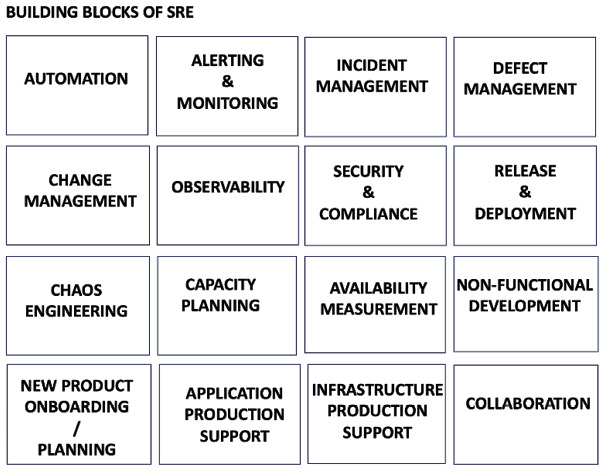
為什麼需要速查表#
這份速查表是 SRE 工作的高階摘要,協助新手快速理解、也能讓既有團隊重新檢視自己的職責分布是否完整。
自動化(Automation)#
自動化是 SRE 與 DevOps 的核心。雖然辨識並自動化任務需要時間,但長期能釋放團隊精力處理優先要事。
關鍵實踐:
- 把 production 維運中的手動任務自動化
- 為其他跨職能團隊建立自助式工具,方便他們從 production 取得資料
- 自動化告警與事件解決
- 任意語言皆可(Shell、Python、Java 最常見);有時 scripting 即可,有時需要新工具
服務管理(Service Management)#
- 嚴格的工單追蹤標準
- 事件管理:處理、解決、追蹤事件
- 缺陷管理:建立與追蹤 production 缺陷、驗證修補
- RCA / 事後檢討:把 RCA 嵌入事件管理流程,避免問題再發
告警與監控#
- 為應用建立量測健康度與效能的指標
- 與開發共同決定告警嚴重度
- 設置告警與通知通道
- 建立健康儀表板,並隨新功能持續強化
- 告警與事件管理工具整合,確保通知到對的人
可觀測性#
- 用 ML 關聯多重訊號與告警
- 建立可自我修復的告警
安全與合規#
- 把存取政策、IAM、憑證與密碼自動更新納入日常
- 應用與基礎設施的稽核控制與合規報表
變更管理#
- 追蹤上線變更
- 必要時參與審核與實作
發布與部署#
- 審查程式碼變更與修補
- 建立非功能需求所需工具與能力
- 在必要時回退變更
- 與開發、測試協調 release 與 hotfix 週期
混沌工程#
- 列出混沌測試案例
- 模擬 production 真實情境
- 與開發、基礎設施合作修補測試發現的缺陷
容量規劃#
- 與開發共同規劃應用所需基礎設施容量
- 分析 production 應用的 CPU、記憶體、實例與跨區域需求
- 持續監控基礎設施使用率
可用性#
- 定義 SLI、SLO、SLA
- 建立量測系統表現的指標
- 透過指標衡量整體可用性
非功能性開發#
- 建立工具與能力,幫助開發專注於業務邏輯
- 修補非功能性 bug:誤報告警、多餘日誌等
- 對 production 新功能執行健全性檢查
新產品上線與規劃#
- 從 SDLC 第一階段就讓 SRE 介入
- 參與架構討論與系統設計
- 在發布前審查並簽核新服務手冊
應用 production 支援#
- 用工具排查問題
- 對影響 production 的問題進行繞過
- 進行根因分析、跨團隊合作
- 建構告警與監控儀表板
- 訂定事件與缺陷管理規範
- 維持 production 對開發、測試的回饋迴路
- 與發布、變更管理、開發協同處理事件
基礎設施 production 支援#
- 監控基礎設施健康狀態
- 排查與修復 production 應用上的基礎設施問題
- 升級基礎設施版本
規劃#
- 為各類別建立最佳實踐
- 用標準與流程把最佳實踐內化為文化
- 建立透明、無責的文化
- 工具與技術選擇上的最佳實踐
協作(Collaboration)#
協作是 SRE 方法論的底色。打破穀倉、跨團隊溝通是把工具與流程串連起來的黏著劑。
- 與開發每日協作(新功能、bug 修補、調查、事後檢討)
- 與測試團隊一同檢視低層環境的缺陷風險
- 與 DevOps 共同配置 CI/CD 與基礎設施
- 與產品管理協作建立 SDLC 最佳實踐
- 與業務團隊溝通新需求
把這份清單當作健康檢查表:每季逐項問「我們在這個面向做得如何?」可以最快發現團隊的盲點。