「大嗓門競爭不過清晰的聲音,即使後者只是低語。」——巴瑞・尼爾・考夫曼(Barry Neil Kaufman)
軟體測試本質上是一種蒐集資訊的活動,因此測試的諸多挑戰大多帶有強烈的「溝通」成分——建立與開發者的關係、向管理者解釋測試、與顧客和使用者溝通、不得不說「不」。
用薩提爾互動模型拆解溝通#
作者借用家族治療師薩提爾(Virginia Satir)的互動模型(Interaction Model)來改善他接收與給予測試資訊的方式。這個模型把任何溝通過程拆成四大部分:
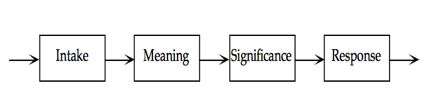
薩提爾互動模型:攝取 → 意義 → 重要性 → 回應
- 攝取(intake):一個人從外界擷取資訊。但攝取不會「自然發生」,它涉及一個選擇過程——我們對所見所聞行使了大量選擇。它是「攝取」,而非單純的「輸入」
- 意義(meaning):對攝取的感官資訊賦予意義。同樣的資訊可以有許多不同意義。例如顧客說「湯還可以」,可能指完全滿意、勉強接受、超乎期待,或「別再問湯了、讓我安靜吃飯」——資料在有人賦予意義之前並無意義
- 重要性(significance):資料能暗示意義,卻永遠無法暗示其重要性。這資訊對我重要嗎?有多重要?只有接收者能判定。若沒有依重要性篩選,我們感知的世界將是難以承受的資料洪流
- 回應(response):一個人擬定要採取的行動。測試人員與管理者是觀察者,但絕非被動的觀察者——他們依重要性對觀察排序、存起來以指引未來行動。測試人員尤其在意一種回應:「去找更多資料!」
後三個部分分別在第 12、13、14 章深入討論。本章聚焦於「攝取」。
人們選擇性地聆聽#
溝通出錯的一種方式發生在攝取階段——有些訊息因為人們不想聽而難以準確接收。管理者尤其擅長對發行與出貨日期選擇性聆聽:測試人員說「以目前找修 bug 的速度,九月一日出貨機會微乎其微」,飯碗岌岌可危的專案經理聽到的卻是「……我們九月一日能出貨」。
避免之道:
- 只用書面形式給予與接受日期
- 不要給「點日期」(精確到某 24 小時,如「九月一日」)
- 估計日期一律以「範圍」書寫(如「8 月 1 日至 21 日之間」)——但即便如此,較晚的日期常被人從攝取中丟掉、只記住較早那個
- 為強調範圍,用「機率對日期」的圖呈現,作者稱之為「機會有多大圖(what’s-the-chance graphs)」
資料來源會影響攝取#
人們對來自不同來源的資訊往往有不同反應,常依「發送者」預先判定訊息的重要性。
- 若別人不理會你的測試報告,試著透過一位「聲望足以讓接收者改變或卸下過濾器」的人轉達
- 作者身為顧問常扮演這種中介角色:不聽員工的管理者往往願意聽他——否則一開始就不會聘他
- 若發現換人轉達就被接受,把這當成一個測試結果,繼續自問:「我過去做了什麼讓人覺得我不可靠?未來該怎麼提升信任?」
先檢視自己,但最終你可能會發現問題出在對方身上——有些人就是不聽任何來自測試人員的話。若真如此,與其改變溝通風格,不如另謀他處。
時機很重要#
人在分心於他處時會錯過資訊。沒有對方的注意力,提供資訊就沒意義。
- 自認下次加薪押在「產品通過所有測試」上的開發者,不太聽得進「測試失敗」的訊息
- 在究責環境中,管理者誤以為不斷提高賭注(金錢、情緒)能改善測試。但賭注太高時,人們只會聽見指責、被恐懼震聾——極端情況下,管理者乾脆完全無視測試報告
- 資訊過載時,人們會關掉或調低攝取:bug 多到分級會議要開好幾小時、報告多到沒人讀得完、規格多到測試人員測之前讀不完
資訊過載「本身」就是資訊——它揭示了組織產生與處理資訊的方式(後設資訊)。
作者舉例:某客戶的分級會議綁住大量關鍵人員、效率低落,於是改用三條規則:
- 只用四個 bug 等級(level 0–3,從十個精簡為四個)
