為何要研究抽樣與估計#
每日我們觀察到的 S&P 500、Nikkei 等指數本質上只是抽樣(samples)——它們並不涵蓋全部美國或日本股票,卻被視為母體行為的有效指標。
對分析師而言,從樣本計算出來的任何統計量,都只是底層**母體參數(population parameter)**的估計值。
本章介紹兩個核心主題:
- 抽樣:如何取得樣本
- 估計:如何由樣本回答「這個參數的值是多少?」
分析師必須對統計結果保持批判眼光,因為樣本品質決定推論品質。若樣本有偏,結論也會有偏。
抽樣方法#
**母體(population)**為某指定群體的所有成員;樣本為母體的一部分。參數描述母體;**統計量(statistic)**描述樣本。
抽樣的理由:
- 母體無法完全觀察
- 觀察全母體成本過高
簡單隨機抽樣#
簡單隨機抽樣(simple random sampling):母體中每個元素被選入子集的機率相等。常用做法:將母體編號後以隨機數對應抽取。
若母體成員無法完整編號,可採系統抽樣(systematic sampling)——每第 $k$ 個成員選一個,產生近似隨機的樣本。
樣本平均數與母體平均數的差異稱為抽樣誤差(sampling error)。這是用時間與金錢換來的代價。
分層隨機抽樣#
分層隨機抽樣(stratified random sampling):依一或多個分類標準將母體分為層(strata, cells),從每層中抽取與其相對大小成比例的簡單隨機樣本,再合併為一份分層隨機樣本。
優點:
- 確保母體中關注的子群體都在樣本中出現
- 比簡單隨機抽樣精確度更高(變異數更小)
債券指數化常採分層抽樣。把指數債券依存續期、現金流分布、產業、信用評等與贖回特性分層,再依每層市值比例抽取,比簡單隨機抽樣更能精確複製指數的風險特性。
時間序列 vs 橫斷面資料#
- 時間序列資料(time series data):在等距時點上的觀察序列
- 橫斷面資料(cross-sectional data):在單一時點對多個個體的觀察
跨越結構性斷點的樣本(如固定匯率與浮動匯率制度合併)等於從多個母體抽樣,會導致參數估計失真。選擇樣本期間時須留意制度與政策變化。
樣本平均數的分布#
抽樣分布#
樣本統計量本身就是隨機變數,因此也有自己的分布——稱為抽樣分布(sampling distribution)。
**樣本平均數的標準誤(standard error)**為其抽樣分布的標準差:
$$ \sigma_{\bar{X}} = \frac{\sigma}{\sqrt{n}} $$
(母體變異數已知時)
中央極限定理#
中央極限定理(central limit theorem, CLT):對於來自任意分布、平均數 $\mu$、變異數 $\sigma^2$ 的母體,當樣本大小 $n$ 足夠大時,樣本平均數 $\bar{X}$ 的抽樣分布近似於:
$$ \bar{X} \sim N\left(\mu, \frac{\sigma^2}{n}\right) $$
CLT 的重要性:
- 即使母體分布未知,樣本平均數仍可用常態分布近似
- 一般認為 $n \geq 30$ 即為「足夠大」
- 這是大樣本下構造信賴區間與檢定的理論基礎
點估計與區間估計#
估計量的良好性質#
**估計量(estimator)**是估計參數的公式;**估計值(estimate)**是由樣本計算出的特定數值。理想估計量應具備:
- 不偏(unbiasedness):期望值等於母體參數
- 有效(efficiency):在不偏估計量中具有最小變異數
