**發佈工程(Release Engineering)**是一門相對年輕的軟體工程學科——簡而言之,就是「建構並交付軟體」。本章說明 Google 對發佈工程的哲學、工具與和 SRE 的合作關係。
可靠的服務需要可靠的發佈流程。SRE 必須確信使用的 binary 與設定都以可重現、自動化的方式建構——發佈不該是「獨一無二的雪花」。
發佈工程師的角色#
發佈工程師對源碼管理、編譯器、build 配置語言、自動化 build 工具、套件管理器、安裝器都熟稔,並橫跨開發、設定管理、測試整合、系統管理與客服多個領域。
在 Google:
- 用工具量測發佈速度、追蹤建構選項使用情形
- 定義工具的最佳實踐(編譯旗標、build ID 標籤格式、必要的 build 步驟)
- 與 SRE 共同設計金絲雀(canary)、不中斷推送、出問題回滾的策略
四個哲學原則#
1. 自助服務模型(Self-Service)#
規模化的前提是團隊自給自足。發佈工程提供工具與最佳實踐,讓產品團隊自己掌控發佈節奏——多數專案只在出問題時才需工程師介入。
2. 高速發佈(High Velocity)#
愈頻繁地發佈,版本間差異愈小——測試與除錯更容易。
- 部分團隊每小時 build 一次,從候選池中挑要部署的版本
- 部分團隊採 Push on Green:通過所有測試自動推上線
3. 封閉式 Build(Hermetic Build)#
兩個人在不同機器上以同一 revision 建構,必須得到相同結果。
Build 不依賴 build 機器上裝了什麼,而是依賴明確版本的編譯器與依賴。
修舊版本的 bug 時用「Cherry pick」:
- 在原始 revision 上重新 build
- 把後續特定變更挑選進來
- Build 工具本身也與專案 revision 對齊,避免今天的編譯器去 build 上個月的程式碼
4. 政策與程序的強制執行#
以多層存取控制把關下列動作:
- 核可程式碼變更(透過程式庫中的配置檔管理)
- 指定發佈過程的動作
- 創建新版本
- 核可 integration proposal 與後續 cherry picks
- 部署新版本
- 改動 build 配置
所有變更幾乎都要 code review。自動化系統會產生「本次發佈含哪些變更」的報告,便於 SRE 在出狀況時快速定位。
持續 Build 與部署:Rapid#
Google 的自動化發佈系統叫 Rapid,整合了多個 Google 技術。
Building#
- Blaze(開源版 Bazel)支援 C++、Java、Python、Go、JavaScript
- 工程師定義 build target 與相依,Blaze 自動處理相依鏈
- Binary 內建顯示 build 日期、revision、build ID 的 flag,便於追溯
Branching#
- 程式碼全部進主線(mainline)
- 主要專案不直接從主線發佈:從主線特定 revision 分支,從不合回主線
- Bug 修在主線、用 cherry pick 進分支——確保每次發佈內容明確、不會夾帶未預期變更
Testing#
- 主線變更時持續跑單元測試
- 建議「持續測試的 target 與發佈 gate 的 target 一致」
- 發佈時在 release branch 重跑單元測試並留稽核軌跡(cherry-picked 內容可能在主線從未出現過)
- 另有獨立環境跑系統級測試
