概論#
藥物是分子,其效應可在生物組織的各層級被量化——從分子結合,到細胞訊號,到組織與器官,到整體動物,再到臨床病人群體(圖 7.1)。
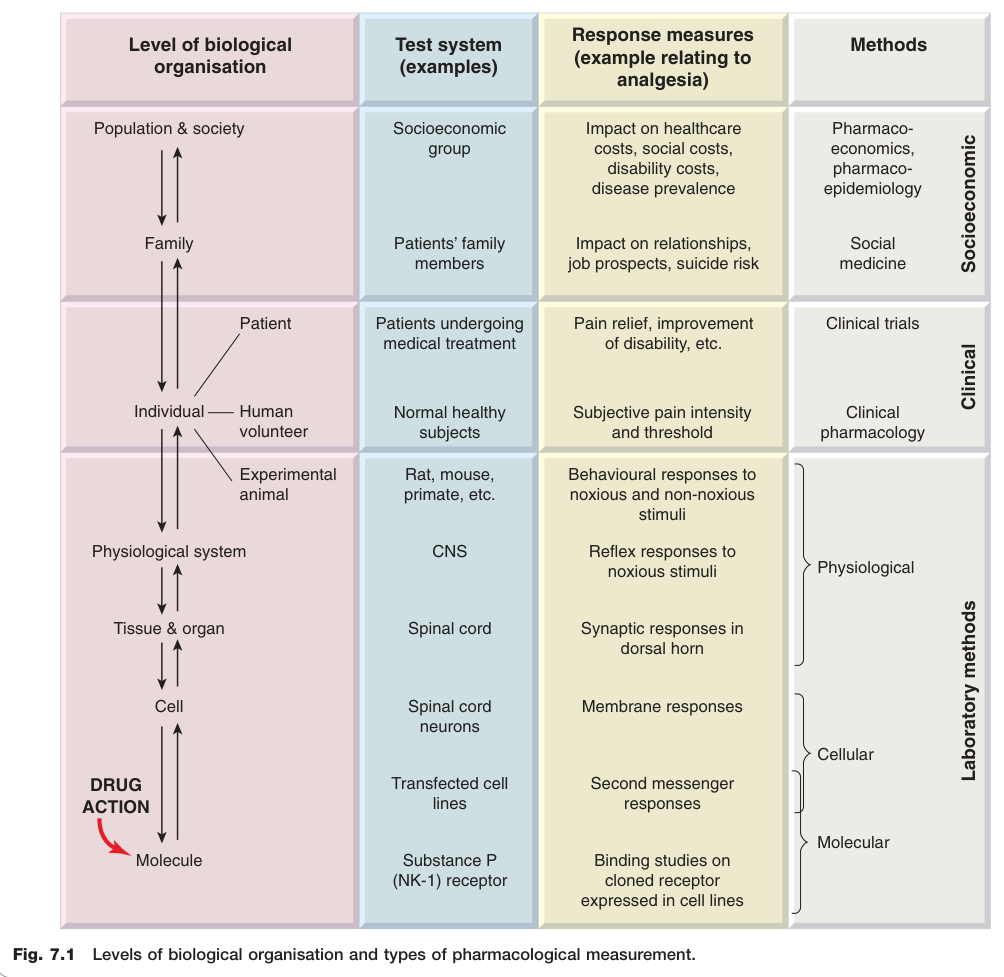
Figure 7.1:生物組織各層級與藥理量測類型
Gaddum(加達姆)在 1942 年說:「一門科學成熟的標誌,是它變得定量化。」本章的核心,便是介紹如何在上述各層級嚴謹地量測藥物效應。
本章涵蓋四個主軸:
- 生物檢定(bioassay)的基本原理
- 人類藥理學研究的方法
- 動物疾病模型
- 臨床試驗設計與效益風險評估
生物檢定#
定義與用途#
生物檢定(bioassay):利用生物反應的大小,來估計物質的濃度或效力。其主要用途:
- 測量新的或化學結構未知物質的藥理活性
- 研究內源性介質(endogenous mediator)的功能
- 測量藥物毒性與不良效應
- 作為新藥開發的標準化工具(尤其是生物製藥)
以往用生物檢定測量血中藥物濃度的技術,現已大多被分析化學方法取代。但在生物製藥(biopharmaceuticals)的批次標準化上,生物檢定仍不可或缺,因為醣基化(glycosylation)的差異不能被免疫分析偵測,卻會影響生物活性。
使用標準品#
生物系統個體間差異甚大,因此生物檢定必須採用相對效力的概念,而非絕對單位。歷史上曾出現各種「鴿子單位」、「小鼠單位」等無法跨實驗室比較的絕對單位,造成文獻混亂。
正確做法是:將未知製劑(U)與標準品(S)在同一生物系統上相互比較,得出效力比值(potency ratio, M)。英國生物標準管制委員會(UK National Board for Biological Standards Control)負責維護各類激素、抗血清的參考標準品。
生物檢定的設計#
比較兩製劑效力的標準方法是平行線檢定(parallel line assay):
- 在對數劑量-效應曲線的線性段各取兩個劑量(2+2 設計)
- 要求標準品與未知品的劑量-效應曲線必須平行(圖 7.3)
- 以曲線間的水平距離(log M)估計效力比值