- 一致(consistency):當樣本變大,估計準確的機率隨之增加
點估計與區間估計#
- 點估計(point estimate):以單一數值估計參數
- 區間估計(interval estimate):以一個範圍涵蓋參數,並附帶機率
信賴區間(confidence interval, CI):以給定機率 $1-\alpha$(稱信賴水準)保證涵蓋參數的區間。一般結構為:
$$ \text{點估計} \pm \text{可靠度因子} \times \text{標準誤} $$
母體平均數的信賴區間#
情境 A:母體常態、變異數 $\sigma^2$ 已知:
$$ \bar{X} \pm z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}} $$
其中 $z_{\alpha/2}$ 為標準常態分布的臨界值(如 $z_{0.025} = 1.96$ 對應 95% CI)。
情境 B:母體常態、變異數 $\sigma^2$ 未知:使用 Student t 分布
$$ \bar{X} \pm t_{\alpha/2, n-1} \cdot \frac{s}{\sqrt{n}} $$
情境 C:大樣本、母體分布未知:可由 CLT 使用 $z$ 或 $t$ 分布。$z$ 統計量的 CI 比 $t$ 統計量略窄、較不保守。
Student t 分布#
Student t 分布為一族對稱分布,由單一參數**自由度(degrees of freedom, df)**決定:
- 大小為 $n$ 的樣本,估計母體變異數時有 $n-1$ 個自由度
- t 分布尾部比標準常態厚(fatter tails)
- 自由度趨於無窮時,t 分布收斂至標準常態分布
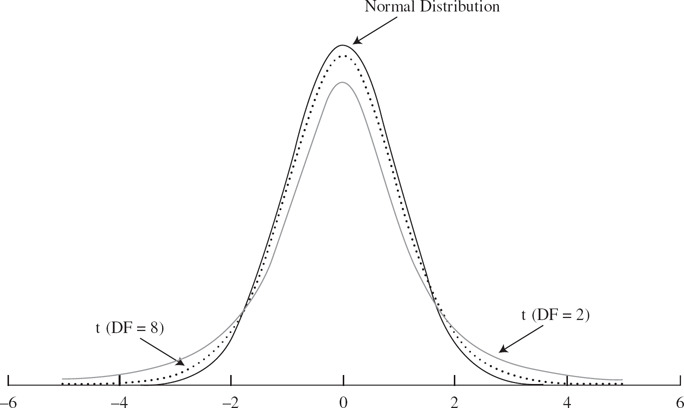
Figure 5.1: Student t 分布與標準常態分布的尾部比較
自由度反映「估計變異數時實際獨立的偏差數」:因為 $n$ 個離均差受到「總和為 0」的限制,僅有 $n-1$ 個可獨立變動。
樣本資料的常見陷阱#
財金資料常有多種偏誤,未察覺可能扭曲推論:
- 倖存者偏誤(survivorship bias):分析中排除已退市或因表現不佳被剔除的公司,使結果偏向倖存者
- 資料探勘偏誤(data-mining bias):在資料中反覆搜尋模式,可能找到「實則為偶然」的關係
- 預看偏誤(look-ahead bias):模型使用市場參與者當下尚未取得的資料
- 時段偏誤(time-period bias):所選時段使結果具有特定時段特性,或跨越結構轉折點
樣本大小的選擇還需考慮:
- 對精確度的需求
- 抽到多個母體的風險
- 各種樣本大小的成本
樣本「越大越好」並非總是正確。樣本若跨越結構斷點(例如低風險策略期間與高風險策略期間混合),會抽自不同母體,反而扭曲推論。
本章重點回顧#
- 抽樣方法包括簡單隨機抽樣與分層隨機抽樣;分層抽樣可確保子群體被代表且提高精確度
- 時間序列與橫斷面為分析師最常處理的兩種資料;混合不同制度的資料等同於從多個母體抽樣
- 中央極限定理:大樣本下,樣本平均數的抽樣分布近似常態,與母體分布無關
- 樣本平均數的標準誤為 $\sigma/\sqrt{n}$;估計量應具備不偏、有效、一致三項性質
- 信賴區間結構為「點估計 ± 可靠度因子 × 標準誤」;已知變異數用 $z$,未知變異數用 $t$
- t 分布由自由度決定,比標準常態厚尾,自由度大時收斂為標準常態
- 倖存者偏誤、資料探勘偏誤、預看偏誤、時段偏誤是常見的樣本資料陷阱