概述#
Data Source 層的角色是與應用程式所需的各種基礎設施溝通,其中最主要的就是與關聯式資料庫對話。儘管仍有 ISAM、VSAM 等舊式資料儲存格式存在,絕大多數現代系統都使用關聯式資料庫。SQL 是關聯式資料庫成功的關鍵因素之一——雖然 SQL 充滿各家供應商的擴充與怪癖,但其核心語法是通用且廣為人知的。
Architectural Patterns#
第一組模式是架構模式,它們決定了領域邏輯與資料庫之間的溝通方式。這個選擇影響深遠且難以重構,因此值得審慎考量。
Row Data Gateway#
將 SQL 存取從領域邏輯中分離出來,放到獨立的類別中是明智的做法。一種方式是以資料庫的表格結構為基礎,每個資料表對應一個類別,形成 Gateway。Row Data Gateway 為查詢回傳的每一列資料建立一個實例,自然地符合物件導向的思維方式。
Table Data Gateway#
若環境提供了 Record Set(一種模擬資料庫表格與列的泛用資料結構),則可以使用 Table Data Gateway——每個資料表只需一個類別,提供查詢方法並回傳 Record Set。Table Data Gateway 與 Table Module 搭配尤其合適,也可用於組織 stored procedures 的存取。

Figure 3.2: A Table Data Gateway has one instance per table
Active Record#
對於簡單的應用,當 Domain Model 的結構與資料庫結構高度對應時,可以讓每個領域物件自行負責載入與儲存,這就是 Active Record。另一種理解方式是:從 Row Data Gateway 出發,逐漸加入領域邏輯。
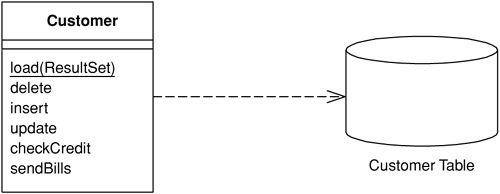
Figure 3.3: Active Record domain object interaction with database
Data Mapper#
當領域邏輯愈趨複雜,Active Record 的一對一映射就會開始崩解——關聯式資料庫不支援繼承、領域類別被拆分得更細。此時需要一個完全獨立的中介層,在領域物件與資料庫表格之間進行映射,這就是 Data Mapper。它是最複雜的架構,但好處是讓領域模型與資料庫完全隔離,各自獨立演化。
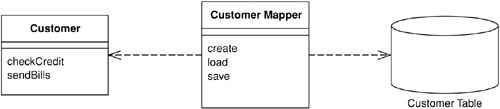
Figure 3.4: A Data Mapper insulates domain objects and database
若領域邏輯簡單且類別與表格高度對應,使用 Active Record;若需要更複雜的映射,則使用 Data Mapper。不建議在 Domain Model 中使用 Gateway 作為主要持久化機制。
關於 O/R Mapping 工具與 OO 資料庫#
作者提到物件與關聯之間存在根本的「impedance mismatch」。OO 資料庫可以消除映射的負擔,但多數專案因風險考量仍選擇關聯式資料庫。若使用 Domain Model,應認真考慮購買商用 O/R mapping 工具,因為手工建構 Data Mapper 是相當複雜的工程。
The Behavioral Problem#
O/R mapping 中最困難的部分其實不是結構映射,而是行為面的問題:如何讓物件正確地從資料庫載入並存回去。
Unit of Work#
當載入大量物件並修改後,需要追蹤哪些物件被修改、處理建立與修改的先後順序、確保資料庫狀態的一致性。Unit of Work 追蹤所有從資料庫讀取和修改的物件,並在提交時統一處理所有對資料庫的寫入行為。它是資料庫映射的「控制器」,將複雜的提交處理集中在一個地方。
