至此本書都聚焦在複雜性。但若系統需要快呢?效能考量該如何影響設計?
本章核心觀點:簡單依然是最重要的——不僅讓設計更好,通常也讓系統更快。
在開發過程中該擔心多少效能?#
兩個極端都不好:
- 過度優化每行:拖慢開發、製造不必要的複雜性,且許多「優化」根本沒效
- 完全忽略效能:不知不覺累積大量效率不良點 → 系統可能比應有速度慢 5–10 倍。「死於千刀」場景中很難回頭,因為沒有單一改動能帶來顯著差別
折衷做法:用基本的效能知識,挑「天生有效率」又乾淨簡單的設計方案。
關鍵是:意識到哪些操作根本上昂貴。
哪些操作昂貴#
| 操作 | 大致成本 |
|---|---|
| 資料中心內網路 round-trip | 10–50 µs(數萬條指令時間) |
| 廣域網路 round-trip | 10–100 ms |
| 磁碟 I/O | 5–10 ms(數百萬條指令) |
| Flash 儲存 | 10–100 µs |
| 新興非揮發性記憶體 | 約 1 µs(仍約 2000 條指令) |
| 動態記憶體配置(malloc / new) | 顯著(含 GC 開銷) |
| Cache miss | DRAM → 晶上 cache 數百條指令時間 |
怎麼學會「什麼貴」#
跑 micro-benchmark:小程式量測單一操作的成本。
RAMCloud 專案花了幾天建立 micro-benchmark 框架;之後加新測試只需 5–10 分鐘。長期累積下來能精準理解既有 library 與自家新類別的效能。
簡單與快通常並存#
知道什麼貴 → 在多數情況下選擇便宜的操作不會比慢的更複雜:
- 大量物件以 key 查詢:hash table vs. ordered map → hash table 通常 5–10 倍快,乾淨度相同 → 除非要排序屬性,永遠用 hash table
- C / C++ 結構陣列:陣列存指標再各自 alloc,遠比把結構直接內嵌進陣列、只 alloc 一塊大記憶體慢
當效率與複雜性衝突#
- 效率改善只多一點點複雜性,且藏起來不影響介面 → 值得(仍要當心:複雜性是逐步累積)
- 加大量實作複雜度,或讓介面更複雜 → 寧可先選簡單版,未來真的有問題再優化
- 已有明確證據顯示效能會在某情境關鍵 → 直接做快版
範例:RAMCloud 為了極低延遲,繞過 kernel 直接與 NIC 通訊——增加複雜度但因前期量測證明 kernel 網路太慢;其餘部分仍以簡單為原則。
一個常被忽略的現象#
簡單的程式碼通常比複雜的程式碼跑得更快。
- 消除特殊情況 → 不需檢查它們的程式碼 → 更快
- 深類別比淺類別更有效率:每次方法呼叫做更多事,少了層層跨越的開銷
量測再修改#
設計遵守上述原則後系統還是太慢?不要憑直覺改!
程式設計師對效能的直覺極不可靠——即便是經驗豐富的開發者。
憑直覺改 → 浪費時間在沒效果的事,還順便讓系統更複雜。
量測的兩個目的#
找出效能調校能帶來最大影響的位置
- 只測頂層效能不夠 → 知道慢,不知道為什麼慢
- 要往內部測,找少數「目前耗時 + 你有辦法改善」的精確位置
建立基準線
- 改完後重測 → 確認真有改善
- 沒明顯改善?回退——除非你的修改也順便讓系統變簡單
沒有顯著加速的複雜性,沒理由保留。
設計圍繞「關鍵路徑」#
假設你已仔細分析、找到一段拖慢整體系統的程式碼。
第一選項:基礎性改動(fundamental fix)#
例如:引入 cache、改用更快的演算法(balanced tree vs. list)、繞過 kernel。能找到這類改動就用本書既有設計手法實作即可。
第二選項:圍繞關鍵路徑重設計#
這應該是最後手段,但有時能帶來巨大差異。
步驟一:想像「理想程式碼」#
問自己:
「在最常見情況下,完成此任務必須執行的最少程式碼是什麼?」
- 拋開現有結構
- 想像把所有相關程式碼塞進單一方法
- 只考慮關鍵路徑所需的資料;可以為它選最方便的資料結構(甚至合併多變數)
- 假裝你能完全重設計系統 — 這就是「理想(the ideal)」
步驟二:找最接近理想又乾淨的設計#
理想往往與現有類別結構衝突,且未必實際;它只是個目標。
- 套用書中所有設計原則
- 限制:盡量保留理想程式碼不被打斷
- 為了乾淨抽象可加少量額外程式碼(例如呼叫一個通用 hash table 類別的方法)
