三個交織的核心目標#
每個現代軟體組織都希望系統能:
- 隨需擴充(scalable)
- 隨時可用(available)
- 穩定可靠(reliable)
這些聽來簡單,實際做到並不容易,需要深厚的架構設計與工程紀律。
傳統擴充模式偏向手動且緩慢、資源分配低效且不平衡、回應延遲明顯;現代以 SRE 為主導的擴充模式則改為自動且即時、靠 autoscaling 最佳化資源、回應幾乎即時。
擴充性(Scalability)#
擴充性是系統在不斷增加使用者下仍能高效運作的能力。重點在於:
- 系統能依需求放大處理能力,吸收高峰流量
- 同樣重要的是能在閒置時縮小規模,節省基礎設施成本
- 系統由多項服務或元件組成,每個元件都需獨立規劃擴充
SRE 主導的自動擴充#
雲端與微服務架構出現前,系統管理員依工單手動複製伺服器,緩慢且耗時。SRE 採用「閾值觸發 + Playbook 自動化」:
- 建立量測流量的指標儀表板
- 設定閾值告警(如 80%)
- 用 Ansible 等工具撰寫 Playbook,定義「建什麼、怎麼建、何時觸發」
- 流量降下來時自動縮容
範例:銀行系統十台伺服器#
假設一套銀行系統跨地理部署 10 台應用伺服器,閾值設 80%。促銷日流量達標即觸發 Playbook,自動加一台新節點、安裝服務、套用設定;流量回落後再自動縮減。Playbook 由 SRE 團隊撰寫,內含每個服務與基礎設施的相依與主腳本。
擴充的兩種模式#
- 水平擴充(Horizontal scaling):透過複製服務、新增機器或節點分擔負載
- 適合用於:負載均衡、現有資源已達上限、節點需要維護
- 流程:負載平衡器送請求 → 監控偵測高流量 → 觸發自動化 → 複製資料庫節點與應用伺服器 → 新節點加入後負載平衡器分流
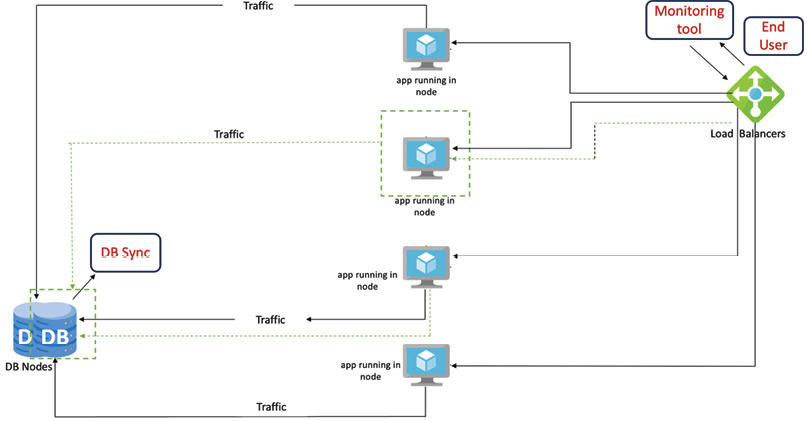
Figure 3.1: Application node and DB node horizontal scaling
- 垂直擴充(Vertical scaling):在現有機器上加 CPU 或記憶體,又稱 CPU-based scaling
- 適合用於:服務記憶體不足、現有機器尚有升級空間
擴充性的最佳實踐#
- 量測:透過混沌與負載測試找出基準與閾值;關注並發使用者數、CPU/RAM 上限、可承受的資料量、可即時新增的資源量
- 主動自動化:設定具反應性的擴充規則,並在 buffer 中保留 n+1 容量,避免新增資源時的延遲
- 元件獨立配置:不同元件擴充需求不同,必須各自撰寫獨立的擴充配置
Netflix 是經典案例:使用 AWS auto-scaling 做水平擴充,依流量動態增刪實例,確保串流不中斷。
可靠性(Reliability)#
可靠性指系統在指定期間內無故障運作的比例,是衡量系統品質的關鍵指標。100% 是不可能的,但業界工具能協助達到 99.9999% 等級。
可靠性與擴充性的關係:可擴充指能處理多大規模的請求;可靠指能在規模下不出錯。兩者結合,才構成「效能(performance)」。
打造可靠系統的方法#
- 設計審查(Design reviews):在 SDLC 初期由架構師、產品經理、SRE、DevOps、測試 SME 多角度審視設計,挖掘潛在故障與復原機制
- 程式碼審查(Code reviews):透過 pull request 流程確保程式碼品質,提早抓 syntax/semantics 問題
- 測試(Testing):包含單元、回歸(regression)、遞增(progression)、負載、混沌測試。基礎設施與程式碼的混沌測試多由 DevOps 與 SRE 進行
- 自我修復(Self-healing):系統能自動偵測並修復問題
- 基礎設施自我修復:高 CPU/記憶體時自動加機,服務當機時自動切換節點(屬於預防式作法)
- 程式碼自我修復:呼叫失敗時加入重試、用盡後自動重啟服務(屬於反應式作法)
量測可靠性的指標#
- 平均故障間隔(Mean Time Between Failures, MTBF):兩次故障之間的平均時間,越長越穩定
- 平均修復時間(Mean Time To Recovery, MTTR):從故障到恢復的平均時間,越短越好;自我修復能直接縮短 MTTR
- 故障發生率(Rate of Occurrence of Failure, ROCOF):一定期間內的故障次數
可用性(Availability)#
可用性是系統「能被存取」的時間比例。它與可靠性的差異在於:
- 可用性:系統是否能被使用
- 可靠性:系統使用時是否表現正確
系統可能可用但部分元件失靈(影響可靠性),但若系統不可用,則所有指標都無從談起。可用性是其他屬性的前提。
提升可用性的常見手段#
- 分散式系統:應用部署在多個位置的伺服器,單點故障不影響整體
- 複寫(Replication):資料在多個資料庫實例間同步,單一節點失效時不致資料遺失
- 地理分散(Geographic distribution):跨資料中心部署,並把使用者請求路由到最近資料中心
- 定期維護與更新:作業系統升級、安全修補、漏洞補丁需常態進行
主要量測方式為「上線時間佔總時間的百分比」。可用性也會受底層可靠性與擴充性影響。
三個面向交織難度高,必須在 SDLC 初期就把它們納入設計,並持續量測與優化,才能持久維持系統高效能。