本章收錄了在企業應用各層中廣泛使用的基礎模式。這些模式雖然不專屬於某一層,但在整體架構中扮演著不可或缺的角色。
Gateway#
意圖#
封裝對外部系統或資源的存取,提供一個簡潔的物件介面。
運作方式#
Gateway 本質上是非常簡單的包裝模式。面對外部資源(關聯式資料庫、CICS 交易、XML 資料結構等)那些因資源特性而複雜的 API 時,將所有特殊 API 呼叫包裝到一個介面看起來像普通物件的類別中。其他物件透過 Gateway 存取資源,由 Gateway 將簡單的方法呼叫翻譯成對應的專用 API。
Gateway 的關鍵用途之一是作為部署 Service Stub 的良好切入點。可以刻意調整 Gateway 的設計,使其更容易被替換為測試用的 stub。
設計原則:
- 保持簡單——專注於轉譯外部服務和提供 stubbing 的切入點,更複雜的邏輯應放在 Gateway 的客戶端
- 可以考慮使用程式碼產生來建立 Gateway(例如根據關聯式 metadata 或 XML schema 自動產生)
- 有時可以將 Gateway 分為 back end(最小化地覆蓋外部資源 API)和 front end(將尷尬的 API 轉為更方便使用的介面)兩部分
與其他模式的區別#
- Facade:通常由服務提供者撰寫,簡化複雜 API 供一般使用;Gateway 由客戶端針對自己的需求撰寫,可能完全複製被包裝的介面
- Adapter:改變一個實作以符合另一個已存在的介面;Gateway 通常沒有預先存在的介面
- Mediator:分離多個互相不知道對方的物件;Gateway 通常只涉及兩個物件,且被包裝的資源不知道 Gateway 的存在
使用時機#
- 當你面對一個笨拙的外部介面時,用 Gateway 將笨拙限制在一個地方,系統其他部分的程式碼會更容易閱讀
- Gateway 讓系統更容易測試——提供一個清楚的切入點來部署 Service Stub
- Gateway 讓替換資源變得容易——只需修改 Gateway 類別,變更不會擴散到系統其他部分
- 即使你不認為外部資源會變更,Gateway 帶來的簡潔性和可測試性仍然值得
- 當有多個子系統需要解耦時,也可以考慮 Mapper,但 Mapper 比 Gateway 複雜得多
Mapper#
意圖#
設置一個物件來負責兩個互相獨立的子系統之間的通訊,使雙方都不需要知道對方的存在。
運作方式#
Mapper 是兩個子系統之間的隔離層。它控制兩者之間通訊的細節,而任一子系統都不知道 Mapper 的存在。
Mapper 通常負責在兩個層之間搬移資料。難點在於如何觸發 Mapper,因為它不能被任一子系統直接呼叫。常見做法:
- 由第三個子系統驅動映射並呼叫 Mapper
- 讓 Mapper 作為其中一個子系統的 Observer([Gang of Four]),透過監聽事件來觸發
在企業應用中,最常見的 Mapper 用法就是 Data Mapper——在域物件和資料庫之間進行映射。
與 Mediator 的區別#
Mapper 與 Mediator([Gang of Four])類似,都用於分離不同元素。但 Mediator 的使用者知道 mediator 的存在(只是不知道彼此);而 Mapper 分離的物件甚至不知道 Mapper 的存在。
使用時機#
- 當你需要確保兩個子系統之間完全沒有依賴時
- 只在子系統之間的互動特別複雜且對主要功能相對次要時才使用 Mapper
- 大多數情況下,Gateway 更簡單也更常見——只在真正需要雙向獨立時才選擇 Mapper
Layer Supertype#
意圖#
作為某一層中所有物件的共同父類別,收納該層的通用功能。
運作方式#
Layer Supertype 是一個非常簡單的模式。在同一層中的所有物件常有重複的方法,將這些方法提取到一個共同的父類別中。例如,Domain Model 中所有領域物件都可以繼承一個 DomainObject 父類別,處理共通功能如 Identity Field 的儲存與存取。同樣地,所有 Data Mapper 也可以有一個共同的父類別。
如果一個層中有多種類型的物件,可以有多個 Layer Supertype。
使用時機#
- 當一個層中的所有物件有共通功能時就應使用
- 因為共通功能在企業應用中非常普遍,這個模式幾乎是自動採用的
Separated Interface#
意圖#
將介面定義在一個套件中,實作放在另一個套件中,以打破套件之間的依賴。
