案例情境:從零打造的電商平台#
從零開始建立電商網站,目標是用 SRE 從專案初期就把告警疲勞(alert fatigue)擋在門外。告警疲勞指的是充斥不必要、含資訊錯誤的告警,導致系統真正出問題時被淹沒。
後續以年度為時間軸,並依季度劃分階段,幫助讀者直覺理解時程。
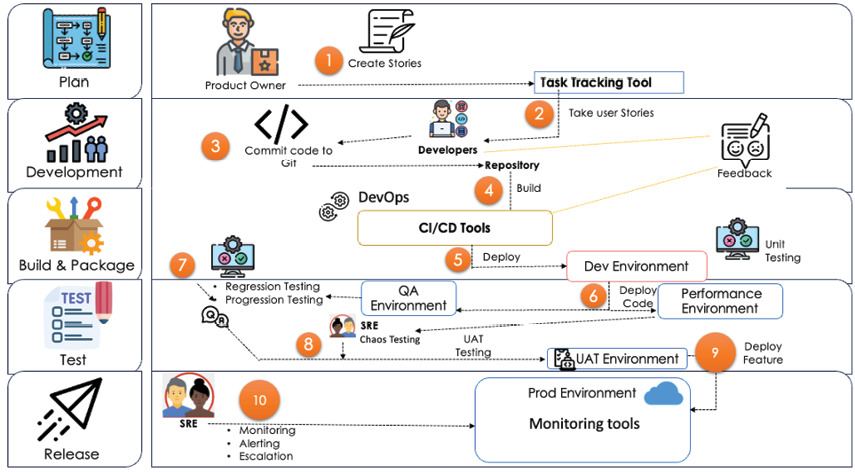
SDLC 各階段的細部流程#
規劃階段一(Q1)#
- 商業與技術領導討論可行性
- 完成高階商業需求文件並核定預算
規劃階段二(Q2):高階設計#
- 工程、基礎設施、產品、SRE 的 SME 共同制訂資料流與架構
- 同步決定整套技術棧
- 各團隊組建(開發、QA、DevOps、SRE),人員到位
案例使用的工具棧#
- 基礎設施:AWS Web/應用伺服器、AWS LoadBalancer、AWS IAM、AWS NoSQL/RDBMS、AWS in-memory 儲存、事件串流、CDN
- 開發工具:GitHub、開發 IDE、Jira、Mural(資料流)
- DevOps 工具:Jenkins、Terraform、Ansible
- SRE 工具:AWS 監控、Grafana、Prometheus、ELK、ITSM
- 產品工具:產品管理工具
規劃階段三(Q2):低階設計#
- 產品團隊把架構切成可追蹤的功能(feature),用 Jira 等工具管理
- DevOps 撰寫低階基礎設施設計:伺服器、資料庫、相關工具
配置階段(Q3)#
- DevOps 建好開發、測試環境
- 建置 CI/CD 管線、配置 GitHub、Jira、ELK 等工具
實作階段(Q3 起)#
- 多支開發團隊並行寫程式
- 採敏捷流程,與 DevOps 管線串接,建構與部署同步進行
- DevOps 同步完成 production 環境
測試階段(Q4 至次年 Q1)#
- 程式打包後部署到測試環境
- QA 進行回歸與遞增測試
- 同步進行效能測試評估擴充性
- 缺陷修補與再測在 sprint 中迭代
- SRE 對通過測試的版本做混沌測試
- 開發團隊向 SRE 走查(walkthrough)功能與資料流,並交付 runbook
- SRE 依 runbook 上的錯誤碼設置告警與儀表板模板
- SRE 同步完成 production 支援所需工具
部署階段(次年 Q1)#
- 通過測試與混沌測試的程式由 DevOps 透過 CI/CD 部署到 production
- SRE 先做基本健全性檢查(sanity)
- 通過後才正式對外開放
健全性測試(次年 Q2)#
這是阻斷告警疲勞的關鍵階段。SRE 會:
- 收集測試階段的告警資料
- 對照 runbook 中的告警設計
- 借助工具或自建 ML 演算法分析資料
- 配置儀表板與告警,再到 production 驗證
- 確認告警通道、自我修復都正確
如果發現問題,依問題類型回到對應團隊修補、再走一次熱修補流程。最終 SRE 簽核才能上線。
維運階段(次年 Q3)#
- SRE 與運維持續監控
- 運維處理日常工單與低階問題(依 runbook)
- SRE 處理技術問題、減少 toil、改善告警
範例:客戶資料看不到#
服務間歇性 OOM。運維依 runbook 重啟服務無效;SRE 介入加記憶體,仍未解;最後與開發合作改邏輯重新部署。整段流程進入「開發 → 測試 → 部署」迷你 SDLC。
結語#
告警疲勞並非單一事件造成,而是設計疏失與後續疏於整理的長期累積。把「告警設計、走查、配置驗證、健全性測試、持續調整」串成系統化流程,才能讓告警保持高訊噪比。