Unit of Work 是行為問題的核心解決方案。當物件與資料庫的互動變得複雜時,它幾乎是不可或缺的模式。
Identity Map#
載入物件時必須避免同一筆資料庫列被載入為兩個不同的記憶體物件,否則更新時會產生混亂。Identity Map 記錄每一列已讀取的資料,每次讀取時先檢查是否已存在,確保每筆資料在記憶體中只有一個對應物件。它同時也兼具資料庫快取的效果,但其主要目的是維護身份一致性。
Lazy Load#
使用 Domain Model 時,讀取一個物件往往會連帶載入其關聯物件,可能拉出一大片物件圖。Lazy Load 使用佔位符(placeholder)替代真實物件參考,只有在實際存取該關聯時才從資料庫載入真實物件,藉此在適當的時間點只取回剛好需要的資料量。
Reading in Data#
Finder 方法#
讀取資料時,作者建議將讀取方法視為 finder——包裝 SQL SELECT 語句並提供方法化介面,例如 find(id) 或 findForCustomer(customer)。Finder 方法的放置位置取決於所使用的架構模式:
- 若資料庫互動類別是以表格為基礎(如 Table Data Gateway),finder 方法可與 insert/update 放在同一個類別
- 若是以列為基礎(如 Row Data Gateway),則需要獨立的 finder 物件
Finder 方法操作的是資料庫狀態而非物件狀態。若你在記憶體中新增了物件但尚未寫入資料庫,finder 查詢不會包含這些物件。因此通常建議在流程初期就執行查詢。
效能考量#
讀取資料時,效能是重要考量,以下是幾個經驗法則:
- 一次拉回多列資料:避免對同一張表格重複查詢以取得多列。寧可多取資料也不要少取
- 使用 JOIN 減少資料庫存取次數:透過 JOIN 一次從多張表格取回資料,但要注意資料庫通常最佳化在 3 到 4 個 JOIN 以內
- 善用 Gateway 或 Data Mapper:Gateway 可從多個 JOIN 的表格載入資料,Data Mapper 可以一次載入多個領域物件
- 資料庫端最佳化:如 clustering、索引、快取等,屬於 DBA 的專業範疇
- 務必進行效能分析:通用規則只能引導思考,每個應用程式都有獨特的情況
Structural Mapping Patterns#
結構映射模式處理記憶體物件與資料庫表格之間的結構對應。使用 Data Mapper 時幾乎需要全部用到這些模式;使用 Table Data Gateway 或 Active Record 時則只會用到部分。
Mapping Relationships(映射關聯)#
物件與關聯式資料庫處理連結的方式有兩個根本差異:
- 表示方式不同:物件使用記憶體參考,關聯式資料庫使用外鍵
- 多值性差異:物件可以輕鬆使用集合來處理多個參考,但正規化要求關聯式連結必須是單值的,導致物件與表格的結構可能相反
處理方式如下:
- 使用 Identity Field 在物件中保存關聯式身份識別
- 使用 Identity Map 作為關聯式鍵到物件的查找表
- 使用 Foreign Key Mapping 處理單值欄位與集合欄位的映射
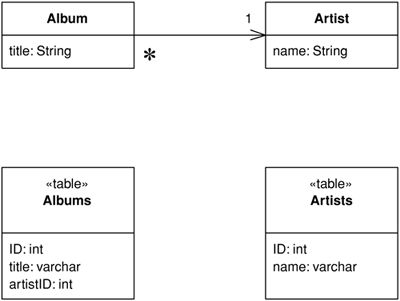
Figure 3.5: Foreign Key Mapping for single-valued field
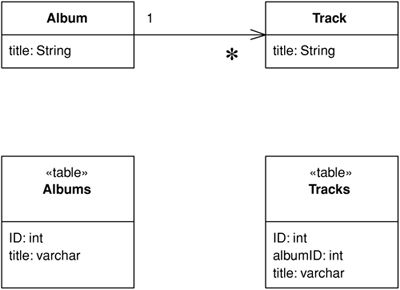