運作方式#
利用實作依賴於介面(而非反過來)的特性,將介面和實作分別放在不同套件中。其他套件可以依賴介面套件而不依賴實作套件。
介面可以放在:
- 客戶端套件中:如果只有一個客戶端或所有客戶端在同一個套件中
- 第三方套件中:如果有多個客戶端套件,由介面定義者負責宣告它能使用的服務
軟體在執行時仍需要某個實作。取得實作的方式:
- 使用另一個知道介面和實作的獨立套件,在應用程式啟動時實例化
- 使用 Plugin 在組態時期連結——不僅沒有依賴,還將實作類別的決定延遲到組態時期
語言層面的介面選擇:Java 和 C# 的
interface關鍵字是明顯選擇,但抽象類別也可以是好的選擇,因為它可以包含共通的(但可選的)實作行為。
使用時機#
- 當你需要打破兩個系統部分之間的依賴時,例如:
- 框架套件需要呼叫特定應用程式碼
- 一個層的程式碼需要呼叫不應看到的另一層(如 domain 呼叫 Data Mapper)
- 需要呼叫另一個開發團隊的功能但不想依賴其 API
- 不要過度使用——為每個類別都建立 separated interface 是過度設計。只在需要打破依賴或需要多個獨立實作時才使用
- 把介面和實作放在一起,等需要時再分離,是一個很簡單的重構
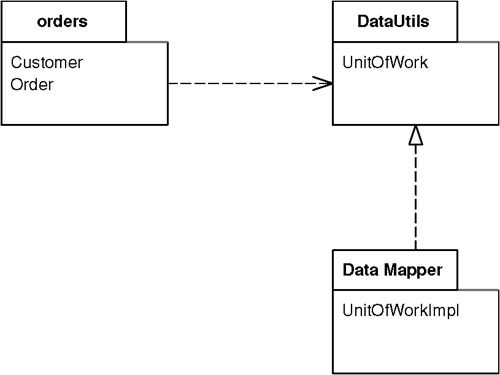
Figure 18.1: Separated Interface in a third package
Registry#
意圖#
提供一個眾所周知的全域物件,讓其他物件可以透過它找到共用的物件和服務。
運作方式#
Registry 本質上是一個全域物件,或至少看起來像全域物件。設計時需要區分介面和實作:
介面#
偏好使用靜態方法——容易在應用程式任何地方找到,且可以在內部封裝任何邏輯(包括委託給實例方法)。
資料作用域#
Registry 的資料可以有不同的作用域:
- Process-scoped:整個程序共用。通常使用 Singleton([Gang of Four])實作。不建議對可變資料使用,但對不可變資料(如常數列表)很適合
- Thread-scoped:每個執行緒有自己的 Registry。使用 Java 的 Thread Local 變數或類似機制。適合如資料庫連線等每個執行緒獨有的資源
- Session-scoped:每個 session 有自己的資料。可以利用 thread-scoped Registry 在請求開始時載入
儘管 Registry 的方法是靜態的,不代表資料應該放在靜態欄位中。靜態可變欄位在多執行緒環境下會造成問題。應使用 singleton 實例或 thread-local 來持有資料。
替換 Registry#
偏好使用明確的類別而非 map 來實作 Registry,因為明確的類別提供型別安全、明確的可用服務列表、封裝和重構能力。
如果需要在測試時替換 Registry 內容(如使用 Service Stub),可以使用子類別覆寫的方式:建立一個 RegistryStub 子類別,然後呼叫 initializeStub() 來替換 sole instance。
使用時機#
- Registry 本質上仍是全域資料——應該作為最後手段使用
- 替代方案包括透過參數傳遞共用資料,或在建構子中注入參考——但這些方式在呼叫層級很深時會變得笨拙
- 幾乎所有應用程式都會用到某種形式的 Registry,但應盡量透過一般的物件間參考來存取資料
- 記住:任何全域資料在被證明無害之前,都應被視為有罪的
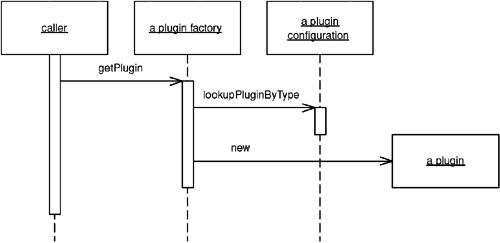
Figure 18.3: Multiple ID generators
Value Object#
意圖#
一個小型簡單的物件(如金額、日期範圍),其相等性不是基於身份而是基於欄位值。
運作方式#
Reference Object 使用身份(程式語言中的物件身份或資料庫中的主鍵)來判斷相等性;Value Object 則以欄位值來判斷——兩個日期物件只要年、月、日相同就相等。
Value Object 通常很小、容易建立,經常以值的方式傳遞而非參考。你不在乎系統中有多少個相同值的 Value Object 副本。
為了讓 Value Object 正確運作,務必使其不可變(immutable)——一旦建立就不能改變任何欄位。這是為了避免別名錯誤(aliasing bug):當兩個物件共享同一個 Value Object 實例,其中一方修改了值,另一方也會受影響。使 Value Object 不可變就能避免這個問題。
