除了黑魔法之外,就只剩自動化與機械化了。 — Federico García Lorca
對 SRE 而言,自動化是力量的放大器,而不是萬靈丹。把力量放大並不會自動讓力量用在對的地方——草率的自動化能製造的問題不亞於它能解決的。
比「軟體自動化」更好的選項是更高層次的系統設計:根本不需要自動化的自主系統(autonomous system)。
本章透過實際案例研究自動化的價值與限制,並呈現 Google 從手動腳本一路演進到自主系統的歷程。
自動化的價值#
- 一致性(consistency):人類做重複工作必然有出入;自動化把「執行良好定義流程」的價值轉為一致性
- 平台性(platform):bug 修一次就終結;可被擴展、可導出指標、能在不便人類執行的時段運作
- 更快修復(faster repairs):常見故障的 MTTR 因自動化下降,越早自動化越省成本
- 更快動作(faster action):failover、流量切換等決策遠超人類反應時間
- 節省時間(time saving):包進自動化後,任何人都能執行——將執行者與執行解耦是最強的槓桿
「如果我們設計的流程無法自動化,就只能繼續用人類維持系統。讓人類為機器工作,等於用血汗淚水餵食機器。」 — Joseph Bironas,曾領 Google 資料中心 turnup
自動化的層級#
1. 無自動化(手動 failover)
2. 外部維護的系統專屬自動化(SRE 家目錄裡的腳本)
3. 外部維護的通用自動化(DB 模組加進通用 failover 腳本)
4. 系統內建的專屬自動化(DB 自帶 failover 腳本)
5. 不需自動化的自主系統(DB 自己偵測並切換)SRE 痛恨手動操作,目標是把所有系統推向第 5 階——但有時手動不可避免。
案例一:MySQL on Borg——把自己自動化掉#
廣告 SRE 從 2005–2008 把 Ads 用的 MySQL 維護得「成熟可控」,但日常還是有大量瑣事。2008 年起把 MySQL 搬上 Borg(叢集排程系統),預期:
