席佛把經濟預測寫成「過度自信、低估不確定性」的範例:政治民調至少會附上誤差範圍,但 GDP、就業、油價的預測通常以單一數字呈現,假裝精準。本章用 1997 年大福克斯洪災、2008 年金融危機、預測者社群的長期紀錄,逐一拆解經濟預測為何屢屢失準,並提出兩條改善路徑——供給面的預測市場、需求面的更挑剔閱聽人。
為什麼一英寸的偏差會上頭條?#
一則《丹佛郵報》2011 年 7 月 9 日的標題:
「失業率意外跳升至 9.2%,市場受挫」。
真正的「意外」是經濟學家原本預期 9.1%——一個 0.1 個百分點的差距能上頭條,給人一種感覺:經濟預測平常一定非常準。
事實正好相反:
- 經濟預測極少能在轉折點前數月做出有意義的判斷。
- 1990、2001、2007 三次衰退被官方認定後,多數經濟學家當下仍不認為當時已陷入衰退。
- 但預測者把不確定性當敵人:刻意降低模型「看起來」的不確定性,並不會改善真實預測力,只會讓社會在風暴來臨時更不設防。
大福克斯:把不確定性藏起來的代價#
1997 年 4 月,北達科他州大福克斯(Grand Forks)的紅河暴漲,淹進市區 2 英里以上:
- 全市 5 萬居民撤離,七成五房屋受損,整治成本以數十億美元計。
- 比起颶風或地震,這是一場可預防的災難——只要預先補強堤防、改道分洪,就能減輕損失。
NWS 預測紅河水位將升至 49 英尺;當地堤防為 51 英尺。
- 但 NWS 沒有同步說明歷史誤差約 ±9 英尺——意即堤防被淹沒的機率高達 35%。
- 預測員後來向研究者承認,他們怕公開不確定性會折損權威。
- 結果河水實際升至 54 英尺,39 英尺的差距遠遠超過設計上限。
- 對居民而言,「49 英尺」彷彿是「最大可能值」,幾乎沒人買洪水險。
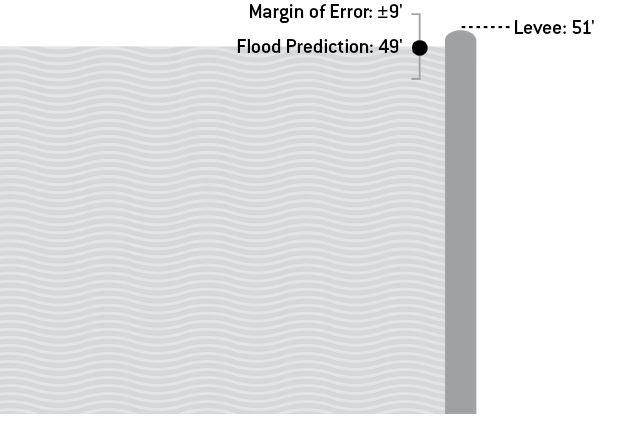
Figure 6-1: 含誤差範圍的洪水預測
經典笑話:一位統計學家走過一條平均深 1 公尺的河,溺死了。
平均值無法描述風險的全貌——只要實際稍稍偏高,整個小鎮就被沖毀。NWS 此後改變政策,把不確定性納入溝通,但這份覺悟在經濟預測界仍極為罕見。
經濟學家是理性的嗎?#
費城聯邦準備銀行的「Survey of Professional Forecasters(SPF)」是少數要求經濟學家明確列出機率分布的調查。
- 投擲兩顆骰子的「正確預測」並非一個數字,而是一張機率分布表(圖 6-2)。
- 經濟學家要對 GDP 給出一系列區間機率,例如 GDP 落在 2–3% 的機率、3–4% 的機率等。
2007 年 11 月,金融危機的官方起點僅一個月後,SPF 仍預期 2008 年 GDP 微幅成長 2.4%。
- 他們給「2008 年 GDP 任何萎縮」僅 3% 機率。
- 給「萎縮 ≥2%」僅 1/500 機率。
- 實際 GDP 萎縮 3.3%——遠遠超出他們的尾端尺度。
席佛把 1993–2010 年 SPF 的「90% 預測區間」與實際 GDP 對比:
- 18 年裡,實際值落在區間外的次數有 6 次——本應僅約 2 次。
