席佛把流行病做為複雜系統的最後一個範例。從 1976 年福特政府的豬流感慘案、2009 年的 H1N1 大流行,到 SIR 模型在芝加哥麻疹爆發與舊金山愛滋悖論中的失靈,本章所要回答的是:當預測對象同時帶有指數成長、回饋迴圈與資料污染時,「模型」究竟該扮演什麼角色?
1976 年豬流感:當警鈴遠大於疫情#
1976 年 1 月,紐澤西州迪克斯堡(Fort Dix)軍營:
- 19 歲士兵路易斯(David Lewis)發燒卻仍隨隊行軍 50 英里,最後病倒身亡,肺部充血——死於一種非典型重症流感。
- CDC 鑑定後發現,他與其他幾百名感染者所感染的並非當年流通的 A/Victoria,而是 1918 年西班牙流感同型的 H1N1——曾奪走全球約 5,000 萬人命。
- 當時學界流傳「重大流感大約每十年會大流行一次(1938、1947、1957、1968)」,1976 因而被認為「該輪到了」。
衛生部長馬修斯(F. David Mathews)公開預測「將有 100 萬美國人死亡」。
但醫學專家私下評估的最壞情境機率僅 2–35%。福特總統決定大規模疫苗計畫(2 億劑、$1.8 億預算),把它定義成「金錢 vs 生命」的賭注。
夏季南半球疫情季沒有出現 H1N1 蹤跡;CDC 副主任、WHO、《刺胳針》、《紐約時報》紛紛質疑警報。但白宮反向加碼,推出戲劇化公益廣告。十月,民眾開始接種:
- 三名匹茲堡長者、兩名奧克拉荷馬市長者、一名邁阿密長者接種後過世——皆無證據與疫苗有關,但媒體未做統計脈絡解讀,疫情恐慌轉為疫苗恐慌。
- 大約 500 例格林—巴利症候群(Guillain–Barré syndrome)——一種罕見自體免疫癱瘓,發生率為一般族群的 10 倍。
- 12 月 16 日,計畫終止。
結局:H1N1 從未在迪克斯堡之外擴散,當年 A/Victoria 死亡人數低於平均。
- 福特當年連任失敗。
- 政府因法律豁免條款承擔 26 億美元賠償索賠。
- 此後幾年願意接種流感疫苗的美國人銳減至約 100 萬,若 1978–79 真的爆發強毒株,將更加致命。
2009 年 H1N1:先漏看、再過度預警#
流感主要由海鳥(信天翁、海鷗、鴨、鵝)攜帶基因跨洲,再傳給雞與豬。
- 雞會生病但能存活並把病毒傳給人類。
- 豬同時對人、禽、自己的病毒易感,是混合與突變的最佳容器。
孵化新型流感的「完美三條件」:人豬密集接觸、靠海有候鳥、開發中國家衛生條件較差——這描述的是中國、印尼、泰國、越南。但 2009 年的 H1N1 起源於墨西哥韋拉克魯斯州(Veracruz)——同樣符合這三項,只是當時學界都把目光放在亞洲的 H5N1。
預測歷程的兩段失誤:
- 第一波過度警報:墨西哥約 1,900 例、150 死,致死率約 8%(高於西班牙流感);歐洲對美墨發布旅遊警告,香港新加坡股市重挫。
- 回落樂觀:美國 4/26–5/11 從 20 例暴增到 2,618 例,但僅 3 死,致死率與一般流感相當;CDC 一週內就建議重開停課學校。
- 第二波警報:6 月 WHO 升級為第 6 級(最高)大流行,學界擔心步上 1918 二波、三波的後塵;8 月美國官方提出「合理情境」可能感染半數人口、9 萬人死亡。
- 實際結果:約 5,500 萬美國人感染(佔人口 1/6),約 11,000 人死亡,致死率僅 0.02%;當季流感死亡人數甚至略低於平均。
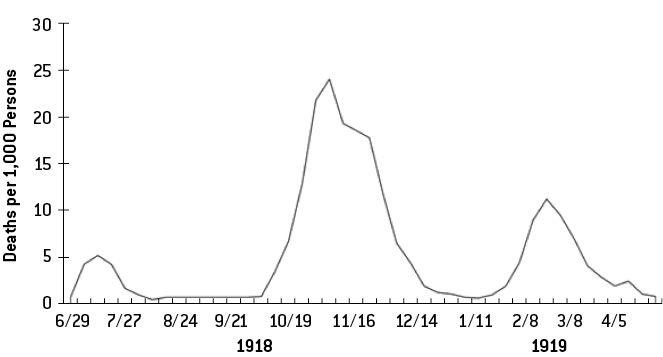
Figure 7-1: 1918–19 H1N1 死亡率
外推法(extrapolation)的危險#
「外推」就是假設當前趨勢無限延伸——常常錯得很離譜。
- 1894 年《泰晤士報》預測:到 1940 年代,倫敦每條街道將被 9 英尺深的馬糞覆蓋;十幾年後福特 Model T 解危。
- 17 世紀經濟學家佩蒂(William Petty)依當時人口成長率推估,2012 年世界人口約 7 億(實際逾 70 億,差 10 倍)。
