SRE 是業務策略的一部分#
商業的目標與 SRE 的目標其實是一致的:建構並交付可靠、可用的系統。SRE 的方法論讓系統表現可量測、可回饋,幫助業務做更好的決策。
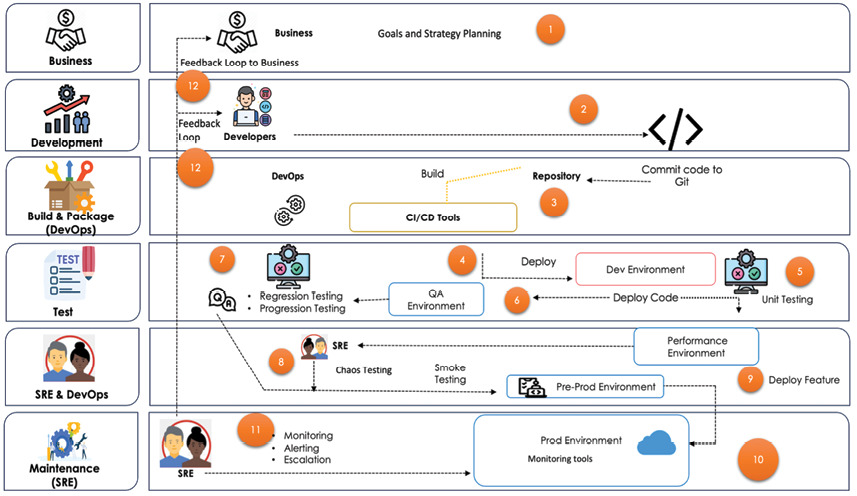
業務定義組織目標 → 技術團隊(含開發與 SRE)執行 → SRE 把 production 反饋回到工程與業務 → 業務據此調整策略。SRE 是這個閉環中最後一節,也是改善的起點。
SRE 如何擴大業務影響力#
- 量測(Measurement):上線後 SRE 為各服務建立指標。SLA、SLO、SLI、錯誤預算(error budget)讓組織把工程努力對齊業務目標
- 事件管理(Incident management):建立錯誤預算,回饋給業務以平衡新功能與既有可靠性投資
- 運維作為價值創造:SRE 不只是支援系統的後勤,更是成長的推動者;他們建構自動化讓開發專注高品質程式碼
SRE 等於組織內的「現實檢視官」:用真實 production 資料告訴業務,現在系統的真實狀態。
案例一:電商平台的可靠性救援#
某電商平台上線兩年。半年後 SRE 提交分析:
- 既定指標顯示 99.999% 可用率,看似一切順利
- 事件管理流程有效,客服工單都依時程處理
- 但 SRE 從請求/回應時間與錯誤率指標中察覺:付款與搜尋服務在某時段間歇性失敗
- 與基礎設施 SME 比對網路延遲,無異常
- 與開發合作後發現高負載下記憶體飆高
- 重新檢視負載測試,發現原本估測的流量低估了真實使用量
- 修補後(多執行緒與快取邏輯改寫)效能改善
- SRE 把這個經驗回饋業務:估算量增加,連帶提升基礎設施預算
- 開發以此經驗主動審視類似邏輯的其他服務
沒有 SRE 的回饋,業務也許仍能察覺問題,但會等到使用者投訴才反應。SRE 把這層延遲縮短到「使用者察覺前」。
業務端的最佳實踐#
- 明確定義組織目標
- 詳細路線圖配上可達成的小型里程碑與時程
- 投入新專案前做市場研究,鎖定目標客群
- 為運維保留容量緩衝
- 把風險管理納入策略——沒有 100% 可用的系統
- 與工程團隊定期 review 目標與里程碑
- 業務與工程指標互相對齊(如 MTTR 與 MTBF 應由各 SDLC 團隊共同採用)
- 同時優先化功能與非功能需求
- 建立持續改進的回饋迴路
案例二:醫療軟體的回饋迴路#
健康照護軟體已上線醫院端,後續一年內擴充線上預約與藥品配送,第二年加入線上問診與急診預約。多功能上線半年後出現效能下滑。
SRE 觀察到 5% 效能退化、僅 0.5% 客訴。雖然可用性沒掉,仍是預警紅燈。
流程#
- SRE 1 天內完成資料分析、2 天內回報業務與開發
- 高層原本有定期會議,但這份警示讓業務立即召集 SRE 與開發專題會議
- 第一輪結論:線上預約功能流量爆增,記憶體擴充作為快修
- 兩個月後 SRE 又看到 5% 額外退化——客戶請求增加 30%、應用載入時間 +10%
- 應用兩次崩潰,自我修復把影響降到最低
- 業務據此暫停兩個進行中的新功能,把工程資源轉到修補既有問題
- 兩週內完成修補,SRE 監控確認效能恢復
沒有跨團隊的回饋迴路與正確指標,這個衰退就會在客戶大規模投訴後才被發現。SRE 把工程資料轉成業務語言,是這個閉環能高效運作的關鍵。