- 把樣本拉回 1968 年起,落在區間外的次數接近一半。
- 經濟學家號稱的 90% 區間,真實覆蓋率可能不到 50%。
- 真正合理的 90% 區間寬度約為 ±3.2 個百分點(總跨度 6.4 個百分點)。
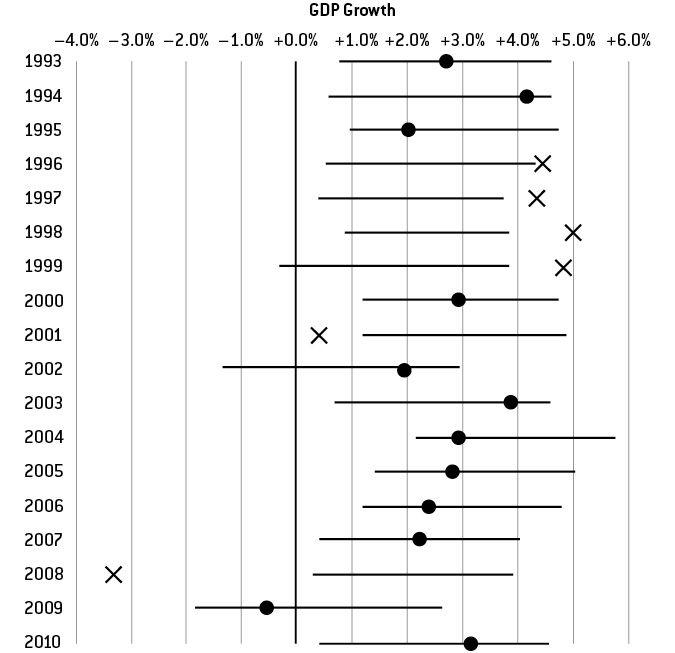
Figure 6-4: GDP 預測 90% 區間 vs. 實際結果
換句話說,當電視說「明年 GDP 將成長 2.5%」時,事實合理區間是 -0.7%(衰退)到 +5.7%(榮景)之間。
1990 年代各國 60 次衰退中,經濟學家只在事前一年成功預測了 2 次。
過度自信並非經濟學家獨有,但他們有更多理由可以避免——預測歷史可上溯到 1946 年的 Livingston Survey,回饋訊號充足,卻仍未矯正。原因或許就在於:「他們做出有偏差的預測,正反映了他們的誘因結構。」
「沒有人懂」:與哈茨烏斯的對話#
哈茨烏斯(Jan Hatzius)是高盛首席經濟學家,紀錄優於同業:
- 2007 年 11 月發表〈Leveraged Losses: Why Mortgage Defaults Matter〉,預測屋主違約將引發信貸與金融體系的骨牌效應。
- 2009 年 2 月白宮宣稱失業率將降至 7.8% 之際,他預測會升到 9.5%(實際為 9.9%)。
席佛問他什麼是預測經濟最大的挑戰,哈茨烏斯坦言:「沒人真的懂。要預測景氣循環非常困難,理解像經濟這樣複雜的有機體很不容易。」他歸納出三大根本障礙:
- 因果難辨:光靠經濟統計很難分辨因果。
- 目標移動:經濟持續演化,這個循環的關係未必適用下個循環。
- 資料雜訊極高:經濟學家所擁有的原始資料品質本就不佳。
因果與相關:超級盃、過度配適、偽訊號#
政府每年產出 4.5 萬個經濟指標,私部門資料商追蹤多達 400 萬個。
- 二戰後僅 11 次衰退;用 400 萬個輸入去解釋 11 個輸出,必然出現大量偽相關。
- 經典案例:1967–1997 年「超級盃指標」,原 NFL 球隊勝出當年股市平均漲 14%,原 AFL 球隊勝出則跌 10%。31 年命中 28 年,標準統計顯著性檢定會說它是 470 萬分之一的巧合。
- 1998 年丹佛野馬(原 AFL)拿冠軍,股市卻在網路熱中漲 28%。
- 自 1998 年後,AFL 勝出反而對應股市相對好 10%。
- 同樣道理,威力球頭獎機率 1/1.95 億,但每幾週仍有人中——數量夠多就會有偽訊號。
經濟學家會把「具經濟意涵」的變數視為先行指標,但很多 1990、2001 年衰退的先行指標,到 2007 年衰退時已淪為落後指標。
Conference Board 的 Leading Economic Index 也曾在 1984 年連續三個月下滑警示衰退,但當年經濟以 6% 速度成長。
不分青紅皂白把可量化的指標都丟進模型,很容易就把雜訊當訊號——典型的過度配適。
「相關性不等於因果性」是老調,實際運用卻不容易:
- 失業率有時是落後指標(企業確認復甦才招人)、有時是先行指標(失業者沒錢消費)。