- 隨機化給藥順序,並以統計分析計算信賴區間
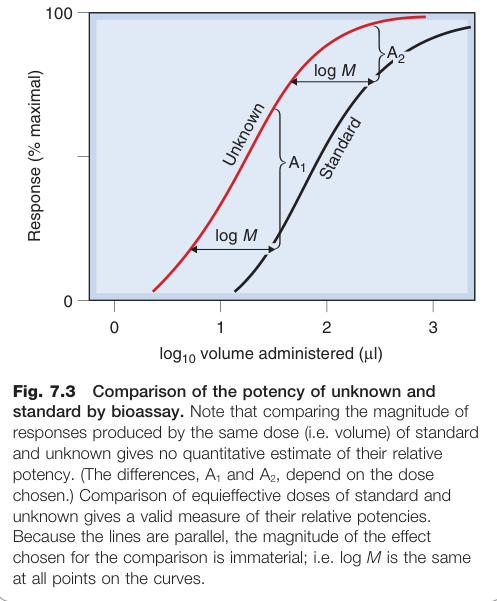
Figure 7.3:生物檢定中未知品與標準品效力比較的平行線法
若兩條劑量-效應曲線不平行(例如比較全效劑與部分效劑,或機制不同的兩藥),就無法以單一比值定義相對效力,必須測量效力的多個維度。利尿藥的比較即為典型例子:「低上限」與「高上限」利尿藥的效力無法以單一比值呈現。
效應可以是:
- 分級效應(graded response):連續量,如血壓變化
- 定性效應(quantal response):全有全無,如出現驚厥的動物比例
兩種效應使用不同的統計方法。
生物測試系統#
從 1960 年代起,藥理學家逐步發展出各種**體外(in vitro)與體內(in vivo)**測試系統,涵蓋從分子層級到臨床層級的整個範圍:
- 分子層級:放射性配體結合試驗(binding assay),1970 年代引入
- 細胞層級:表達特定人類受體亞型的工程細胞株,廣泛用於藥物篩選
- 組織層級:離體器官灌流
- 動物層級:整體動物實驗
**級聯超灌流(cascade superfusion)**技術(Vane 等人):讓生物樣本依序流過一系列選擇性測試器官,根據各器官的反應模式鑑定未知活性物質(如前列腺素類、一氧化氮)。
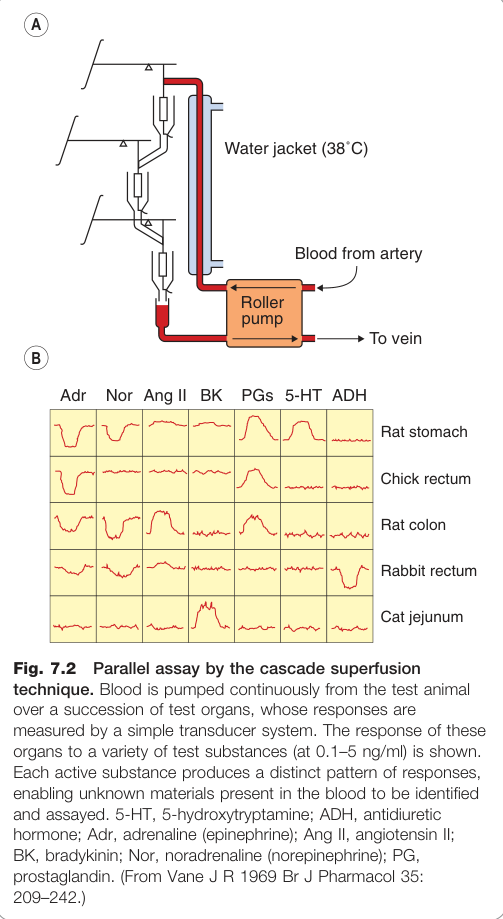
Figure 7.2:級聯超灌流技術的平行生物檢定示意
動物疾病模型#
有效模型的條件#
一個好的動物疾病模型應具備:
- 表面效度(face validity):表現型類似人類疾病
- 建構效度(construct validity):病因相似
- 預測效度(predictive validity):對治療的反應相似
常見局限#
- 精神疾病:躁症、妄想、偏頭痛、自閉症等在動物幾乎無法重現,無表面效度
- 病因不明的退化性疾病(如阿茲海默症、帕金森病):難以達到建構效度
- 以藥物反應選擇的模型:可能錯過具有全新作用機制的藥物