Value Object 不應直接持久化為完整記錄。應使用 Embedded Value 或 Serialized LOB 來存儲。由於 Value Object 通常很小,Embedded Value 是較好的選擇,因為它還允許 SQL 查詢。
.NET 實作#
C# 透過將物件宣告為 struct 而非 class,可以直接獲得值語義(value semantics),環境會自動以值的方式處理。
名稱衝突#
J2EE 社群曾將 “value object” 用來指稱 Data Transfer Object,造成了混淆。後來 J2EE 社群改用 “transfer object” 一詞。本書保持使用 Value Object 的原始含義。
使用時機#
- 當你以值而非身份來判斷相等性時
- 對任何小型、容易建立的物件都值得考慮
Money#
意圖#
代表一個貨幣值。
運作方式#
Money 類別包含兩個主要欄位:數值金額(amount) 和幣別(currency)。
數值類型#
- 絕對避免浮點數——浮點數會引入 Money 模式正要解決的捨入問題
- 可以選擇整數型別(如
long,以最小貨幣單位儲存)或固定小數型別(如BigDecimal) - 不同幣別有不同的小數位數——Java 的 Currency 類別可以提供這個資訊
算術運算#
- 加減法必須檢查幣別是否相同。對於不同幣別相加,最簡單的做法是拋出例外;更進階的做法是使用 Ward Cunningham 的 money bag 概念
- 乘法用於計算稅率等比例費用,需要指定捨入模式
- 比較運算也必須具備幣別意識
捨入與分配問題#
捨入問題在分配金額時特別棘手。例如:將 5 分錢按 70%/30% 分配到兩個帳戶——無論怎麼捨入都會多或少一分錢。解決方案:
- 忽略它——但這會讓會計人員緊張
- 最後一筆用減法——總是從已分配的總額中扣除,避免遺失分錢,但最後一筆可能累積較多
- 強制指定捨入模式——讓程式設計師明確處理,但多帳戶時會很複雜
- Allocator 函式(推薦)——接受比例列表(如
[7,3]),回傳一組 Money,保證不遺失任何分錢。多餘的分錢以偽隨機方式分散到各份中
區分乘法和分配的意圖很重要:乘法用於計算比例費用(如稅率),分配用於將一筆錢分到多個地方。前者適合乘法,後者適合 allocator。
儲存#
使用 Embedded Value 將 amount 和 currency 存為資料庫欄位。如果某個帳戶的所有條目都是同一幣別,可以在帳戶層級儲存幣別以避免冗餘。
使用時機#
- 在物件導向環境中處理幾乎所有數值計算時都應使用
- 主要理由是封裝捨入行為,減少捨入錯誤
- 另一個理由是讓多幣別運算更容易
- 常見的反對意見是效能問題,但作者幾乎沒遇過效能真的受影響的案例
Special Case#
意圖#
建立一個子類別,為特殊情況提供預設行為。
運作方式#
基本思路是建立子類別來處理 Special Case。例如,如果你有一個 Customer 物件且想避免 null 檢查,就建立一個 null customer 物件——覆寫 Customer 的所有方法,提供無害的預設行為。當系統中應該放 null 的地方,改放 null customer 實例即可。
- 通常不需要區分不同的 null customer 實例,可以使用 Flyweight([Gang of Four])
- 一個 null 可能有不同含義——「沒有客戶」和「有客戶但不知道是誰」是不同的。可以建立 Missing Customer 和 Unknown Customer 等不同的 Special Case
- Special Case 的方法可以回傳另一個 Special Case——例如 unknown customer 的最後帳單可以回傳 unknown bill
- IEEE 754 浮點數的正無窮大、負無窮大和 NaN 就是 Special Case 的好例子
Null Object 模式是 Special Case 的一個特例(special case of Special Case)。Special Case 的概念更廣泛,不僅限於處理 null。
使用時機#
- 當系統中有多處地方對某個特定類別實例或 null 進行相同的條件檢查和相同的預設行為時
- 可以透過給物件一個
