Google 的資料中心與傳統機房有顯著差異。本章勾勒 Google 的硬體、系統軟體、開發環境與一個範例服務的生命週期,為後續章節大量出現的內部術語打基礎。
硬體拓撲#
Google 的運算資源大多座落在自家設計的資料中心,含自製的電力、冷卻、網路與伺服器硬體。同一機房的硬體基本同構。為避免「server」一詞的混淆,本書統一以下術語:
- 機器(machine):一台硬體(或 VM)
- 伺服器(server):實作服務的一段軟體
機器不專屬於某一伺服器,資源由叢集作業系統 Borg 統一調度。資料中心的層次:
- 數十台機器 → 一個機架(rack)
- 多個機架 → 一列(row)
- 一列或多列 → 一個叢集(cluster)
- 一棟資料中心建築通常有多個叢集
- 鄰近的多棟建築構成一個園區(campus)
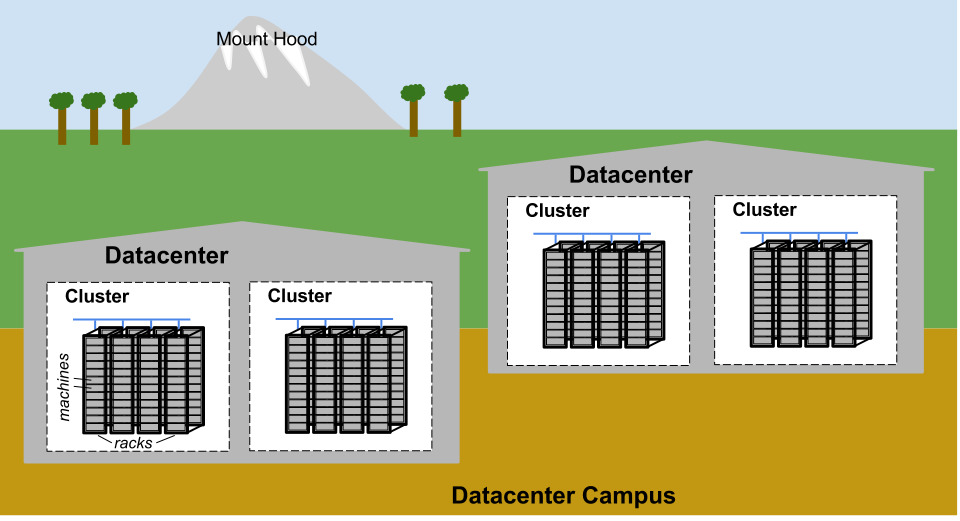
Figure 2.1: Google 資料中心園區拓撲示意
機器間以名為 Jupiter 的 Clos 網路 fabric 連接,最高可達 1.3 Pbps 的 bisection 頻寬。資料中心之間則由 B4——一個 OpenFlow 軟體定義網路(software-defined networking, SDN)骨幹——以彈性頻寬分配連結。
管理機器:Borg 與軟體層#
由於每個叢集每年都會有「數千台機器」與「數千顆硬碟」失效,硬體故障必須以軟體抽象掉,讓使用者與服務團隊無感。
Borg#
Borg 是 Google 的分散式叢集作業系統(Kubernetes 的前身,類似 Apache Mesos),在叢集層級管理 jobs:
- 一個 job 可以是長駐伺服器,也可以是 MapReduce 之類的批次工作
- 一個 job 由多個(甚至上千個)相同的 task 組成