- 1968 年艾爾利希夫婦(Paul Ehrlich, Anne Ehrlich)的《人口炸彈》預言 1970 年代將餓死數億人;他們假設「自由戀愛時代」的高生育率會延續,忽視女性教育與就業興起會壓低生育。
- 1980 年代初按 AIDS 累積病例外推,會在 1995 年得出 27 萬例;實際為 56 萬例,外推法低估近一倍。
- 但即使方法用對,外推法在指數成長時誤差區間極寬(35,000 ~ 180 萬例之間),預測力有限。
流感預測為何在 2009 年失準#
兩個關鍵變數:
- 基本再生數(R₀, basic reproduction number):在無疫苗、無隔離下,每個感染者預期傳染給多少人。
- 季節性流感 ≈ 1.3
- 1918 H1N1 ≈ 3
- 2009 H1N1 ≈ 1.5
- SARS、HIV/AIDS ≈ 3.5
- 天花 ≈ 6、麻疹 ≈ 15、瘧疾 ≈ 150
- 致死率(case fatality rate):死亡數 ÷ 病例數。
這兩個量都需要疫情走完才知道,但學界必須在初期、資料雜訊大時就外推。
致死率是分子與分母都有不確定的比值。
- 分母被低估:墨西哥的醫療回報遠不如美國,許多輕症未進入統計,因此 1,900 例僅是冰山一角。
- 分子被高估:實驗室複檢顯示,僅約 1/4「歸因 H1N1」死亡確實有 H1N1 跡象。
- 媒體效應:H1N1 進入美國後成為熱話,輕症也大量被通報,進一步扭曲分母。
愛滋早年也是同樣現象:因為汙名與不熟悉,很多疑似病例未被診斷或被誤診,等多年後重新檢視老病歷才有較準確估計。
自我實現與自我抵消的預測#
自我實現(self-fulfilling):預測本身改變人們行為,反過來讓預測成真。
- 2012 愛荷華初選 CNN 民調出現桑托倫(Rick Santorum)跳升至 16% 的離群數據,引發媒體聚焦,最終真的讓他贏。
- 時尚界提早一年「決定」流行色——只要設計師、模特兒、店面同步轉向棕色,公眾跟風使預測成真。
- 自閉症診斷數量與媒體出現「autism」一詞的頻率幾乎完全同步:哈佛公衛學者奧佐諾夫(Alex Ozonoff)指出,越被討論的疾病,回報率越接近 100%。
自我抵消(self-cancelling):預測讓人們做出反向行動,反而使預測落空。
- GPS 導航推薦同一條「較快」路線給所有駕駛,路徑反而塞車變慢。
- 流感預測的部分目的本就是讓人改變行為(接種、洗手、戴口罩),「最有效的預測」可能因此看起來「失準」。
簡單但要「精緻地簡單」#
芬蘭學者寇可(Hanna Kokko)把建模比喻為製圖:太少細節無用,太多細節讓旅人迷路。
第五章已示範過:太複雜的模型會把雜訊當訊號(過度配適);但太簡單的模型則會讓重要差異被均質化掉。
最基本的傳染病模型是 1927 年提出的 SIR 模型:
- S(Susceptible)→ I(Infected)→ R(Recovered)。
- 疫苗就是「跳過 I」直接到 R 的捷徑。
- 數學僅幾條微分方程,筆電幾秒可解。
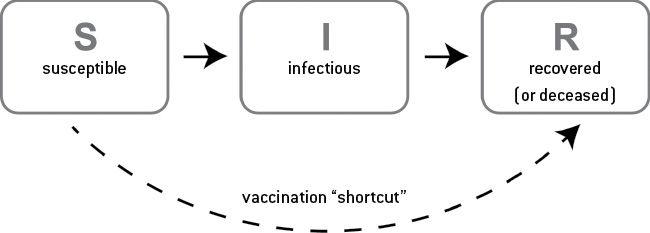
Figure 7-5: SIR 模型示意圖
但 SIR 假設整個人口同質且隨機混合——這個假設在多種情境下都被打破。
舊金山愛滋悖論:行為比生物更靈活#
1990 年代末到 2000 年代初,舊金山男同志社群的無套性行為明顯增加:
- 解釋包括安非他命使用增加、抗反轉錄病毒治療延長壽命、年輕世代對 1980 年代愛滋陰影較淡。
- 各種梅毒與淋病的新增病例同步上升(梅毒從 1998 年的 9 例升到 2004 年的 502 例)。
- 但 HIV 新增診斷數沒有跟著上升,反而在 2004 年達到流行病學起算最低點。
解釋:男同志社群越來越擅長「血清狀態配對(serosorting)」——刻意選擇與自己 HIV 狀態相同的伴侶。
- 公衛宣傳轉向「協商安全(negotiated safety)」可能起到正面作用。