- 消費者信心可以提早警示衰退、也可能在復甦後仍長期低落,難以一概而論。
經濟版的「測不準原理」#
更棘手的迴圈:預測本身會改變經濟。
- 若預測即將衰退,政府與聯準會必然介入;預測者必須同時預測政策。
- 諾貝爾獎得主盧卡斯(Robert Lucas)1976 年指出:模型用的歷史資料,本身就是當時政策的產物。
- LSE 的古德哈特法則(Goodhart’s law):當政策開始鎖定一個變數,這個變數作為指標的價值就會喪失。
- 房價就是現成的例子——若政府人為拉抬,數字會變漂亮,卻不再代表經濟健康。
在物理上這常被誤稱為「海森堡測不準原理」,但其實更接近「觀察者效應(observer effect)」:當你開始量測一個系統,它的行為就開始改變。
多數統計模型假設自變數與應變數可被分離;但對經濟而言,所有東西都揉在同一鍋。
不斷變化的經濟結構#
歐肯法則(Okun’s law)指出,戰後 1947–1999 年,工作成長率約為 GDP 成長率的一半(GDP 4% → 工作 2%)。
- 該關係在 21 世紀變弱:2009 年刺激方案後,依歐肯法則本應創造約 200 萬個工作,實際反而又流失 350 萬個。
- 哥倫比亞大學薩克斯(Jeffrey Sachs)認為,這反映美國的結構性問題:來自他國的競爭、製造/服務失衡、人口老化、中產萎縮、國債累積。
「Long Boom(1947–1999)」期間,美國僅 15% 時間處於衰退。
1900–1945 為 36%;2000 年代以來的高波動,可能才更接近長期常態。Long Boom 中又有 1983–2006 的「大穩定期(Great Moderation)」,衰退時間僅 3%——但增長仰賴政府與消費者債務及資產泡沫。
把模型校準在 Great Moderation 上,等於假設未來繼續風平浪靜——這是 2007 年聯準會與市場大幅低估金融危機深度的重要原因。
不要丟掉資料#
聯準會公開市場委員會 2007 年 10 月會議紀錄裡,連「recession」這個字都沒出現過。
- 他們依賴的是一份僅涵蓋 1986–2006 年(兩次溫和衰退)的研究。
- 該研究自己警告:「這是隱含『大穩定期會持續』的假設。」
- 席佛把 1968–1985 與 1986–2006 兩段時期 SPF 的預測 vs. 實際攤開比對:
- 前段(高波動)的預測與實際有合理相關性。
- 後段(平穩)的點集中在 2–5% 之間,平均誤差小,但預測與實際間幾乎沒有相關。
平均誤差小,是因為波動本來就小,並非預測者進步——好比比較檀香山與水牛城的氣象預測。
預測者幾乎不該丟掉資料,尤其在像衰退、總統大選這種樣本本就稀少的問題。丟掉資料常常是過度自信或過度配適的徵兆。
經濟資料本身就充滿雜訊#
哈茨烏斯:「為什麼大家不給區間?因為他們覺得難堪。」
- GDP 等變數都會被多次修正,有時長達數年。
- 2008 第四季 GDP 初估萎縮 3.8%,後修正為近 9%——若白宮 2009 年 1 月就知道實情,刺激方案可能更大、或設計成更長期解方。
- 1965–2009 年間,季度 GDP 平均修正幅度 1.7 個百分點,初估的真實誤差為 ±4.3%。