- Borg 為 task 分配機器、監看健康度,故障時自動重啟(必要時換機器)
- 使用 Borg Naming Service(BNS) 路徑(例:
/bns/<cluster>/<user>/<job>/<task>)取代 IP:port - 依各 job 宣告的資源需求做 binpacking,並考量失效域(不會把同一 job 全部塞到同一機架)
- 用量超過宣告值的 task 會被殺掉重啟
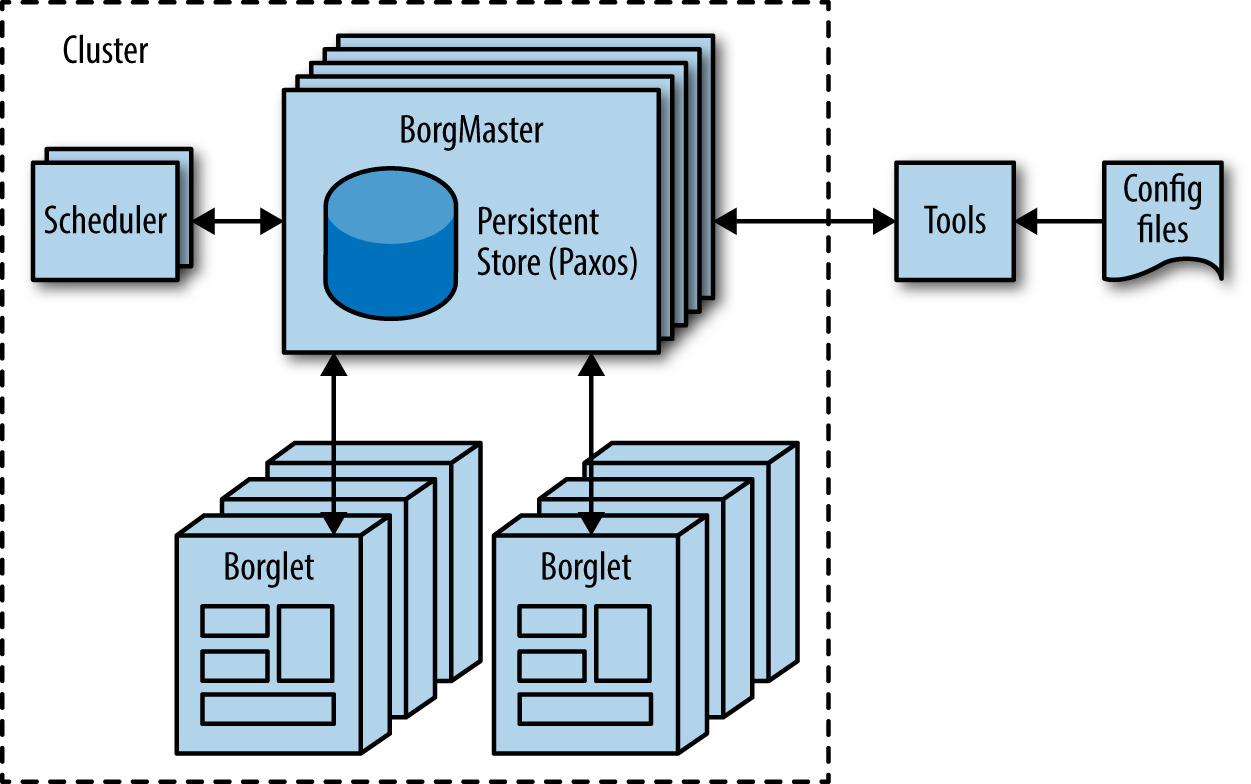
Figure 2.2: Borg 叢集架構高階示意
儲存#
儲存堆疊由下而上:
- D(disk):跑在幾乎所有機器上的檔案伺服器,含 HDD 與 flash
- Colossus:叢集級檔案系統,提供副本與加密;GFS(Google File System)的後繼者
- 建在 Colossus 之上的資料庫服務:
- Bigtable:PB 等級的 NoSQL,稀疏多維排序映射;支援跨資料中心的最終一致複製
- Spanner:全球強一致的 SQL-like 介面
- Blobstore 等其他選項
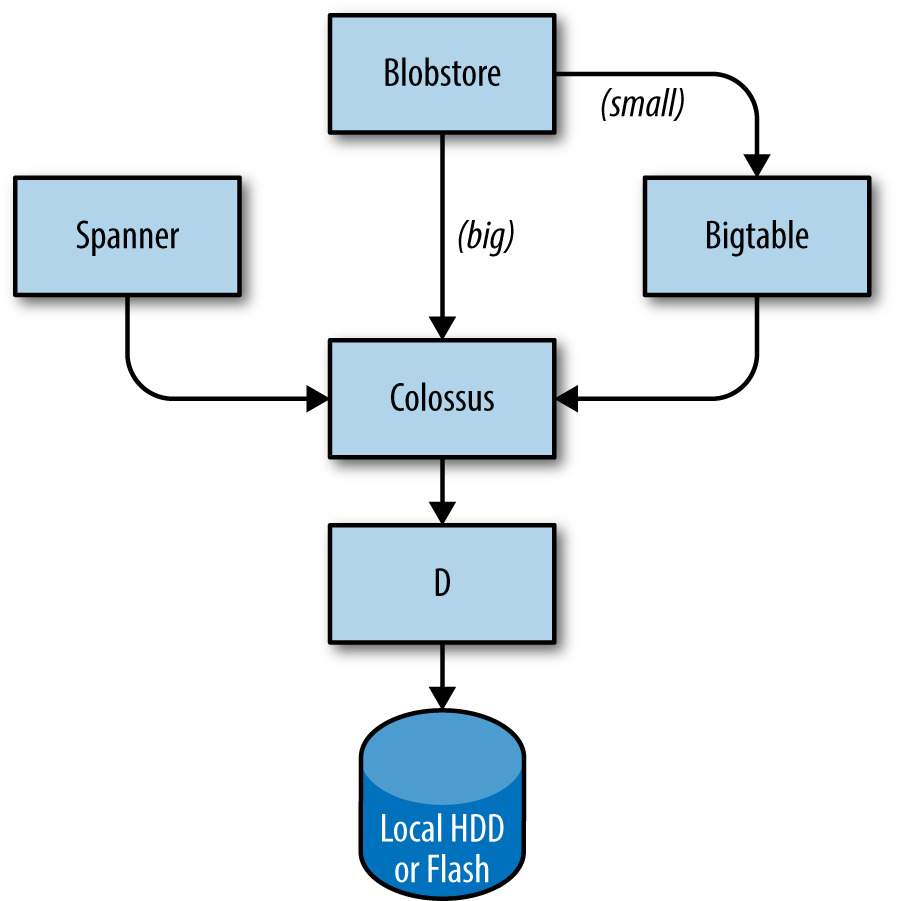
Figure 2.3: Google 儲存堆疊的層次
網路#
- 使用 OpenFlow SDN:把昂貴的路由決策從硬體中抽出來,交給集中(且備援)的控制器預先計算最佳路徑
- Bandwidth Enforcer(BwE) 限制與最佳化各 task 可用頻寬
- Global Software Load Balancer(GSLB) 進行三層負載平衡:
- DNS(地理層級)
- 使用者服務層級(如 YouTube、Maps)
- RPC 層級
其他系統軟體#
