Object-Relational Structural Patterns#
本章介紹十種處理物件與關聯式資料庫之間結構對映的模式。涵蓋身份識別、關聯對映、值物件處理、序列化與繼承對映等主題。
Identity Field#
將資料庫的 ID 欄位儲存在物件中,以維護記憶體物件與資料庫資料列之間的身份識別對應。
意圖#
Identity Field 在物件中保存資料庫主鍵,讓 Identity Map 可以運作,也讓記憶體物件與資料庫記錄之間的對應變得明確。
運作方式#
- 有意義的 key vs 無意義的 key:有意義的 key(如身份證號碼)看似自然,但可能因為業務規則變化而不再唯一。無意義的 key(如自動遞增數字)更穩定
- Simple key(簡單鍵) vs Compound key(複合鍵):簡單鍵是單一欄位,複合鍵由多個欄位組成。複合鍵需要特別的 key 類別,覆寫
equals()和hashCode() - key 的產生方式:
- 資料庫自動產生(auto-increment):簡單但需額外查詢取得生成的 ID
- GUID:全域唯一,不需要集中管理,但可讀性差且佔用空間較大
- Key Table:在資料庫中維護一張專用表格,記錄每張表的下一個可用 key。可一次取得一批 key 減少衝突

Figure 12.1: Mapping identity field to a database key
在使用繼承時,整個繼承階層應共用相同的 key 空間。例如使用 Concrete Table Inheritance 時,不同子類別的表格不應有重複的 key 值,因為你可能需要透過超類別的 ID 來查找物件。
何時使用#
- 當你需要在記憶體物件與資料庫記錄之間建立對映時(幾乎所有使用關聯式資料庫的情境)
- 唯一不需要的情境是使用 Dependent Mapping,因為相依物件不需要獨立的資料庫身份識別
Foreign Key Mapping#
將物件之間的關聯對映為資料庫表之間的外鍵參照。
意圖#
Foreign Key Mapping 使用外鍵(foreign key)將物件的參照轉換為資料庫表之間的連結。
運作方式#
- 對於單值參照(如 Album 有一個 Artist):在 Album 表中放置一個
artistID外鍵欄位。載入 Album 時,透過外鍵查找 Identity Map 取得 Artist 物件;若不存在則從資料庫載入 - 對於集合參照(如 Album 有多個 Track):在 Track 表中放置
albumID外鍵。載入 Album 時,查詢所有相符的 Track 記錄
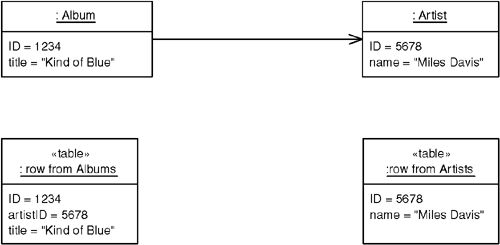
Figure 12.2: Foreign Key Mapping: mapping a collection
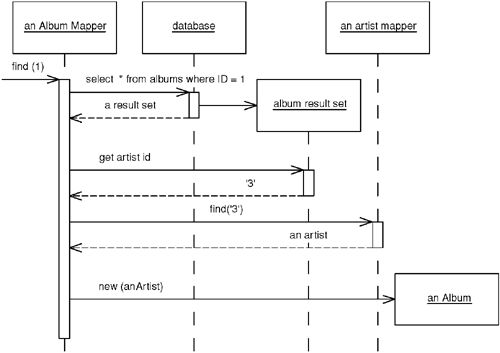
Figure 12.4: Sequence for loading a single-valued field
- 更新時需注意:若集合中的元素被移除,必須正確處理被移除物件的外鍵值(設為 null 或刪除記錄)
- 反向指標(back pointer)的使用可簡化更新操作
載入集合時,可以選擇立即載入或使用 Lazy Load。若集合在大多數情境下都會被使用,立即載入可以透過一次 SQL 查詢取得所有相關物件,比逐一載入更有效率。
何時使用#
- 適合:幾乎所有物件間的關聯都可使用,包括一對一和一對多關聯
- 不適合:多對多關聯——需改用 Association Table Mapping
- 多值欄位(集合)適合用 Foreign Key Mapping 處理,但若集合本身沒有獨立意義(如只是一組簡單值),可考慮 Dependent Mapping 或 Serialized LOB
Association Table Mapping#
將關聯儲存為一張中間表,內含兩張表的外鍵。
意圖#
Association Table Mapping 透過一張連結表(link table)將多對多關聯轉換為兩個一對多關聯,以便在關聯式資料庫中表示。
運作方式#
- 建立一張額外的表,僅包含兩個外鍵欄位,分別指向關聯兩端的表
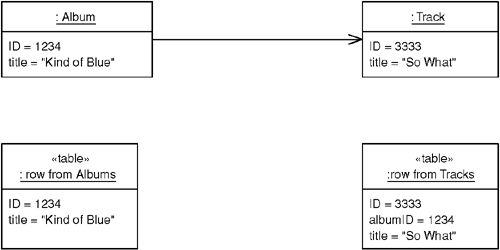
Figure 12.3: Classes and tables for a multivalued reference
- 載入時透過 JOIN 或多步查詢取得關聯物件
- 更新時需要同步更新連結表中的記錄——刪除不再存在的連結、新增新的連結
