案例一:金融科技組織的雲端遷移#
某金融科技組織決定把舊銀行軟體遷移到雲端、並加入手機原生應用。
專案結構#
- 業務撥出新預算
- 技術團隊到位:分析師、開發、設計、測試、產品管理、SRE、DevOps、客服
- 高階技術選型:AWS 雲端、NoSQL 與 RDBMS 並存、Java 後端、React + JavaScript 前端、GitHub 程式碼倉、應用與基礎設施監控工具、其他必要開源工具
- 一年總時程,第一個版本 5 個月內上線
- SDLC 採 Agile
軟體交付流程#
- 分析師捕捉高階功能需求(登入、帳戶資訊、轉帳、投資、買股、即時帳戶分析等)
- 各團隊架構師與 SME 共同設計資料流與架構(含基礎設施)
- 步驟 1 ~ 2 屬於規劃階段:高階設計、時程、團隊組成、招募、採購基礎設施
- UI 設計師畫線稿,同時開發團隊開始寫程式
- 產品與 AC 把專案拆成微服務,再切成模組分派給開發者,每個模組約 2 週
- DevOps 用自動化工具建置 CI/CD 管線,從 GitHub 拉程式、自動建置與部署到 dev/test/prod
- SRE 開始建監控儀表板骨架,模組完成時透過管線把監控掛上去
- 步驟 4 ~ 7 並行進行,可能重疊或錯開 1 ~ 2 週
- 測試與開發同步迭代(微服務獨立性使得平行作業可行)
- DevOps 完成 production 基礎設施後,與 SRE 共同做健全性檢查(sanity check)
- 全應用測試完、環境驗證後,DevOps 在 SRE 審核後部署到 production
- SRE 持續監控 production,遇到失敗就修補,遇到程式 bug 就回報開發
- 5 個月內完成第一版上線
上線後的事件管理#
SDLC 是持續循環。SRE 在 production 監控時發現多個 bug,客服累積使用者投訴;客服把工單轉給 SRE 佇列,這就是事件管理。SRE 預先制訂工單優先級、SLA、工作流與回應通道。
案例二:六個月以上的對帳單失敗#
承前案例,使用者反映「無法產生超過六個月以上的對帳單」。事件處理過程:
- SRE 分析後判定是某服務的記憶體不足;嘗試擴充資料庫,仍無法解決
- 將工單轉給開發;開發環境資料量不足,無法重現問題
- 由於金融科技組織的政策,敏感資料(如卡號)禁止本地儲存
- 開發花了 1 天才修復並上線,造成業務 1 天損失
- SRE 主動補上這個缺口:開發出模擬 production 資料的工具,讓開發團隊可以建立樣本資料
後續成效#
- 數天後出現類似 bug,開發直接用 SRE 工具在數小時內重現並修補
- MTTR 降低(修復更快、系統更快回到健康)
- MTBF 提升(找到根因、徹底解決,故障間隔變長)
- 整體可用性從 99.888% 回升至 99.999%
SRE 最大的價值不只是修問題,而是把「修問題的代價」內化為工具與流程,讓下一次同類問題用幾分之一的時間與成本就能解決。
SDLC 子流程詳解#
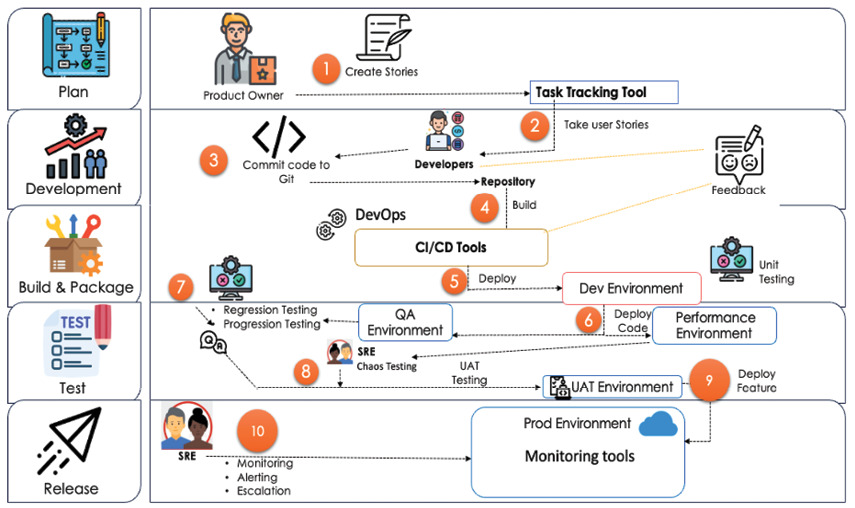
下列是程式碼從計畫到 production 的細部步驟:
- 規劃:產品負責人或 AC 拿到設計與需求 → 拆成功能(feature)→ 切成使用者故事(user story)→ 存進任務追蹤工具(如 Jira)
- 產品負責人把使用者故事指派給開發者
- 開發者本機寫程式,完成後 commit 到 GitHub 等程式碼倉
- DevOps 建立 CI/CD 管線(如 Jenkins)並交給開發團隊
- 開發者用 CI/CD 建置、打包,再部署到開發環境
- 開發團隊執行單元測試,並把同一份程式部署到測試環境與效能環境
- QA 團隊進行回歸、遞增、效能測試
- 多輪測試後,程式合併、部署到 UAT 環境(user acceptance test,模擬 production)
- SRE 在此階段做混沌測試與效能測試
- QA 與 SRE 都通過後,最終打包並部署 UAT
- UAT 通過後,DevOps 透過 CI/CD 部署到 production
- SRE 監控系統表現,必要時升級給對應團隊處理
整個流程依 sprint 週期重複。SRE 與 DevOps 不直接修補程式碼裡的 bug,但提供讓開發者快速行動的環境,避免問題擴散影響使用者。