許多在動物模型高度有效的藥物,在人體試驗中卻無效(例如腦缺血保護劑、物質 P 拮抗劑的止痛效果)。動物模型的局限是從基礎研究到臨床治療之間最主要的瓶頸。
基因與轉殖動物模型#
選擇性繁殖可產生具特定遺傳特徵的純系動物,例如:
- 自發性高血壓大鼠
- 遺傳性肥胖小鼠(leptin 基因缺失,具良好的表面效度與預測效度,但因人類肥胖症者通常不缺 leptin,建構效度差)
- 癲癇易發犬與小鼠
**轉殖動物(transgenic animals)**透過修改生殖細胞系的 DNA 來模擬疾病:
- 剔除(knockout):使特定基因失活
- 導入(knock-in):引入新(如人類)基因,或致病性突變
- 過表現(overexpression):插入額外基因拷貝
- 條件性突變(conditional mutagenesis):利用 Cre-Lox 系統,在特定時間點啟動突變,避免發育期的致死效應
目前大多數轉殖技術在小鼠中較為成熟,斑馬魚、果蠅、秀麗隱桿線蟲也日益用於藥物篩選。
典型例子:
- 過表現突變型澱粉樣前驅蛋白或早老素的小鼠 → 阿茲海默症模型
- 過表現 synuclein 的小鼠 → 帕金森病模型
- 含腫瘤抑制基因或癌基因突變的小鼠 → 癌症模型
人體藥理學研究#
非侵入性技術(功能性磁振造影、超音波心動圖等)擴大了人體研究的可能性。人體實驗的科學原則與動物實驗相同,但倫理與安全問題至為重要,所有人體研究方案均需獨立倫理委員會審查。
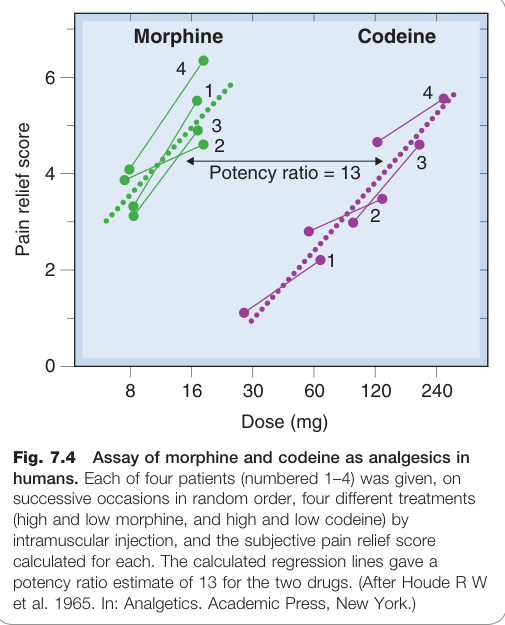
Figure 7.4:以交叉設計在人類受試者中比較嗎啡與可待因鎮痛效力的生物檢定
臨床試驗#
基本概念#
**臨床試驗(clinical trial)**是一種前瞻性研究,用以客觀比較兩種以上治療方案的效果。它是衡量治療效力的特殊生物檢定形式。
- 試驗治療(A):新藥、新手術、新療法等
- 對照治療(B):現有標準治療、安慰劑或不治療
臨床試驗通常只比較兩種特定給藥方案的效果,而非測量劑量-效應曲線或效力比值。核心問題是:A 是否比 B 更有效?
