為何事件管理是穩定的關鍵#
事件管理(incident management)是開發與 SRE 團隊回應未預期事件、恢復服務的流程。它與可觀測性緊密耦合,是系統穩定性的核心因素。
任何讓使用者中斷使用的事件就是 incident。SRE 是技術問題的第一線,能否有系統地追蹤並處理客戶問題,直接決定客戶滿意度。
沒有事件管理流程的後果#
假設組織沒有 incident management:
- 客服收到客訴,透過電子郵件或訊息通知 SRE
- 沒有共同追蹤平台,客服不知道 SRE 處理進度
- 通訊不透明、流程冗長,問題量增加時可能漏單
引入工具與流程後:
- 客服把客訴登錄到工具裡作為事件,無法解決時指派給 SRE
- SRE 收到通知,調查過程更新到事件上
- 客服可即時看到狀態並回覆使用者
事件管理的階段#
- 事件登錄(Incident logging):在 SDLC 初期就決定工具,並定義「何時、如何、用什麼模板」登錄
- 事件建立(Incident creation):將收集到的細節送進工具產生事件
- 事件分類(Incident categorization):常見分為高、中、低,依事件類型、來源、衝擊判定
- 事件優先排序(Incident prioritization):依商業衝擊、衝擊百分比、分類劃分 P1 ~ P4,每級對應不同 SLA
- 事件接收(Incident accepting):在 SLA 內主動承接,避免重工
- 事件解決(Incident resolution):依優先級時程修復,例如 P1 4 小時內、P2 8 小時內
- 事件關閉(Incident closure):補齊根因紀錄並通知申報者
- 根因分析(Incident root cause):又稱問題管理(problem management),目標是修補底層原因,與事件管理「先繞過、後修復」的分工互補
事件管理「繞過當下問題」、問題管理「根除原因」。在某些組織兩者是同一流程的不同階段,在某些組織則由不同團隊負責。
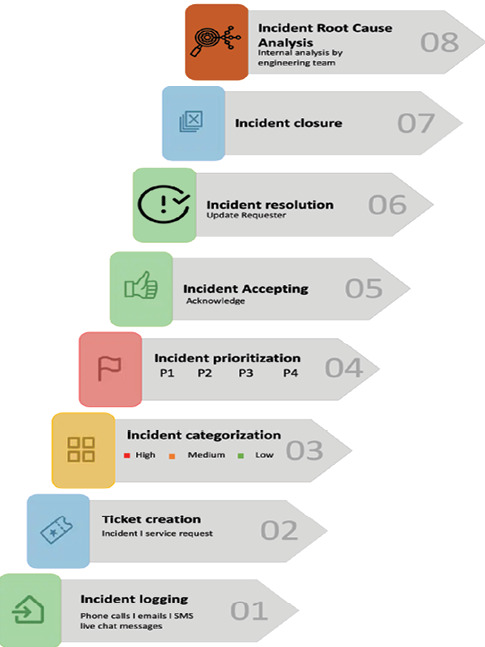
Figure 3.4: Incident stages in operations
常用工具#
- ServiceNow ITSM、Jira Service Management、PagerDuty、SolarWinds Service Desk、BigPanda
強健事件管理的最佳實踐#
- 採用會自動關聯歷史相似事件的工具
- 在工具上設定告警,新事件入隊立即通知
- 讓事件能自動接收以避免重工
- 安排運維每日 stand-up 討論優先事件,特別是大型 24/7 應用
- 建立應用錯誤與事件的相關性:高衝擊告警自動產生內部事件,讓 SRE 主動行動
範例:旅遊預訂的「找不到頁面」事件#
- 客戶在訂機票時看到「page not found」,內部自動產生工單
- 客服同步根據客戶反饋更新工單
- 工具自動歸類為「高 / P1」,自動指派到運維 / SRE 工程師
- SRE 依 runbook 進行繞過:把流量切到另一台伺服器,使用者重新可用
- 整個繞過流程不到 5 分鐘
- 並行排錯找到根因並永久修補
- 完成 RCA、更新事件並關閉
事件管理流程的真實價值,是讓「看似亂流的多次失敗」可以被結構化、優先化、可量測地處理。沒有結構,再多客服與工程師都會被淹沒。