- 也可用於處理物件模型中的單值參照,但資料庫端由於歷史原因是多對多結構的情境

Figure 12.5: A team with multiple players

Figure 12.6: Database structure for team with players
典型範例是員工(Employee)與技能(Skill)的關聯:一個員工可以有多項技能,一項技能也可以屬於多個員工。在資料庫中透過
employee_skill連結表表示這個多對多關係。
何時使用#
- 適合:物件模型或資料庫中存在多對多關聯
- 也適用於物件模型是一對多,但資料庫因某種原因採用連結表的情境
- 若可以用 Foreign Key Mapping 處理就不需要使用此模式
Dependent Mapping#
由擁有者類別執行相依物件的資料庫對映。
意圖#
Dependent Mapping 讓某個物件(相依者)的資料庫操作完全由其擁有者負責,相依者本身沒有 mapper。
運作方式#
- 相依物件(dependent)沒有 Identity Field、不在 Identity Map 中、沒有獨立的 finder
- 擁有者的 mapper 負責相依物件的所有 CRUD 操作
- 前提條件:
- 相依物件有且只有一個擁有者
- 相依物件不被其他物件直接參照(除了擁有者)
- 更新策略通常是先刪除再重新插入所有相依物件,避免追蹤個別變更的複雜性
- 相依物件本身也可以擁有更深層的相依物件
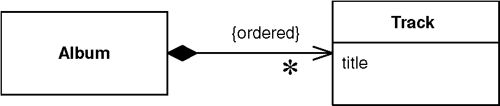
Figure 12.7: Album with tracks using Dependent Mapping
Dependent Mapping 與 Unit of Work 搭配使用時需特別小心。Unit of Work 通常會追蹤所有已載入的物件,但相依物件不應被獨立追蹤——它們的變更應隨擁有者一起處理。
何時使用#
- 適合:物件明確地只屬於一個擁有者,且不會被外部參照(如訂單中的訂單明細、專輯中的曲目)
- 不適合:若有任何情境下相依物件需要被獨立查詢或被多個物件參照
- 適合用於 Value Object,因為 Value Object 本來就不需要身份識別
Embedded Value#
將物件對映到另一個物件的資料庫表的欄位中。
意圖#
Embedded Value 將一個 Value Object 的欄位直接對映到擁有者物件的表中,不另建表。
運作方式#
- 當物件模型中有很小的 Value Object(如 Money、日期範圍、整數範圍)時,為它們建立獨立的表並不值得
- 擁有者的 mapper 在載入時建立 Value Object,在寫入時將 Value Object 的欄位解開存入擁有者的表欄位中
- 例如:一個 Employee 物件有一個
dateRange屬性(包含 start 和 end),資料庫中只有Employee表包含startDate和endDate兩個欄位
由於 Value Object 是不可變的且沒有身份識別,Embedded Value 非常適合它們。不需要擔心多個物件參照同一個嵌入值的問題,因為 Value Object 的語義就是相等性基於值而非身份。
何時使用#
- 適合:簡單的 Value Object,尤其是那些在 SQL 中可能想要進行查詢的值(如金額、日期範圍)
- 不適合:若嵌入的物件結構太複雜,會讓擁有者的表欄位數量過多
- 與 Serialized LOB 的差別在於 Embedded Value 保留了 SQL 查詢能力
Serialized LOB#
將物件圖序列化為單一大型物件(LOB),儲存在資料庫欄位中。
意圖#
Serialized LOB 將一整個物件圖(graph of objects)序列化後存入資料庫的單一欄位中。
運作方式#
- 兩種格式:
- BLOB(Binary Large Object):使用程式語言的二進位序列化(如 Java Serialization)。效率高但不可讀
- CLOB(Character Large Object):使用文字格式序列化(如 XML)。可讀且可進行簡單的文字搜尋
- 物件圖可以很自然地序列化,不需要為每個子物件建立表和對映
Serialized LOB 犧牲了 SQL 查詢能力。你無法使用 SQL 查詢 LOB 中物件的屬性。此外,版本控制也是問題——若物件結構變更,已存在的序列化資料可能無法正確還原。BLOB 在這方面比 CLOB 更脆弱。
何時使用#
- 適合:物件圖很少需要透過 SQL 查詢,且結構複雜,用多張表和對映來處理代價太高
- 不適合:需要透過 SQL 查詢內部資料的情境
