Object-Relational Behavioral Patterns#
本章介紹三種處理物件與關聯式資料庫之間行為互動的模式:Unit of Work、Identity Map 與 Lazy Load。它們解決了載入與追蹤物件變更、避免重複載入、以及延遲載入等核心問題。
Unit of Work#
維護一份受業務交易影響的物件清單,協調變更的寫入與並行問題的解決。
意圖#
Unit of Work 追蹤在業務交易過程中對物件所做的一切變更。當交易完成時,它負責計算出需要做的所有事情來改變資料庫,作為這個交易的結果。
運作方式#
- 當你從資料庫載入或修改物件時,必須讓 Unit of Work 知道。Unit of Work 維護三份清單:新增物件(new)、修改物件(dirty) 與 刪除物件(removed)
- 當你呼叫 commit 時,Unit of Work 決定要做什麼:開啟交易、執行並行性檢查、將變更寫入資料庫
- 三種註冊方式:
- Caller Registration(呼叫者註冊):由使用物件的程式碼負責在 Unit of Work 上進行註冊
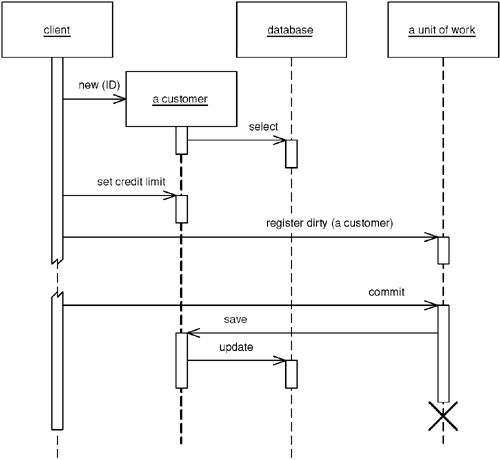
Figure 11.1: Having the caller register a changed object with Unit of Work
- Object Registration(物件註冊):將註冊方法放在物件本身,通常在 setter 中自動標記為 dirty
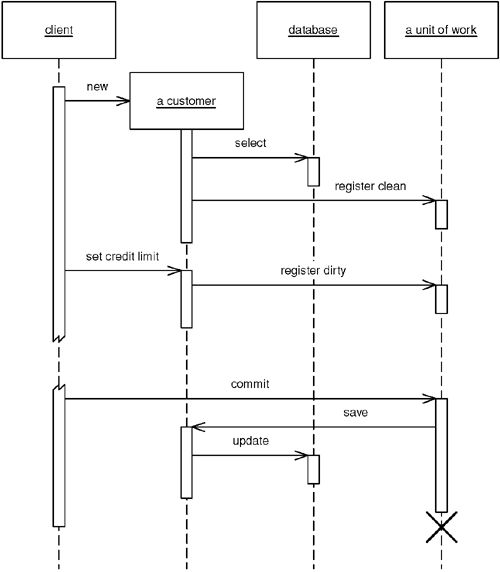
Figure 11.2: Getting the receiver object to register itself
- Unit of Work Controller(控制器方式):Unit of Work 控制所有的資料庫讀取,並在載入時自動註冊乾淨物件,再透過物件的複本比對判斷是否修改
- 常見做法是將 Identity Map 放在 Unit of Work 之內,因為兩者的生命週期都是以一次業務交易為範圍
- 使用 ThreadLocal 可以讓 Unit of Work 在同一執行緒內全域存取,避免在各處傳遞
commit 階段需要考慮多個問題:參照完整性順序(先寫入被參照的物件)、批次更新(合併多筆 SQL 提升效能)、死鎖最小化(固定表格的更新順序)。這些都使得集中管理變更成為比讓個別物件自行寫入更好的策略。
何時使用#
- 適合:任何需要追蹤物件變更的情況;若不使用 Unit of Work,你必須在每次修改時立刻更新資料庫,這會產生大量小型資料庫呼叫
- Unit of Work 是追蹤變更並產生正確資料庫行為的核心——一旦你遵循它的慣例,其他操作自然水到渠成
- 大多數情況下不需自行實作,現代 O/R Mapping 工具幾乎都內建此功能
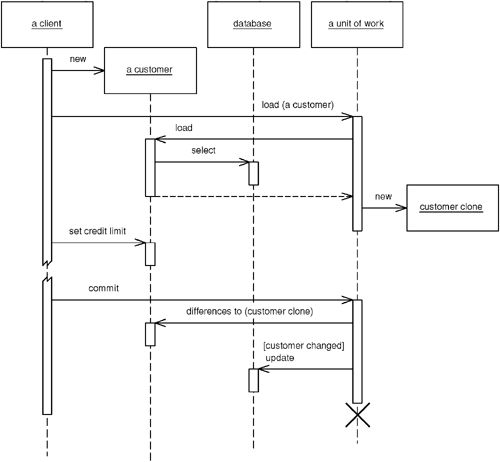
Figure 11.3: Using Unit of Work as the controller for database access
Identity Map#
確保每個物件只被載入一次,將其存放在 map 中,需要時透過 map 查找物件。
意圖#
Identity Map 將所有已載入的物件記錄在一個 map 中。查找物件時,先檢查 map 再查詢資料庫。
運作方式#