Packaging:MPM#
軟體以 Midas Package Manager(MPM) 散佈:
- 用 Blaze 規則組裝
- 套件有名稱(如
search/shakespeare/frontend)、唯一 hash 版本、簽章 - 用 label(如
dev、canary、production)標示套件目前位於發佈流程哪個階段 - 把舊 label 套到新套件,會自動「移動」——客戶端取 canary 自動拿到最新 canary
Rapid 的運作#
Rapid 以 blueprints 配置,每個專案有 workflow 定義發佈期間的動作(可序列、可並行、可呼叫其他 workflow)。Rapid 將任務以 Borg job 派發到生產伺服器,所以可同時處理上千次發佈。
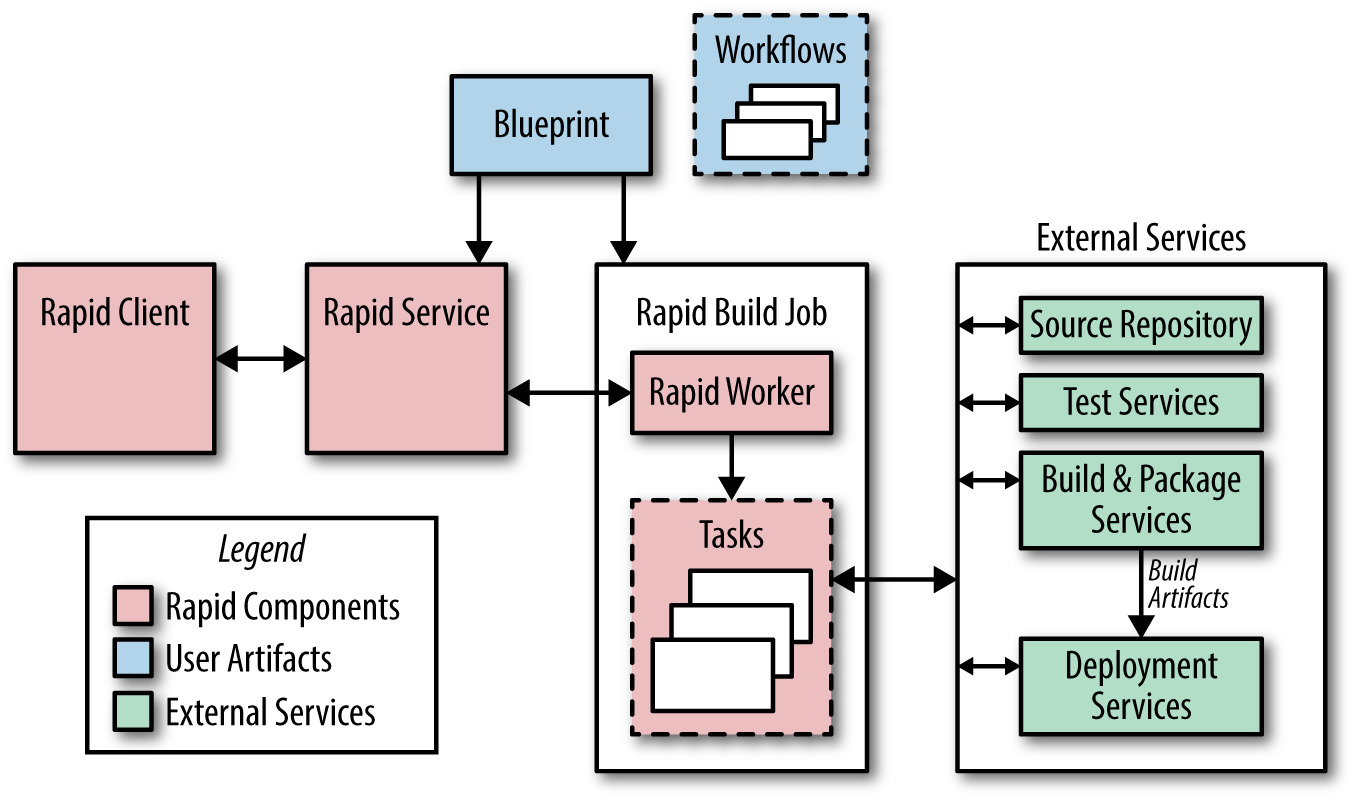
Figure 8.1: Rapid 架構主要元件的簡化視圖
典型流程:
- 用 integration revision 建立 release branch
- 用 Blaze 並行編譯與跑單元測試(在獨立環境而非 Rapid workflow 所在的 Borg job)
- Artifact 進入系統測試與 canary 部署
- 全程留 log;產生「自上次發佈以來變更」的報告
Deployment#
- 簡單部署直接由 Rapid 驅動(更新 Borg job、指定新 MPM 套件)
- 複雜部署使用 Sisyphus——SRE 開發的通用 rollout 框架:以 Python 類別擴展、有儀表板與細粒度控制
部署流程應配合服務的風險輪廓:
- 開發 / pre-prod 環境:每小時 build、測試通過自動推
- 大型使用者前台:先一個 cluster,再指數成長至全網
- 敏感基礎建設:橫跨數天、跨地理區交錯推送
設定管理#
設定變更是一個容易引發不穩定的來源。Google 的方案演進出幾種模型,全部都把設定存進主程式碼倉庫、強制 code review:
- 直接用主線設定:開發者改 head 上的設定檔,binary 不重 build
- 優點:簡單
- 缺點:易發生 checked-in 版本與 running 版本不一致
- 設定與 binary 同包進 MPM:適合設定少或每次發佈都會動的專案
- 優點:部署只需安裝一個套件
- 缺點:兩者綁死
- 設定獨立打包為「configuration package」:發揮 hermetic 原則
- 用 build ID 重建特定時間點的設定組合
- 可獨立 cherry pick 設定變更(不必重 build binary)
- 用 MPM label(如
much_ado)標示哪些版本要同時安裝
- 從外部儲存讀設定:設定需頻繁或在 binary 運行中動態變動 → 存 Chubby、Bigtable 或來源檔案系統
沒有單一最佳解。專案擁有者依需求自行選擇。
結語#
不只是 Googler 的事#
- 各規模公司都會面對相同問題:版本控管、build 模型、頻率、設定管理政策、要量什麼指標
- Google 自製工具是「規模逼出來的」,但每家公司都該先定義發佈流程,再考慮自動化
早早投入發佈工程#
發佈工程經常被當作事後考量——在系統規模與複雜度增長下,這必須改變。
- 從產品開發週期一開始就編列發佈工程資源
- 開發者、SRE、發佈工程師三方協作,不要「丟過牆」
- 早期投入便宜,事後改造昂貴