- 1977 第四季 GDP 初估 4.2% 成長,最終修正為 -0.1%。
不僅難以預測經濟去哪裡,連「現在在哪裡」都不好說。對經濟預測者要有合理的同情。
巴西的蝴蝶與德州的失業#
經濟和大氣一樣是動態系統,初始條件也充滿不確定:
- 一場日本海嘯或長灘罷工,能改變德州某人是否找到工作。
- 不過氣象學有「硬科學」(流體力學、化學)撐底;經濟學在泡沫與恐慌期,因人類行為的回饋迴圈,因果尤其模糊。
哈茨烏斯 2007 年 11 月 15 日的故事是「對的,且因為對的理由」:
「2,000 億美元的信貸損失,會迫使高槓桿投資人縮減 2 兆美元的放款,足以引發嚴重衰退。」這不僅是資料的故事,更是「經濟的故事」——把因果脈絡描繪清楚。
對比預測公司 ECRI 在 2011 年 9 月的「雙重衰退」警示:
- 他們強調「不基於一兩個指標,而是幾十個專屬指標」。
- 缺乏經濟實質的解釋,僅是「數據叫我這樣說」。
- ECRI 公司在 2004 年的書中還寫道:「就像你開車不必懂引擎原理,要解讀經濟也不必理解所有細節。」
- 結果 ECRI 預警後 5 個月,S&P 500 漲了 21%,2011 第四季 GDP 健康成長 3.0%;ECRI 隨後將預警延伸到 2012。
大數據時代越來越多人聲稱「資料夠多就不需要理論」——對經濟這種雜訊極高的領域,這是錯誤態度。
統計推論若無理論或對根因的深度思考做後盾,就只是把雜訊當訊號。
偏差為何「理性」?#
跨領域的研究顯示:群體預測通常比個人預測準。
- SPF 的群體 GDP 預測比個別經濟學家準約 20%;對失業率約 10%、對通膨約 30%。
- 但這不是讓個人推諉「我反正不重要」的藉口——群體預測仍由個體組成,整體仍有大幅進步空間。
- 純統計模型也不是萬靈丹:BSF 前副總裁 McNees 的研究顯示,加入判斷修正可讓預測再準 15%。
「理性偏差(rational bias)」:當你的預測冠上你的名字,誘因就變了。
- 名氣低的小公司,做極端預測有上頭條的機會,即使常錯也划算。
- 高盛這類大公司則傾向往共識靠攏,風險過大會被放大檢視。
- SPF(匿名)參與者在預測 GDP 與失業率上,長期略勝於 Blue Chip(具名)的同業——名譽顧慮讓預測變糟。
克服偏差:供給面與需求面#
改善預測的兩條路:
- 供給面:建立預測市場(prediction market),讓人為自己的預測下注。
- 喬治梅森大學的漢森(Robin Hanson)主張此路,並寫部落格《Overcoming Bias》。
- 為 GDP、失業率等總體變數建市場,可提供即時資訊、懲罰過度自信,並讓股票市場上的宏觀風險可被避險。
- 需求面:讀者要更挑剔。
- 把焦點從「黑盒子」式的隨機指標模型轉向具經濟實質的論述(如哈茨烏斯)。
- 把不確定性納入正式呈現——例如初估 GDP 也應像政治民調一樣附上誤差範圍。
信心不等於準確;兩者甚至常呈反相關。
當我們不允許預測者完整、誠實地交代風險時,無論是經濟還是其他領域,危險都會悄悄逼近。