- 以資料庫主鍵(primary key)作為 key,物件作為 value 存放在 map 中
- 選擇方式:
- Explicit(顯式) vs Generic(通用):顯式 Identity Map 會對每個 find 方法提供明確的型別方法;通用 Identity Map 使用單一方法接受型別參數
- 每個類別一個 Map vs 整個 session 一個 Map:每個類別一個 Map 是最常見的選擇,需確保 key 在同一個類別的 Map 中唯一
- 放置位置:應放在與工作階段(session)相關的物件中,例如 Unit of Work 或 Registry 中的 session-scoped 區域
- Identity Map 同時扮演 快取 的角色,避免重複資料庫查詢
Identity Map 不僅是效能最佳化,更是正確性保證。若同一筆資料庫記錄被載入為兩個不同的物件,對其中一個的修改不會反映到另一個,導致不一致的更新結果。
何時使用#
- 適合:所有從資料庫讀取到記憶體的物件都應使用 Identity Map,以避免同一資料的多重載入
- 不需要:Value Object(如 Money 物件)不需要 Identity Map,因為沒有身份識別問題
- 不需要:使用 Dependent Mapping 的相依物件也不需要 Identity Map,因為它們由擁有者負責管理
- 若使用 Immutable(不可變) 物件,則不需要 Identity Map 來維護正確性,但仍可作為快取使用
Lazy Load#
一個物件不包含所有需要的資料,但知道如何取得它們。
意圖#
Lazy Load 在物件被存取時才載入所需的資料,而非在初始載入時就載入所有關聯資料。
運作方式#
四種實作方式:
- Lazy Initialization(延遲初始化):最簡單的方式。欄位預設為 null,在 getter 中檢查若為 null 則觸發資料庫查詢載入資料
- Virtual Proxy(虛擬代理):建立一個看起來像真實物件的代理,當任何欄位被存取時才觸發載入真實物件。問題在於身份識別——同一物件的代理和真實物件不是同一個實例
- Value Holder(值持有者):一個泛型的包裝物件,透過
getValue()方法取得實際值。簡單但缺點是類別需要知道它的存在,破壞了透明性 - Ghost(幽靈物件):載入時只有 ID,其餘欄位為空。首次存取任何欄位時才完整載入所有資料。是物件本身的一種狀態——部分載入
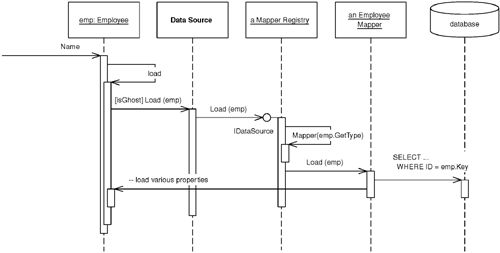
Figure 11.5: The load sequence for a ghost (Lazy Load)
使用 Lazy Load 時需特別注意 ripple loading(漣漪式載入) 問題。若有一個集合包含 100 個物件,每個物件都設為延遲載入,當遍歷集合時會觸發 100 次個別的資料庫查詢,導致嚴重的效能問題。此時應改用 eager loading(預先載入)。
何時使用#
- 適合:載入某個物件時會帶出大量關聯物件,但這些關聯物件不一定馬上需要
- 不適合:若物件的欄位幾乎每次都會被使用,延遲載入只會增加額外的資料庫往返
- 需要根據實際使用情境做出判斷,哪些關聯適合延遲載入、哪些適合預先載入
- Ghost 與 Lazy Initialization 是最常用的兩種方式
- Virtual Proxy 在缺乏身份識別能力的語言中(如 Java 的
==比較)可能造成微妙的錯誤