避免偏誤的設計要素#
隨機化(Randomisation)#
- 最簡單的方式:用隨機數字表將受試者分配到 A 或 B 組
- 分層隨機化(stratified randomisation):先按年齡、性別、病情嚴重度等分層,再在各層內隨機分配,以避免兩組在重要特徵上失衡,並可分析各亞群的反應差異
雙盲(Double-blind)#
受試者與評估者均不知道使用哪種治療,以消除主觀偏誤。在飲食介入或手術中難以實施,藥物的藥理效應有時也會洩露分組信息。
設置對照組#
未設對照的療效報告(如「20 名病人中有 16 名在 2 週內好轉」)無法解讀,因為不知道未接受治療的病人結果如何。
樣本數與統計誤差#
| 誤差類型 | 定義 | 對應概念 |
|---|---|---|
| 第一型誤差(Type I error) | A 與 B 無差異,卻得出差異(偽陽性) | 顯著性水準 P < 0.05 |
| 第二型誤差(Type II error) | A 與 B 有差異,卻未偵測到(偽陰性) | 檢定力(power)= 0.8–0.9 |
決定所需樣本數的兩大因素:
- 對誤差的容忍程度:顯著性水準越嚴格、檢定力越高,需要越多受試者
- 臨床上有意義的差異大小:預期差異越小,需要越多受試者偵測
臨床結果指標#
結果測量的選擇需在試驗開始前確定,常見類型包括:
- 生理指標:血壓、肺功能、存活曲線
- 主觀評估:疼痛緩解、情緒量表
- 長期結果:存活率、無疾病復發率
- 生活品質:各種健康相關生活品質量表
- 品質調整生命年(quality-adjusted life years, QALYs):將存活時間與生活品質合併為單一指標
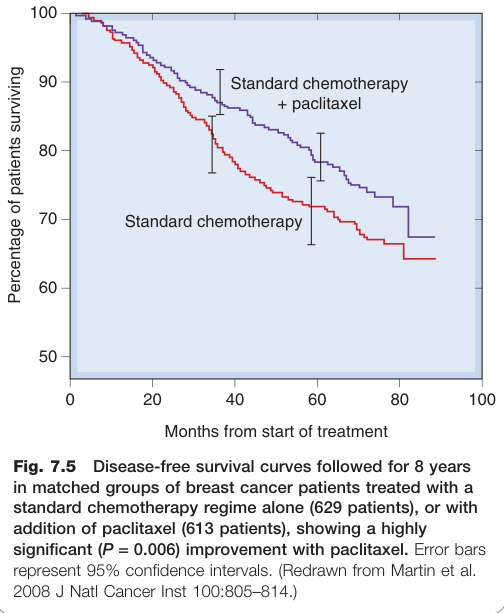
Figure 7.5:乳癌病患追蹤 8 年的無疾病存活曲線——標準化療與加用 paclitaxel 組的比較
頻率論與貝氏方法#
頻率論(frequentist):建立虛無假說(A 與 B 無差異),計算在虛無假說成立的前提下,觀察到現有數據的概率 P。若 P < 0.05 則拒絕虛無假說。
貝氏方法(Bayesian approach):將既有臨床經驗或先前試驗結果形式化為先驗概率(prior probability),再以新試驗數據更新為後驗概率(posterior probability)。此法爭議較多,但在已有相關證據時合理,且可縮小所需樣本。
安慰劑效應#
**安慰劑(placebo)**是不含有效成分的假藥(或假手術)。傳統上認為安慰劑效應強大,約能使三分之一的病人受益,但系統性文獻回顧(Hróbjartsson & Gøtzsche, 2001)發現:
- 安慰劑效應普遍而言並不顯著
- 唯一有小但顯著效果的領域是止痛
- 許多症狀的改善可能源於自然病程緩解,而非安慰劑本身
使用安慰劑作為治療手段有倫理風險:可能延誤有效治療、侵蝕醫病信任、製造依賴。對側(nocebo)效應描述的是服用安慰劑後出現不良反應的現象。
統合分析(Meta-analysis)#
將多個設計嚴謹(隨機化)的獨立試驗數據合併分析,以提高統計檢定力與顯著性。
主要缺點:
- 發表偏誤(publication bias):陰性結果較少發表
- 重複計算:同一數據出現在多篇報告中
效益與風險的平衡#
治療指數(Therapeutic Index)#
$$\text{治療指數} = \frac{LD_{50}}{ED_{50}}$$
其中 LD₅₀ 為使 50% 動物致死的劑量,ED₅₀ 為使 50% 動物有效的劑量。
治療指數作為臨床安全性指標有嚴重缺陷:
- 基於動物毒性數據,未必反映人體的不良反應
- ED₅₀ 隨所選療效指標而異(如阿斯匹靈用於頭痛 vs. 抗風濕,ED₅₀ 差異極大)
- 未考量個體間的效力和毒性差異
- 不反映罕見特異質反應(idiosyncratic reactions)
沙利竇邁(thalidomide)即因動物試驗治療指數極高而被推廣,卻成為史上危害最大的藥物之一。
需要治療人數(Number Needed to Treat, NNT)#
由臨床試驗數據估計,達到某一定義效益(或出現某一不良反應)需治療的病人數:
$$\text{NNT} = \frac{1}{\text{受益比例差}}$$
NNT 同時考量了治療效益大小與基礎疾病的嚴重度,是比治療指數更實用的臨床決策工具。例如:
- 某危及生命疾病(基礎死亡率 50%),藥物 A 使死亡率降至 25%,NNT = 4
- 某良性疾病(基礎死亡率 5%),藥物 B 使死亡率降至 2.5%,NNT = 40
雖然兩者均使死亡率減半,但藥物 A 每救一命只需暴露 4 人於副作用風險,藥物 B 則需暴露 40 人,因此藥物 A 的臨床價值顯然更高。