- Chubby:分散式鎖服務,提供類似檔案系統的 API,內部以 Paxos 達成共識;BNS 的映射資料即存於此,且常用於 master election
- Borgmon:監控系統,定期 scrape 受監控伺服器的指標,可即時告警,也可存歷史趨勢做容量規劃
軟體基礎建設#
- 程式碼大量多執行緒,單一 task 可吃下多核
- 每個伺服器內建 HTTP 端點,提供診斷與統計
- 所有服務以 Stubby RPC 溝通(開源版為 gRPC)
- 即使「呼叫同程序內副程序」也常以 RPC 包裝,便於日後拆分模組
- 資料以 protocol buffers(protobuf) 序列化,相較 XML:
- 體積小 3–10 倍
- 速度快 20–100 倍
- 語意更明確
開發環境#
Google 採單一共享原始碼倉庫(monorepo),少數例外(Android、Chrome)有自家開源倉庫。實務影響:
- 跨專案修問題:在他人專案發現 bug,可送 changelist(CL)給該專案負責人 review 後 submit 到主線
- 所有變更都需 review 才可進入主線
- Build 與測試由資料中心叢集執行;每次 CL 都會跑所有可能受影響的測試
- 部分專案採用 push-on-green:測試通過後自動推上線
範例服務:Shakespeare#
想像一個服務,可查單字在莎士比亞作品中的所有出現位置。
系統拆分#
- 批次部分:MapReduce 讀取文本、建索引、寫入 Bigtable,僅須執行一次(或極少數)
- Map:拆字
- Shuffle:按字排序
- Reduce:產生
(字, 位置清單)元組,以字為 key 寫入 Bigtable
- 應用前端:長駐處理使用者請求
一次請求的生命週期#
- 使用者瀏覽器解析
