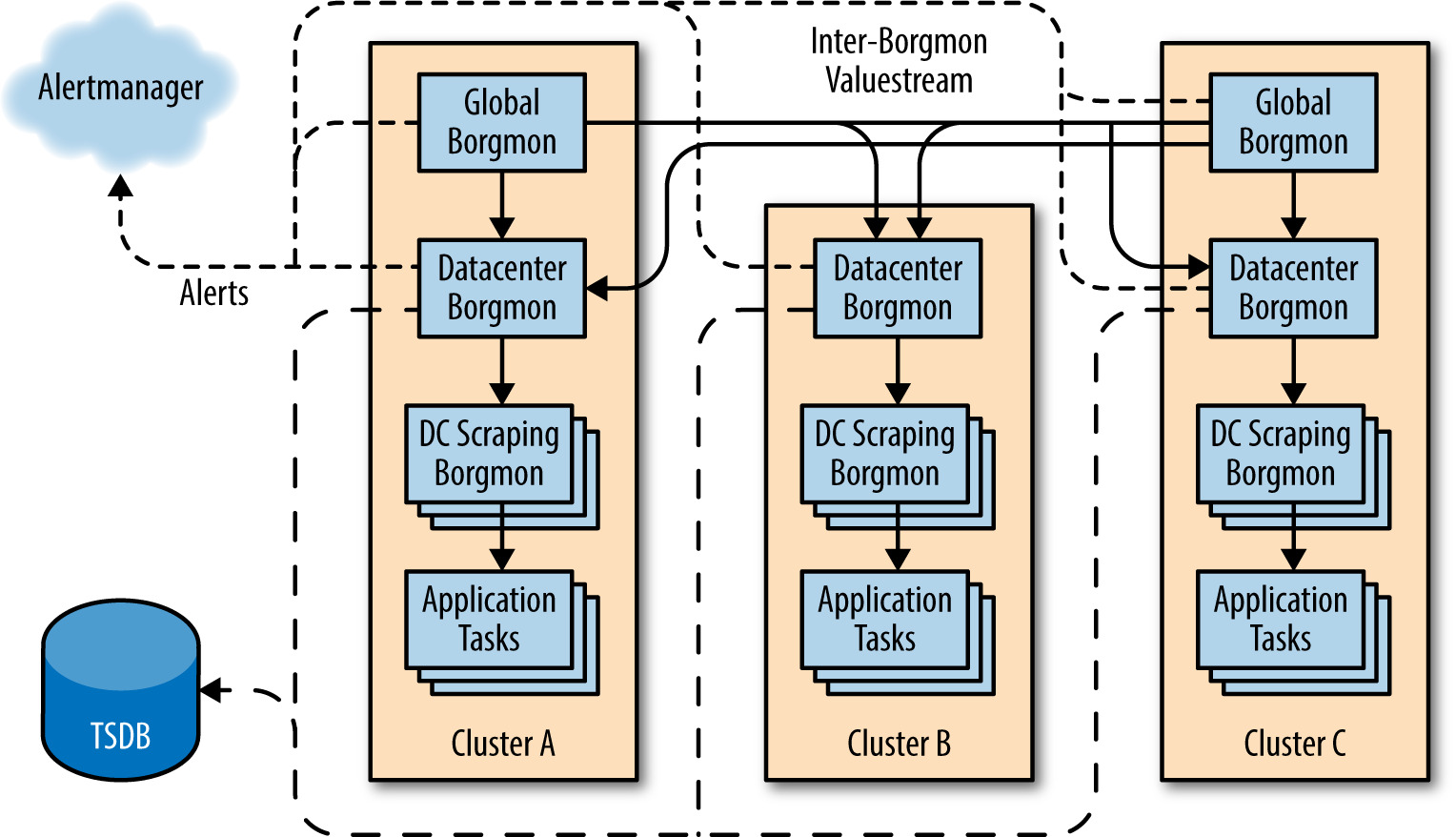
Figure 10.3: 跨三個叢集的 Borgmon 階層資料流模型
黑箱監控:補白箱看不到的地方#
白箱看不到「根本沒進到伺服器的請求」(DNS 失敗、伺服器全掛掉)——你只能對「預期得到的失敗」發告警。
Google 用 Prober:
- 對目標執行協定檢查、回報結果
- 可驗證 response payload 是否符合預期,並把延遲分桶為時序
- 同時對「前端域名」與「LB 後的伺服器」探測 → 可分辨是 DC 故障還是整個流量路徑故障
維護告警配置#
規則與目標解耦——同一套規則可套用到多個目標,避免大量重複。
- 模板系統建立規則函式庫,可重用
- 用合成時序資料寫單元 / 回歸測試
- 持續整合服務把配置打包推送,並在 Borgmon 上線前驗證
兩種模板會自然演化出來:
- 依函式庫(HTTP server、RPC、儲存 client)暴露的 varz 推導模式
- 依服務拓撲(task → shard → DC → global)做聚合的通用規則
Label 用途歸納:
- 描述資料切分(HTTP response code)
- 描述資料來源(instance、job)
- 描述聚合位置(zone、shard)
十年後#
時序資料 + 中央規則運算的設計讓告警維護成本與服務規模脫鉤——使監控可永續經營。十年後雖然 Google 內部仍演進,但 Prometheus、Riemann、Heka、Bosun 等開源系統已把這個範式推廣給整個業界。