Figure 3.6: Foreign Key Mapping for collection field
- 若集合物件不在擁有者範圍外使用,可用 Dependent Mapping 簡化映射
- 多對多關聯需使用 Association Table Mapping,建立額外的關聯表格
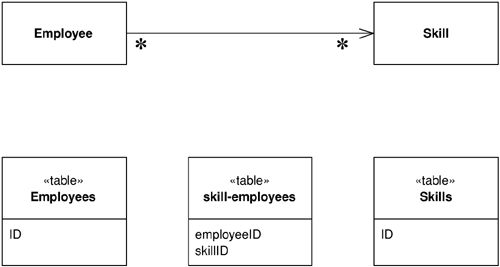
Figure 3.7: Association Table Mapping for many-to-many
在集合中依賴順序性是常見的陷阱。關聯式資料庫中難以維護任意排序的集合。考慮使用無序集合(unordered set),或在查詢時指定排序欄位。
處理 Value Objects#
並非所有物件參考都需要透過外鍵持久化。小型的 Value Object(如日期範圍、金額)不應獨立存為一張表格,而是使用 Embedded Value 將其欄位直接嵌入擁有者的表格中。由於 Value Object 具有值語意,不需要 Identity Map,讀寫都很簡單。
Serialized LOB#
可以將一整群物件序列化為單一欄位,存為 Serialized LOB(Binary LOB 或 Character LOB)。這對於階層式結構(如組織圖、BOM)特別有用,可以大幅減少資料庫往返次數。缺點是 SQL 無法對其內部結構進行查詢。適合用於應用程式中相對獨立的物件群組。
Inheritance(繼承映射)#
關聯式資料庫不原生支援繼承,因此需要特別的映射策略。有三種選擇:
- Single Table Inheritance:將整個繼承階層存入一張表格。簡單且易於修改,但會產生空欄位(wasted space)。表格過大時可能成為效能瓶頸與鎖定(lock escalation)的來源
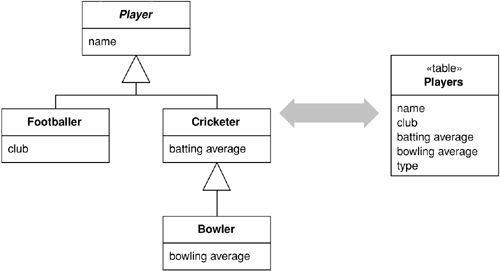
Figure 3.8: Single Table Inheritance
- Concrete Table Inheritance:每個具體類別各自一張表格。避免了 JOIN,但修改父類別時需要同步修改所有表格,且缺少父類別表格會使鍵管理與參考完整性變得困難
- Class Table Inheritance:繼承階層中每個類別各一張表格。類別與表格的對應最直接,但載入一個物件需要多個 JOIN
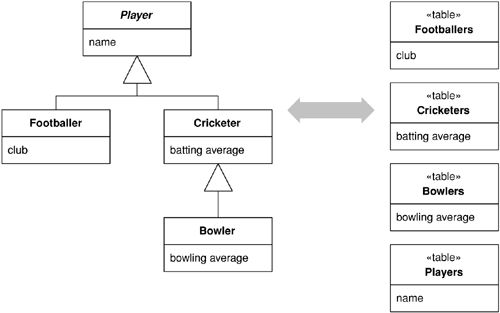
Figure 3.10: Class Table Inheritance
作者首選 Single Table Inheritance,因為它易於實作且對重構有很好的韌性。三種策略並非互斥,可以在同一個繼承階層中混合使用,但混合會增加複雜度。
Building the Mapping#
建構映射時,有三種常見情境:
- 自行設計 schema:最簡單的情況。若使用 Transaction Script 或 Table Module,可用傳統資料庫設計技術,搭配 Row Data Gateway 或 Table Data Gateway
- 既有 schema 不可變更:需根據既有結構建構映射。簡單領域邏輯可用 Row Data Gateway 或 Table Data Gateway;複雜領域邏輯則需要 Domain Model 搭配 Data Mapper
- 既有 schema 可協商:介於前兩者之間
使用 Domain Model 時,應先設計領域模型再考慮資料庫,而非反過來。但不要花六個月建構無資料庫的模型——應在短迭代中逐步整合,每個迭代不超過六週,以便及早發現效能問題。
Double Mapping#