shakespeare.google.com→ DNS 最終轉到 Google DNS → GSLB 依負載挑選前端 IP - 瀏覽器連到 Google Frontend(GFE)——一個終結 TCP 的反向代理
- GFE 透過 GSLB 找到一台可用的 Shakespeare 前端,並以 RPC 送上 HTML 請求
- Shakespeare 前端建立 protobuf 查字請求,透過 GSLB 取得後端 BNS 位址,呼叫後端
- 後端向 Bigtable 取資料 → 回 protobuf 給前端 → 前端組 HTML 回給使用者
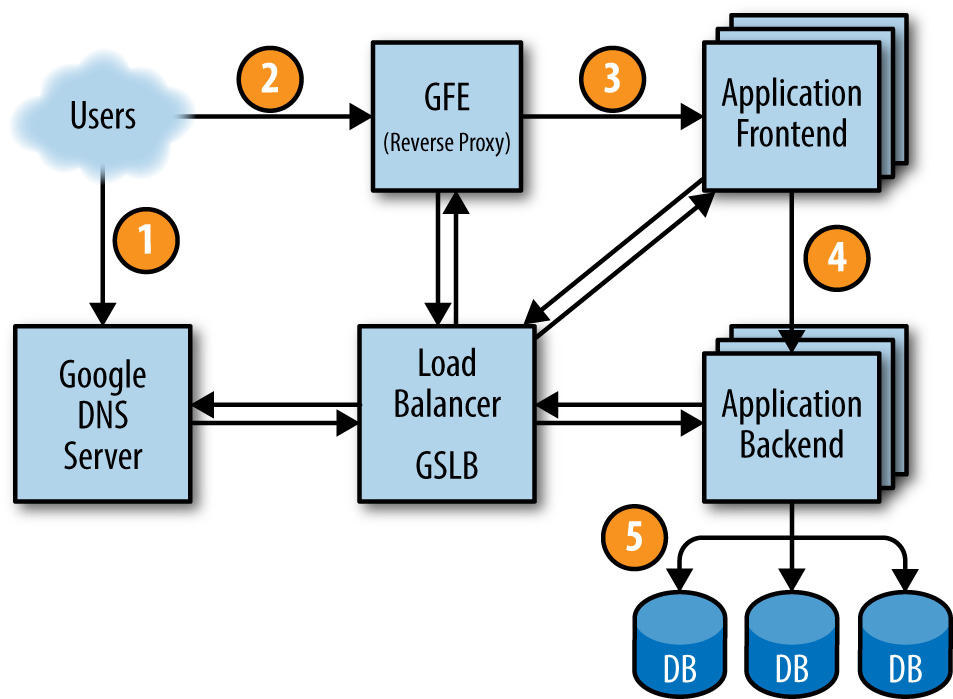
Figure 2.4: 一次請求的生命週期
整條鏈在數百毫秒內完成。若 GSLB 失效會造成大規模災難——靠嚴謹測試、漸進式發佈與 graceful degradation 維持可靠性。
Job 與資料的分佈#
容量規劃要算「N + 2」:保留升級時 1 個 task 不可用,再加 1 個用於機器故障緩衝。
以負載測試結果(後端 100 QPS)對應到全球尖峰需求 3,470 QPS 為例:
| 區域 | 尖峰 QPS | 需要 task 數 |
|---|---|---|
| 北美 | 1,430 | 17(N+2) |
| 歐洲與非洲 | 1,400 | 16(N+2) |
| 亞太 | 350 | 6(N+2) |
| 南美 | 290 | 4(N+1,省 20% 硬體) |
Bigtable 也在各區域複製:
- 提升災難復原能力
- 降低跨洲查詢延遲
- 內容更新頻率低,最終一致性不是問題
本章引入的術語(Borg、BNS、GFE、GSLB、Bigtable、Colossus、Stubby、protobuf)會在後續章節反覆出現,不必一次記下,但建議遇到時回頭查閱。