- 機器與副本維護完全消失(Borg 自動 setup / restart)
- 多個 MySQL 實例 binpack 到同一台機器,提升使用率
但 Borg 的 task 一週移動一兩次——副本可以,master 不行:
- 當時 master failover 一次 30–90 分鐘
- 手動 failover 最多能保證 99% 可用度,達不到業務目標
- 為符合錯誤預算,每次 failover 必須少於 30 秒——人類沒辦法
解法:2009 年完成 failover daemon「Decider」,95% 的 failover 可在 30 秒內完成(含計畫性與意外)。
從「避免 failover」轉向「擁抱 failover 是必然,並用自動化快速恢復」。
成本:所有應用都得加上更多容錯邏輯(JDBC 等需客製化)。回報:
- 運維時間下降 95%
- 自動化擴及 schema change,總維護成本再降 95%
- 多實例共機 → 釋出 60% 硬體
案例二:叢集 Turnup——自動化的曲折之路#
十年前的 Cluster Infrastructure SRE 把 turnup 當作新人培訓任務——因為頻率剛好相當。叢集啟用流程包含 6 大步,其中設定服務(步驟 4、6)涉及上百個子系統與大量旗標。
早期:用 SSH 串接腳本#
早期靠 SSH 腳本快速派發,初期成功但快速累積成「技術債的膽固醇」。
真實災難:一個 Bigtable 叢集為了延遲不用第一顆碟;一年後某自動化以「第一顆碟未用 = 無儲存」為前提,整個叢集的資料瞬間被抹除——靠多副本才保住。
教訓:自動化不能依賴隱含的「安全訊號」。
Prodtest:以單元測試找錯誤配置#
擴展 Python unit test 框架,讓它能對真實服務做測試:
- 測試有相依鏈,前面失敗就中止後續