- 任一 bug 報告先花不超過一分鐘,無法分類就暫列 level 0 擱置(用廚房計時器強制執行)
- 若有餘裕重審暫列 level 0 者,每個不超過五分鐘,否則送出去補資料
等級判準如下:
- Level 0:正阻擋其他測試(一分鐘內無法分類者即視為阻擋,因為它會引發冗長爭論綁住眾人)
- Level 1:不解決就不能出貨
- Level 2:不解決會顯著降低產品價值
- Level 3:只有在出貨時存在大量類似問題才重要
套用這三條規則,分級團隊在不到兩小時內處理完 129 個積壓 bug,只有三個被退回補資料。冗長的分級爭論透露的,往往是團隊的心理狀態,而非分類 bug 本身的難度。
減少測試數量,反而可能傳達更多資訊#
這對信奉「測試所有東西謬誤」的人聽來矛盾,但減少測試產生的資料量,反而可能獲得更多資訊。
縮窄潛在測試集的關鍵問題是:「哪些測試對後續測試與開發影響最大?」
- 若系統在「只有一位使用者登入」時就回傳不出任何結果,測試人員還花數週做負載效能測試就太蠢了
- 反之,有些資訊看似關鍵卻其實無關:安裝失敗看似會卡住測試,但安裝腳本常獨立於軟體本身——只要設法把各部件放到該在的位置,就能一邊測軟體功能、一邊平行修安裝腳本
從框框外尋找攝取#
作者引述一則網路趣聞:女子打電話到客服說印表機有問題,客服問她「是不是在 Windows(窗戶)下運作」,她答「不是,我桌子在門邊,但你說得對,隔壁同事的桌子在窗戶下,他的印表機就正常」。
故事真假不論,卻含一絲真理:注意範圍之外的資料有時會影響程式行為——陽光照射使裝置升溫而異常,靜電、震動、雷達也可能。當測試機器行為不如預期,也許是別人用過它、改了它的狀態。
別把詮釋誤當攝取#
人心渴求意義,餵給人們一筆隨機資料,他們會飛快地從攝取跳到意義階段而不自覺。許多看似在陳述事實的話,其實是接收者的詮釋:
- 「bug 太多了」——對什麼而言太多?有時一個就太多,有時一百個都沒關係
- 「有很多 bug」——跟什麼比很多?
- 「只有四個 bug」——「只有四個」比預期好還是壞?
- 「有四個 bug」——「有」是一種詮釋;說話者只知道「找到」了幾個,不知道實際「有」幾個。應說「我們找到四個 bug」並說明在什麼條件下
- 「測試顯示專案必須延期」——這已跳到重要性步驟;測試本身不顯示這種事,是有人判定了它唯一的意義與重要性
當別人給你「詮釋」而你想要「資料」時,使用資料提問(The Data Question):「你看到、聽到(或聞到、嚐到、感覺到)了什麼,讓你得出那個詮釋?」不斷重複此問,直到抵達你想要的、無意義(meaning-free)的純資料,再反向重建意義。
小結#
攝取是一個主動的過程。試著意識到限制你攝取的因素、資訊的來源,以及資料如何被帶偏的意義所調味。你不是被灌入資料的受害者,而是至少有潛力掌控自己接收什麼。
常見錯誤#
以下是資訊攝取階段最常見的失誤。
- 不去想你要的是什麼資訊:別只接收送上門的東西,你有選擇
- 不主動尋找你要的資訊:99% 的資訊對測試任務無用,但只要懂得淘金,仍有大量可用
- 混淆攝取與意義:資料在有人判定意義前毫無意義,不同的人會給同樣的資料不同意義——蒐集資料後,靜下來思考至少三種可能的意義
- 禁止測試人員在某些地方找 bug:那些被禁的地方可能蘊藏豐富資料
- 沒提供足夠的測試設備與工具:你會要病理學家不用顯微鏡工作嗎?測試人員不正是軟體的病理學家?
- 落入「黃金大象症候群」(The Golden Elephant Syndrome):巴赫所稱的測試病態——昂貴的測試工具若設計拙劣、不可靠,或迫使測試人員用他們本不會選的方式測試,會帶來大麻煩。若工具便宜,我們會毫不猶豫丟掉;但因為它昂貴,買它的人不想顯得像個傻瓜,結果變成更大的傻瓜