開發與運維之間的鴻溝#
SRE 的英文字面意義就是「網站可靠性工程」。要確保系統可靠,需要同時兼顧多個工程與運維面向:
- 基礎設施管理(infrastructure management)
- 應用支援(application support)
- 可觀測性(observability)
- 可用性(availability)與擴充性(scalability)
- 工具與能力建設
莫非定律(Murphy’s law)告訴我們:「凡是可能出錯的事,最終都會出錯。」服務也不例外。我們無法消除所有故障,但能持續提升使用者體驗的可靠程度。
沒有 SRE 的真實案例#
考慮一個完全沒有 SRE、只有傳統運維團隊的電商專案:
- 採用敏捷流程
- 技術棧部署在公有雲,使用 NoSQL 資料庫、Redis、S3、Java 後端與最新工具
- 可觀測性工具:ELK、Grafana、AppDynamics、Splunk
- 團隊組成:產品管理、UI 設計、敏捷教練、開發、QA、效能測試、DevOps、運維、客戶服務
故障處理流程#
當「無法付款」的客戶投訴出現時,工單流轉路徑如下:
- 客戶服務 → 運維團隊
- 運維 L1 排查無果 → 轉 DevOps
- DevOps 確認非基礎設施問題 → 轉開發
- 開發鎖定根因並修復、部署熱修補
整個過程花了約三天,期間使用者無法正常使用功能,組織直接承受營收損失與信任損害。
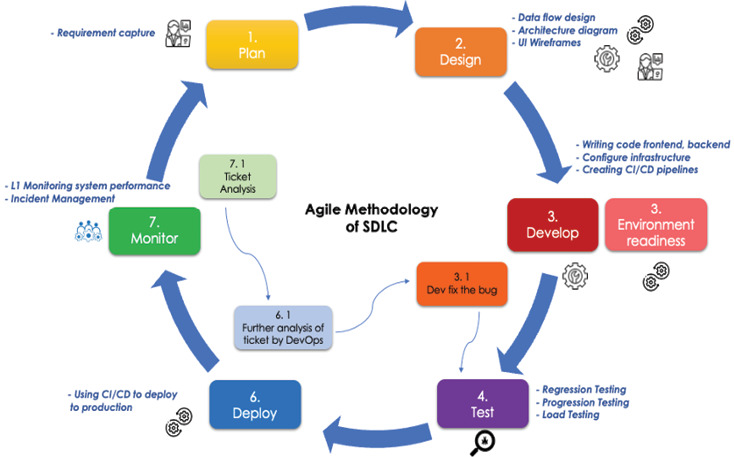
Figure 1.5: SDLC phases without SRE (replaced by DevOps and L1 ops)
有 SRE 的對照案例#
在同一個專案導入 SRE 後:
- SRE 同時涵蓋開發與運維能力
- SRE 建置可自動修復的告警與監控儀表板
- SRE 自行開發了一套內部排錯工具,可重現過去事故並提供根因建議
故障時的處理路徑變成:
- SRE 在客戶察覺前就收到失敗請求告警
- SRE 透過內部工具比對歷史事故、快速指出根因
- 直接與該模組開發者協作修補
- DevOps 透過 CI/CD 部署熱修補
同樣的事件,從三天縮短為幾小時,且大多數使用者完全沒察覺異常。
SRE 為何不可或缺#
從上述對照可以看出,SRE 對 SDLC 的價值不只是「修問題的人」:
- 跨界技能組合:SRE 團隊由開發者、基礎設施工程師、系統工程師與支援工程師組成
- 多技能訓練:能同時處理排錯、開發工具、設定基礎設施、建立可觀測性儀表板
- 降低人因負擔(toil):透過自動化減少重複性勞動
- 守住可靠性、擴充性、可用性的底線:即便有變更上線,也能維持系統穩定
- 協助商業成長:減少當機與客訴,提升新客戶體驗與留存
投入 SRE 的成本與回報#
- SRE 工程師具備跨領域技能,市場價格相對較高,組織常需提高 IT 預算
- 從 ROI 角度看,可靠性與可用性的提升換來的是穩定營收與品牌信任,回報相當可觀
- 預算有限的小型專案可由 DevOps 團隊兼任 SRE 職能;但大型專案應分設 DevOps 與 SRE,避免角色模糊與人力過勞
是否獨立建置 SRE 團隊,取決於系統規模與容錯成本。判斷準則很簡單:當一次故障的損失大於 SRE 一年的人力投入,就該認真考慮獨立 SRE。