- 出現新誤配置 → 寫一個 Prodtest 把它擋下
- 服務跨叢集的設定錯誤可被視覺化呈現
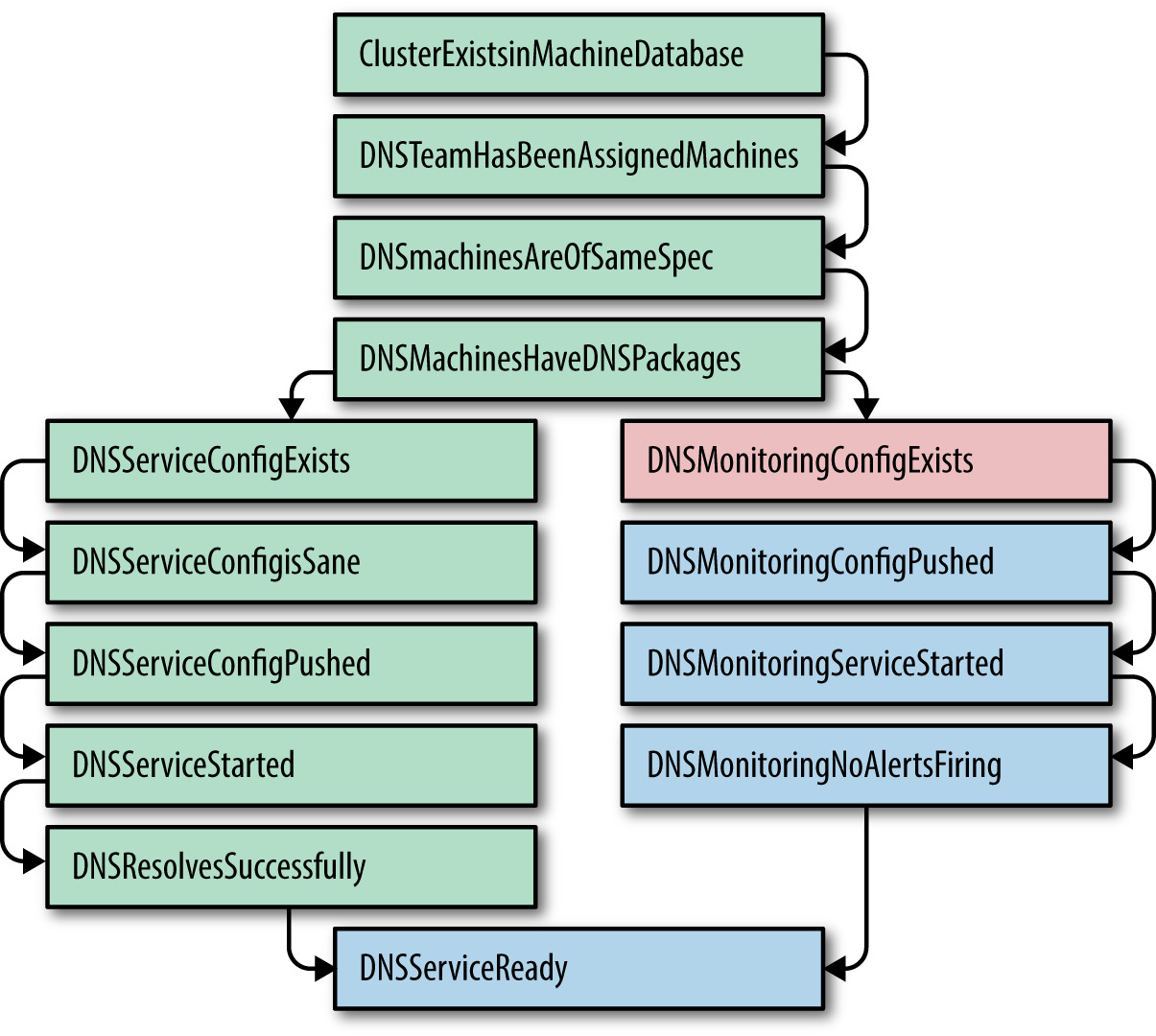
Figure 7.1: DNS 服務的 ProdTest:一個失敗測試會中止後續測試鏈
冪等修復:把測試與修復配對#
senior 管理層要求「3 個月後 5 個新叢集同日 network-ready,1 週內啟用」。為此把 Prodtest 升級為「測試 + 修復」配對:
- 每 15 分鐘跑一次「fix」腳本,所有 fix 寫成冪等
- 失敗超過某次數就停下、通知人類
此設計有缺陷:測試 → 修復 → 再測試的延遲產生「時靈時不靈」的測試;非自然冪等的 fix 會把系統帶入不一致狀態。
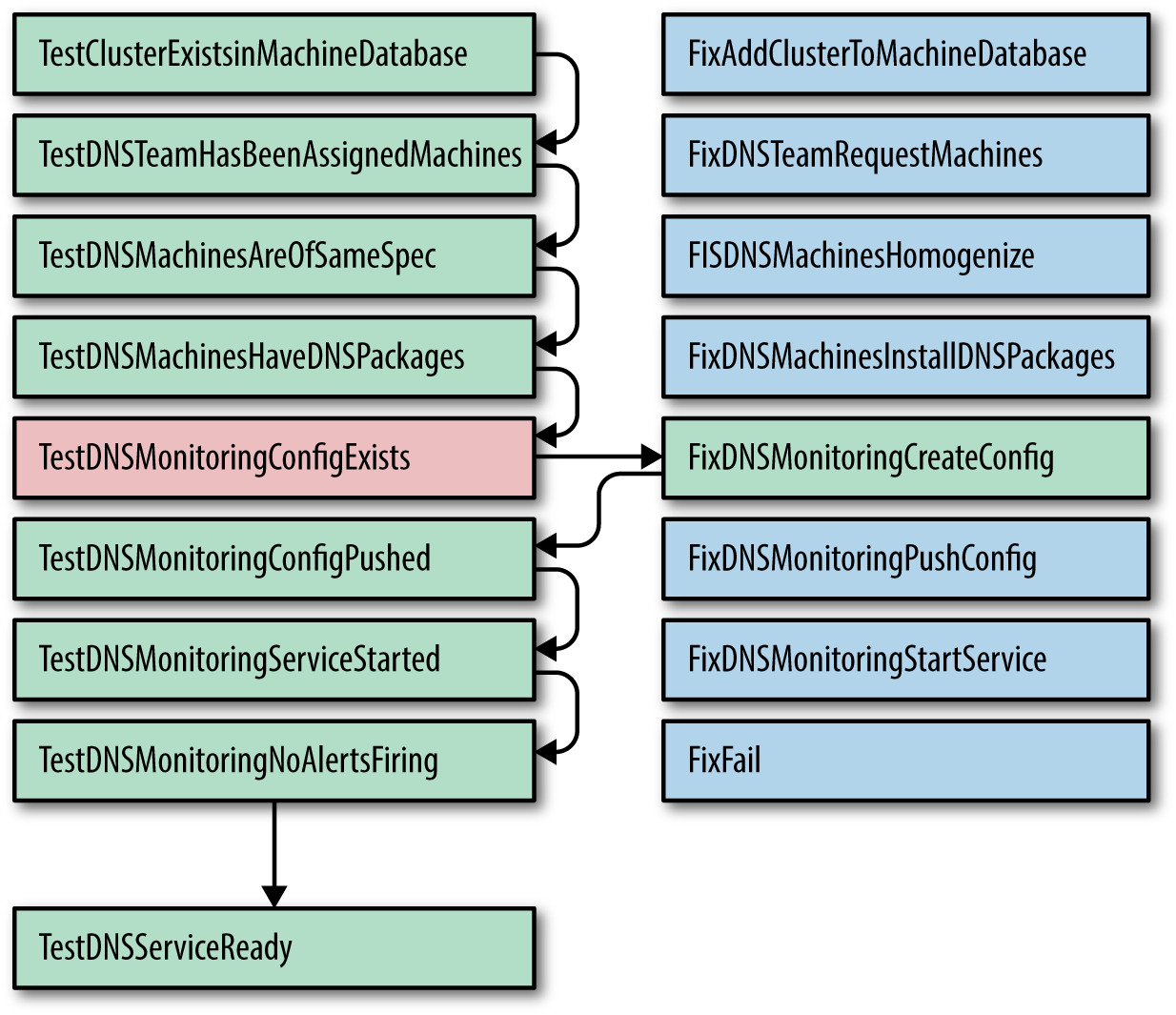
Figure 7.2: DNS 服務的 ProdTest:一個失敗測試只觸發一個修復
專業化的代價#
自動化的三個面向:
- 能力(competence):準確度
- 延遲(latency):執行完成速度
- 相關性(relevance):覆蓋真實流程的比例
成立專責的「turnup team」確實降低了延遲,但讓服務團隊脫離自動化後:
- 受 bug 影響的不再是領域專家 → 自動化漸失相關性
- 「最快啟用」與「最易維護」的目標不一致 → 沒人去清技術債
- 不寫自動化的人沒誘因把系統設計得好自動化
- PM 排程不受低品質自動化拖累時,永遠優先做新功能
最好用的工具通常由「使用者本人」寫出來。產品開發團隊保留部分對生產系統的自覺,是健康的。
服務導向叢集啟用(SOA)#
安全強制(不能再用 sshd)促成下一步:以 RPC 為基礎、有 ACL 的 Local Admin Daemon 取代 SSH。
最終演化為服務導向:
- 各服務團隊負責提供處理 turnup / turndown RPC 的 Admin Server
- 由「知道叢集何時就緒」的系統發出 RPC