- 網路逐漸取代酒吧成為媒合場域,個人檔案揭露 HIV 狀態使溝通更容易。
- SIR 假設「人人同等易感」,當風險不對稱地分布在子族群時,模型會嚴重高估 HIV——你不會走進雜貨店就染上 HIV。
芝加哥麻疹與迪克斯堡:模型在哪裡失靈#
麻疹本應是 SIR 模型最容易處理的疾病:可血液檢測、僅一種變異株、感染必有症狀、終生免疫。
- 但 1980 至 1990 年代初,芝加哥連年爆發麻疹,每年高達一千名孩童感染——市府甚至派護士挨家挨戶接種。
- 達姆(Robert Daum)醫師發現問題在芝加哥的「鄰里隔離」:南區貧窮、非裔多的社區疫苗接種率低,這些孩子上同一間學校、互相打噴嚏,違反了 SIR 中「隨機混合」的假設。
同樣的「非隨機混合」可能誤導了 1976 年的迪克斯堡危機。
- 軍營空間擁擠、共享物資、體能高負荷、有「生病也要報到」的文化——疾病傳播條件遠比一般社區強。
- 230 例的快速擴散讓學者誤以為 R₀ 接近 1918 年的 3。
- 後續研究顯示 A/New Jersey/76 的 R₀ 僅 1.2,與普通季節性流感相當;它在迪克斯堡耗盡可感染對象後就熄火,根本未具大流行潛力。
席佛強調並非「複雜模型一定優於簡單模型」——複雜模型同樣可能高自信、過度配適。但模型應「精緻地簡單(sophisticatedly simple)」,能反映現實中重要的不對稱與群聚結構。
SimFlu:以代理人模擬整座城市#
氣象預測的成功部分歸功於對大氣的物理模擬。流行病領域則正在發展對應的方法——「代理人基模型(agent-based modeling)」。
匹茲堡大學的 FRED(Framework for the Reconstruction of Epidemic Dynamics):
- 在電腦中建構整座匹茲堡——每個人都是代理人,有家庭、社交網路、學校、工作場所與信念。
- 學校大小不一、孩子並非都讀最近的學校,模擬出非隨機混合。
- 模型可呈現 zip code 等級的疾病擴散波動,需要超級電腦運算。
這類模型對行為資料極依賴,但人們會說謊。
- 受訪者宣稱洗手、戴保險套的頻率,遠高於實際。
- 民眾接種意願與「自身對疾病風險的感知」高度相關,而這種感知會隨身邊有人生病、新聞報導而動態改變——再次帶入自我實現/抵消的迴圈。
芝加哥團隊則用代理人模型研究 MRSA(對抗生素具抗藥性的金黃色葡萄球菌),它的傳播路徑包含擁抱、共用毛巾、運動更衣室、甚至監獄環境。
即便如此,多數團隊仍只把代理人模型用於「為了洞見而建模(modeling for insights)」,而不是直接做預測。
部分結論已經有實際指引:
- 學校關閉太短或太早可能反而適得其反(匹茲堡團隊)。
- 芝加哥內城的 MRSA 集中現象與庫克郡監獄的人流進出有關(芝加哥團隊)。
預測困難時,該如何前進#
席佛訪談的流行病學家普遍對自己模型的限制保持謙遜。Lipsitch:「依靠 1918、1957、1968 三個資料點做預測本身就很愚蠢,能做的就是為不同情境準備計畫。」
如果你做不出好預測,假裝能做反而有害。
醫療人員深諳「Primum non nocere(首先不要造成傷害)」——劣質模型在醫學裡會死人,這份戒慎讓他們對統計方法的應用比其他領域更講究。
統計學家 George E. P. Box 的名言貫穿本章:
「所有模型都是錯的,但有些模型是有用的。」
- 模型必然簡化宇宙,否則就不是模型。
- 「貓的最佳模型就是一隻貓」——任何更小的模型都得捨棄細節。
- 細節是否關鍵,視問題與要求精度而定。
- 連語言都是一種模型——「黃色」對你我足夠,對平面設計師則需要 Pantone 107。
- 好模型即使預測錯誤仍有價值:奧佐諾夫說「預測平均都會錯,重點是知道它怎麼錯、錯了該怎麼辦、如何把代價最小化。」
席佛在本章收尾把全書分為兩半:
- 前半部主要講「我們的近似在哪裡服務了我們、又在哪裡背叛了我們」。
- 後半部要展示如何一步步把這些近似變得更好——下一章就是貝氏定理登場。