當同種資料需要從多個來源取得(如多個資料庫、XML 訊息、CICS 交易)時,可考慮兩階段映射:先從記憶體 schema 映射到邏輯資料存放 schema,再從邏輯 schema 映射到實體資料存放 schema。這在多個來源結構相似但有細微差異時特別有用。
Using Metadata#
手寫的映射程式碼往往簡單但重複。透過繼承和委派可以消除部分重複,但更進階的方式是使用 Metadata Mapping——將映射資訊濃縮到一個 metadata 檔案中,描述資料庫欄位與物件欄位的對應關係。有了 metadata,就可以透過程式碼產生或反射式程式設計來避免重複的映射程式碼。
一行 metadata 就能表達大量資訊,例如:
<field name = "customer" targetClass = "Customer", dbColumn = "custID",
targetTable = "customers"
lowerBound = "1" upperBound = "1" setter = "loadCustomer"/>從這段描述可以自動產生讀寫程式碼、產生 ad hoc JOIN、執行多重性約束、計算寫入順序等。這也是商用 O/R mapping 工具傾向使用 metadata 的原因。
搭配 Metadata Mapping 還可以使用 Query Object 讓開發者用物件術語建構查詢,不需要了解 SQL 或資料庫 schema。進一步可以建構 Repository,幾乎完全隱藏資料庫的存在。Repository 與豐富的 Domain Model 搭配效果很好。
Database Connections#
大多數資料庫介面依賴連線物件作為應用程式與資料庫之間的橋梁。連線管理的關鍵要點:
連線池(Connection Pooling)#
建立連線的成本通常很高,因此值得使用連線池——從池中取得連線使用完畢後歸還,而非每次新建。多數現代平台已內建連線池功能。
連線的取得與傳遞#
- 明確傳遞:將連線作為參數傳遞。問題是連線會被一層層傳遞到不相關的方法中
- 使用 Registry:透過執行緒範圍的 Registry 取得連線,避免參數傳遞的問題
- 綁定到交易:將連線與交易生命週期綁定——開啟交易時取得連線,提交或回滾時關閉。Unit of Work 是管理交易與連線的自然搭配
連線的關閉#
連線是昂貴的資源,用完必須盡快關閉。明確關閉比依賴垃圾回收更可靠,但也容易忘記。將連線綁定到交易可以降低遺忘關閉的風險。
不要依賴垃圾回收來關閉連線。垃圾回收的時機不確定,可能導致連線長時間未被釋放。建議明確關閉或綁定到交易生命週期。
Disconnected Record Set#
若使用 disconnected Record Set,可以在取得資料後關閉連線,操作完資料後再開新連線寫回。但此時需要考慮資料在操作期間被其他使用者修改的並行控制問題。
Some Miscellaneous Points#
SELECT 語句的寫法#
- 避免使用
SELECT *,因為欄位新增或重排可能導致程式碼中斷 - 若使用欄位編號索引,要確保存取邏輯與 SQL 定義緊密對應
- 使用 Table Data Gateway 時,建議使用欄位名稱索引,並為每個映射結構建立 CRUD 測試案例
SQL 的預編譯#
- 盡量使用靜態 SQL(可預編譯),而非動態 SQL
- 避免用字串拼接組建 SQL 查詢
批次查詢#
許多環境支援將多個 SQL 查詢批次送出為一次資料庫呼叫,這在正式環境中值得採用。
連線與交易的處理#
書中範例使用簡化的 “DB” 物件取得連線,實際環境需根據平台特性處理。範例中未涉及交易,但正式環境中通常需要混入交易處理邏輯。