isNull方法或使用 marker interface 來明確測試是否為 null
Plugin#
意圖#
在組態時期而非編譯時期連結類別,提供集中化的執行時期組態。
運作方式#
首先使用 Separated Interface 定義那些在不同執行環境中需要不同實作的行為。然後使用基本的工廠模式,但有幾個特殊要求:
- 連結指令必須宣告在單一的外部組態點(如文字檔或 properties 檔案),以便集中管理
- 連結到實作的過程必須在執行時期(而非編譯時期)發生,這樣重新組態不需要重新建置
Plugin factory 的運作方式:讀取組態檔(如 properties 檔案),找到所請求介面的實作類別名稱,透過反射(reflection) 建構實例並回傳。
即使語言不支援反射,仍值得建立一個集中的組態點——只是 factory 需要使用條件邏輯而非反射來對應實作。
使用時機#
- 當你有需要根據執行環境不同而改變實作的行為時,例如:測試環境使用記憶體計數器,正式環境使用 Oracle 序列
- 想要在不重新建置的情況下,透過修改組態檔就能切換不同的部署組態

Figure 18.2: Plugin implementation of a separated interface
Service Stub#
意圖#
在測試時移除對外部服務的依賴。
運作方式#
第一步是使用 Gateway 定義對外部服務的存取。Gateway 不應是一個類別而是一個 Separated Interface,這樣可以有一個實作呼叫真正的服務,另一個實作作為 Service Stub。透過 Plugin 載入所需的實作。
撰寫 Service Stub 的關鍵是保持簡單——複雜度會違背其初衷:
- 最簡單的 stub 可以是兩三行程式碼,使用固定的回傳值
- 更進階的 stub 可以維護一個測試資料清單,允許測試案例動態新增和重置資料
- stub 上不存在於正式 Gateway 介面中的設定方法(如新增豁免規則),需要回頭加到 Gateway 介面和正式實作中(正式實作中這些方法應拋出 assertion failure)
確保呼叫真正服務的 Gateway 實作中,那些僅供 Service Stub 使用的測試方法都會拋出 assertion failure,以防在正式環境中被誤用。
使用時機#
- 當對外部服務的依賴阻礙了開發和測試時
- 許多 XP 實踐者使用 “Mock Object” 一詞,但 Service Stub 這個名稱更早出現
Record Set#
意圖#
提供表格資料的記憶體內表示。
運作方式#
Record Set 通常由平台供應商提供(如 ADO.NET 的 DataSet、JDBC 2.0 的 RowSet),而非自行建置。它有兩個核心特性:
- 看起來完全像資料庫查詢結果——可以使用傳統的兩層方式,將查詢結果直接丟給 data-aware UI 工具
- 可以由程式產生和操作——不需要真的從資料庫查詢,也可以在中間加入業務邏輯處理
Record Set 可以中斷與資料來源的連結(disconnect),允許在網路上傳遞而不需要資料庫連線。序列化後還可以作為 Data Transfer Object 使用。中斷連結後更新時,可以使用 Optimistic Offline Lock 來偵測衝突。
顯式介面 vs. 隱式介面#
大多數 Record Set 使用隱式介面——以字串指定欄位名稱(如 aReservation["passenger"])。這在靜態型別語言中會失去型別資訊。顯式介面(如 ADO.NET 的 strongly typed DataSet)提供明確的屬性和型別,更安全也更易讀。
Record Set 的隱式介面雖然靈活,但建議在正式程式碼中使用 typed 版本。在非 ADO.NET 環境中,可以考慮使用程式碼產生來建立自己的顯式 Record Set。
使用時機#
- 當你的環境依賴 Record Set 作為通用資料操作方式時,特別是搭配 data-aware UI 工具
- 搭配 Table Module 來組織業務邏輯效果最佳:從資料庫取得 Record Set,傳給 Table Module 計算衍生資訊,再傳給 UI 顯示和編輯,最後送回 Table Module 驗證,再提交更新
- Record Set 之所以有價值,是因為關聯式資料庫和 SQL 的普及催生了大量 data-aware 工具。未來 XML 和 XPath 可能催生類似的階層式資料結構工具