- 通常用於輔助性資料(如組織結構的樹狀圖),而非需要經常查詢的核心業務資料
- 若選擇 CLOB,XML 是常見格式,可搭配 XML 資料庫的 XPath 查詢功能部分補回查詢能力
Single Table Inheritance#
以單一表格表示類別繼承階層,表中包含所有類別的欄位。
意圖#
Single Table Inheritance 將整個繼承階層中所有類別的所有欄位放在同一張資料庫表中。
運作方式#
- 表中包含繼承階層中所有類別的所有欄位
- 使用型別辨識欄位(type discriminator column) 來區分每筆記錄屬於哪個子類別
- 不屬於某個子類別的欄位在該子類別的記錄中為 null
- 載入時根據型別辨識欄位決定實例化哪個類別
這是三種繼承對映策略中最簡單的一種。只需一張表、不需 JOIN,重構繼承階層時只需修改一張表的結構。
何時使用#
- 優點:簡單、不需要 JOIN、重構時只動一張表、無需在多張表間搬移資料
- 缺點:大量 null 欄位浪費空間且降低可讀性、單一大表可能成為鎖定瓶頸、表的欄位數可能非常多
- 適合:繼承階層相對簡單、子類別之間差異不大時
- 通常作為預設選擇,除非空間浪費或表大小明顯是問題
Class Table Inheritance#
每個類別一張表格,以共用主鍵連結。
意圖#
Class Table Inheritance 為繼承階層中的每個類別建立一張表,每張表只包含該類別定義的欄位(不含繼承而來的)。
運作方式#
- 超類別表包含共用欄位,每個子類別表包含各自特有的欄位
- 所有表共用相同的主鍵值——子類別表的主鍵同時是指向超類別表的外鍵
- 載入時需要 JOIN 超類別表和相應的子類別表
- 查找時若不知道具體子類別,需要搜尋所有子類別表,或在超類別表中加入型別辨識欄位
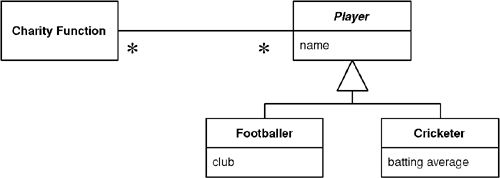
Figure 12.10: Link table with foreign key columns
何時使用#
- 優點:沒有浪費的欄位、每張表只包含相關資料、領域模型與資料庫結構的對應最直觀
- 缺點:載入需要多表 JOIN、頻繁的超類別表存取可能成為瓶頸、重構時需移動欄位到不同表
- 適合:需要清楚反映領域結構,且 JOIN 效能可接受的情境
Concrete Table Inheritance#
每個具體類別一張表格,每張表包含該類別的所有欄位(包括繼承而來的)。
意圖#
Concrete Table Inheritance 為每個具體(非抽象) 子類別建立一張獨立的表,每張表包含該類別的所有欄位,包括從超類別繼承而來的。
運作方式#
- 每張表都是自足的,包含物件的所有資訊
- 不需要 JOIN 即可載入完整物件
- 搜尋超類別時需要查詢所有子類別的表
- 主鍵必須在所有表之間唯一——不能使用各表獨立的自動遞增,需要共用的 key 產生機制
超類別的欄位變更會影響所有子類別的表。例如新增一個超類別欄位,需要修改每一張具體子類別的表。這使得超類別的修改成本很高。
何時使用#
- 優點:每張表自足、不需要 JOIN、只存取相關表時效能最佳
- 缺點:超類別欄位變更需修改所有表、透過超類別介面查找效率低、需要跨表的唯一 key
- 不適合:需要頻繁透過超類別介面操作的情境
- 適合:子類別差異大、且幾乎不需要透過超類別多型存取的情境
Inheritance Mappers#
組織資料庫 mapper 以處理繼承階層的結構。
意圖#
Inheritance Mappers 不是獨立的模式,而是一種組織 mapper 類別的架構策略,用來配合上述三種繼承對映策略。
運作方式#
- 建立與領域物件繼承階層平行的 mapper 繼承階層
- 結構組成:
- 具體 Mapper(Concrete Mapper):每個領域子類別對應一個,負責該類別特有的資料庫操作
- 抽象 Mapper(Abstract Mapper):對應領域超類別,包含所有子類別共用的載入和儲存行為
- Player Mapper:提供超類別介面的統一存取點。find 操作委派到各具體 Mapper 找到正確的記錄
- 各 mapper 只處理自己類別層級定義的欄位,再呼叫超類別 mapper 處理繼承的欄位
- insert 和 update 沿繼承鏈向上呼叫,最終組合出完整的資料庫操作
何時使用#
- 只要使用了 Single Table Inheritance、Class Table Inheritance 或 Concrete Table Inheritance,就適合使用此方式來組織 mapper
- 主要好處是避免重複程式碼——共用的載入/儲存邏輯放在抽象 Mapper 中