- 經驗顯示:幾乎總能找到既乾淨又非常接近理想的設計
把特殊情況移出關鍵路徑#
慢程式碼往往是因為要處理多種情況,每種特殊情況都在關鍵路徑加一點點額外的條件判斷或方法呼叫。
重設計時:把特殊情況的檢查最小化。
理想做法:在開頭一個 if 用單一判斷涵蓋所有特殊情況:
- 通常情況 → 此一檢查通過 → 關鍵路徑繼續無干擾
- 失敗 → 跳到關鍵路徑外處理特殊情況;該分支以簡單為主,不為效能優化
範例:RAMCloud Buffer#
RAMCloud 用 Buffer 物件管理變長位元組陣列(如 RPC 的請求 / 回應訊息)。
設計核心:
- Buffer 看起來是線性陣列,但底層由多個不連續 chunk 組成
- 每個 chunk 是 internal(Buffer 自有記憶體)或 external(呼叫端擁有,Buffer 只持有參照)
- Buffer 內建一塊 internal allocation;不夠時再額外分配(解構時釋放)
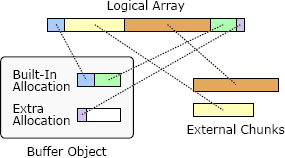
Figure 20.1: Buffer 物件用一系列記憶體 chunk 拼出看似線性的位元組陣列;internal chunk 由 Buffer 擁有、external chunk 由呼叫端擁有
Buffer 本身就是一個 fundamental fix#
- 大物件可作為 external chunk 不必 copy
- 例如組裝「短 header + 大物件內容」的回應訊息:兩個 chunk,無需 copy 大物件
後期優化的契機#
最初未對 Buffer 做特別優化。隨使用激增(每個 RPC 至少建 4 個 Buffer),加速 Buffer 對整體效能影響顯著。
找出關鍵路徑#
最常見操作:用 internal chunk 為少量資料分配空間(例如建立 RPC header)。
最簡情況:直接擴大 Buffer 中最後一個 chunk 的大小。前提:
- 最後一個 chunk 是 internal
- 該 allocation 還有足夠空間
理想程式碼:單一檢查確認可行 → 直接調整 chunk 大小。
原始實作的問題#
- 三個方法層疊(
Buffer::alloc→Buffer::allocateAppend→Buffer::Allocation::allocateAppend) - 多次重複檢查同一條件
- 不直接擴大最後 chunk,而是先分配新空間再判斷是否與最後 chunk 相鄰、再合併
- 關鍵路徑共檢查 6 個條件
- 三個方法簽章相同、抽象幾乎一樣 → 紅旗(pass-through)

Figure 20.2: 原始版本——以 internal chunk 在 Buffer 尾端配置新空間的程式碼
重構後#
- 整條路徑放進單一方法
- 用單一檢查涵蓋所有特殊情況
- 引入新 instance 變數
extraAppendBytes(追蹤最後 chunk 之後可用的剩餘空間,沒空間或最後不是 internal chunk 時為 0)
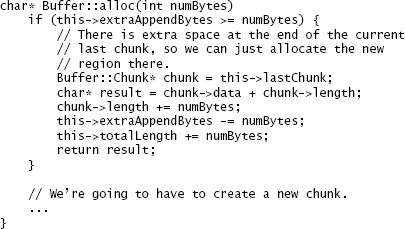
Figure 20.3: 重構後——在 Buffer 的 internal chunk 配置新空間的新程式碼,整條路徑單一方法、單一檢查
效果:
| 指標 | 原始 | 重構後 |
|---|---|---|
| append 1-byte 字串 | 8.8 ns | 4.75 ns |
| 建立 + append + 解構 Buffer | 24 ns | 12 ns |
| 程式碼行數 | 1886 | 1476(少 20%) |
totalLength也可選擇「需要時再從各 chunk 算出來」省去更新——但這對大 Buffer 太昂貴,且取總長也是常見操作。所以選擇在 alloc 增加一點點 overhead 換取總長隨時可用。
結語#
本章最重要的整體教訓:乾淨設計與高效能可以共存。
- Buffer 改寫:效能 ×2、設計更簡單、程式碼少 20%
- 複雜程式碼通常慢,因為它做了多餘 / 重複的工作
- 寫乾淨、簡單的程式碼 → 系統多半已經夠快,根本不必擔心效能
- 真正需要優化時 → 關鍵仍是簡單:找出效能關鍵路徑,把它做到能多簡單就多簡單