案例一:單一資料來源(Single Data Input)#
某軟體公司接下房地產專案:管理看房、出租、買賣與虛擬導覽。組織原有 legacy 軟體,要將其遷上雲端。
流程概述#
- 技術團隊組成、規劃階段啟動。部分舊服務搬上雲端,部分從零打造,技術棧拍板
- 設計架構、敏捷與 PI 流程、發布與變更管理流程都按最佳實踐推進
- 第一版上線順利。每兩週做一次 sprint 發布
- 第二週新功能上線後出現搜尋失敗
- 調查發現:搬遷過程把 legacy 的「資料儲存服務」直接搬過來,更新仍靠工程師人工輸入
- 該資料儲存服務成為瓶頸,SRE 無法在問題發生前察覺,只能等資料被引用時才看到後果,可靠性下滑
這是「單一資料輸入」反模式。表面上系統運作正常,但只要這個服務出問題,整個依賴鏈就垮。SRE 連監控都來不及。
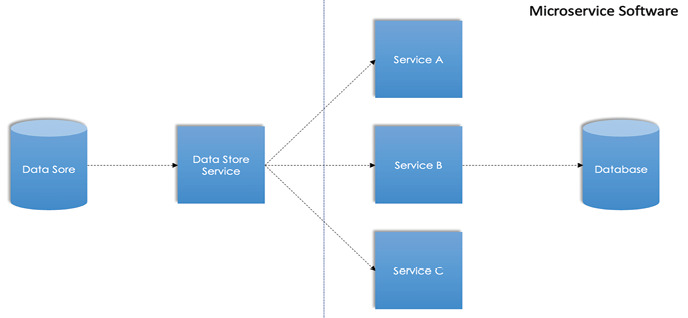
Figure 5.3: Data store as an input source for services
解法#
- 短期:自動化人工輸入的部分,由業務需求發布觸發更新;移除人為錯誤、建立資料更新的可驗證來源
- 長期:把資料儲存服務拆成兩支:一支提供關鍵資料,另一支提供非關鍵資料。當非關鍵資料失敗時,其他依賴關鍵資料的服務仍可繼續運作
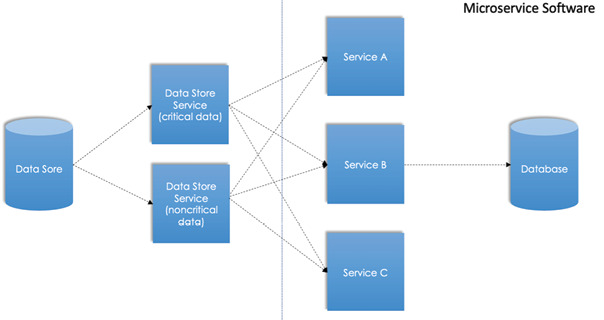
Figure 5.4: Breakdown of data store service into two services
「單一點失效」幾乎是所有可靠性問題的源頭。即使是 legacy 搬遷,也不能忽略拆分機會。
案例二:缺乏事件管理流程#
某銀行用了 10 年的軟體,準備升級到新平台。
流程概述#
- 技術團隊組成、新工具導入;兩年內完成三版發布
- 前兩版順利推出,最終版本是「大爆炸式」釋出,包含多項新功能與舊版修補
- 上線後客服與內部團隊湧入大量工單;多數是新功能查詢或既有資料疑問,但也有少數重大問題
- 數月後 SRE 與運維被工單淹沒:開始錯過 SLA、客戶受影響、可靠性下滑
- 根因:沒有為新軟體調整事件管理流程
- 新軟體 = 新需求;舊事件管理流程不再適用
- 工程師憑直覺挑工單、有時兩人撞題
- 高優先級事件被漏掉
老流程未必適用新系統。組織重大轉換時,事件管理流程應同步重新設計。
解法#
- 採納舊流程的可重用部分作為基礎
- 重新定義優先級:例如「無法轉帳」優先於「無法新開存款」、「無法新開存款」優先於「無法更新地址」
- 自動化工單接收與解決流程:避免工程師憑感覺挑單
良好的事件管理需具備:清楚分類規則、固定的工作分派、自動化分派與通知、SLA 自動追蹤。
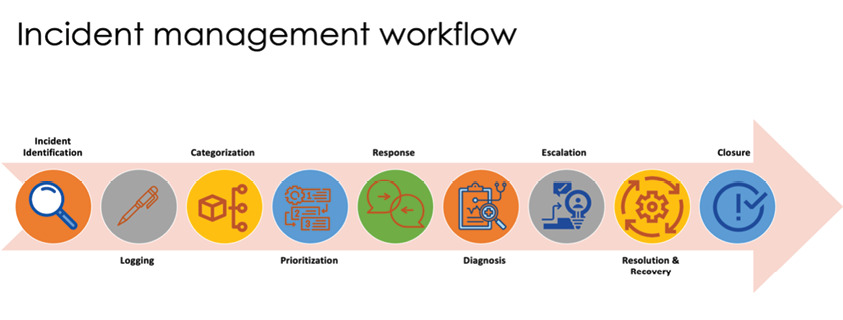
Figure 5.5: Incident management workflow best practice
案例三:變更失控(No Control Over Changes)#
延續上例的銀行軟體:事件管理已導入,但基礎設施龐大(雲端、NoSQL、cache、event stream、CI/CD、監控、日誌、告警、原始碼工具),每天的變更越積越多。
流程惡化#
- 各團隊把變更帶到變更諮詢委員會(Change Advisory Board, CAB)會議審查;初期運作順利
- 隨著服務數量爆增,CAB 會議延長到 1 小時以上
- 沒有窗口處理 ad-hoc 與緊急修補;ad-hoc 變更未被追蹤反成新風險
- 變更失控,SRE 把大量時間花在審查而非穩定 production
- 一次基礎設施變更需要 SME 審核,但資深 SRE 忙別事,由資淺 SRE 批准;當天該變更與其他變更衝突,造成重大事故
變更管理是 DevOps 與 SRE 的關鍵流程。一旦失控,SRE 就會被審查工作淹沒,反而不能專注於 production 穩定。
解法#
- 自動化整個流程:要求每筆變更至少在兩天前提出,內含實作步驟、驗證步驟、影響評估
- 預批機制:SRE 與 CAB 從工具佇列中拉出待審變更逐筆批准,CAB 會議只處理需現場討論的關鍵變更
- 衝突檢查:自動化工具同時比對日內所有變更,自動拒絕或暫停可能衝突的提案
- 報表與追蹤:CAB 從工具拉報表討論被擱置的變更,避免重複討論已批准的常規變更
CAB 會議價值不在「全部都看一遍」,而在「集中處理真正需要跨團隊協同的關鍵變更」。把例行工作交給工具,是讓 CAB 真正發揮效用的關鍵。

Figure 5.6: Change Advisory Board process
重點整理#
- 反模式起初看似誘人,長期會反噬
- 在 SDLC 各階段都要採用最佳實踐
- 善用工具自動化常見流程,避開手動誤差
- 回饋迴路與根因分析是建立文化的兩大支柱
- 在每個里程碑量測系統表現,是追蹤效能的最佳方法
- 沒有萬靈藥;先穩定小問題,再堆疊新功能