- 自動化變得低延遲、能力強、且持續隨變化保持相關性
案例三:Borg——倉儲規模電腦的誕生#
Google 叢集從早期的「特定用途機架 + 異質配置 + master 機器存 golden binary」開始演進:
- 第一步:parallel SSH 與描述檔
- 第二步:Python 腳本管 service / process / log
- 第三步:機器狀態進入資料庫,自動化能管整個機器生命週期
- 侷限:所有抽象仍綁在「實體機器」上
Borg 的關鍵突破是把叢集當作受管的資源海:
- 以 API 對中央協調者下指令
- 不再有「機器擁有權」,batch 與 user-facing task 可共機
- 跨機器搬遷 task 變成「系統內建特性」(類似行程在不同 CPU 間移動)
- OS 升級、損壞修復、生命週期管理對 SRE 變成幾乎 no-op
重點不只是「自動化」,而是把問題視為軟體問題。初期自動化爭取的時間,是為了把叢集管理重新設計為自主(autonomous)而非僅僅 automated。
自動化的危險與「可靠性是基本特性」#
自動化覆蓋的活動愈多,人類愈缺乏直接接觸——一旦自動化失效,人類已無能力接手。這個現象在航空、工業領域都有對應討論。
「Diskerase」事件:
- 自動化退役流程在 Diskerase 完成後失敗
- 重新從頭跑,發現「待 Diskerase 集合」為空——但**空集合被當成「全部」**的特殊值
- 自動化幾分鐘內抹除了所有 colos 中 CDN 機器的硬碟
- 因容量規劃做得好,使用者僅感受到輕微延遲增加;但用了兩天重灌,數週後加上速率限制與冪等保證
建議#
不必等到 Google 規模才開始自動化——但自動化最高槓桿出現在「設計階段」:
- 解耦子系統
- 引入清晰 API
- 最小化副作用
- 朝「自主」設計而非「事後加自動化」
大型系統很難在事後改造為自主,但軟體工程的基本好習慣會幫上大忙。