實證醫學與臨床藥學(EBM and clinical pharmacy)#
實證醫學(evidence-based medicine, EBM)近年已成為標準作法,在英國基層醫療中尤為普遍。以下定義可調整應用於臨床藥學。
EBM 的定義#
Sackett 等人(Sackett DL et al., 1996)將 EBM 定義為:
EBM 是在做出個別病人照護決策時,審慎、明確且明智地運用當前最佳證據。
作者進一步指出,EBM 的實踐需整合個別臨床專業判斷與來自系統性研究的最佳外部臨床證據。
McMaster 大學網站的第二個定義為:EBM 是一種醫療途徑,促進蒐集、詮釋並整合有效、重要且適用的病人陳述、臨床觀察與研究衍生證據;在病人情況與偏好的調節下,運用最佳可得證據以改善臨床判斷品質。
實證臨床藥學#
借用 Sackett 的定義:實證臨床藥學是在做出個別病人照護決策時,審慎、明確且明智地運用當前最佳證據。
- 這完全契合藥事照護(pharmaceutical care)的概念,挑戰臨床藥師不僅要跟上專業發展,也要將臨床發展應用於病人情況與偏好。
- Bandolier 的格言之一是 EBM 本質上是「工具而非規則」(tools not rules),藥師應用最佳證據時須謹記。
證據強度#
證據層級(hierarchy of evidence)有助於避免本質上有偏差的研究類型。多種分級系統可用於辨識證據層級,並作為臨床指引中建議分類的工具。
若僅有第 IV、V 級證據,仍不應忽略;但若有第 I 或 II 級證據可用,則不應依第 V 級證據做建議。
| 等級 | 療效證據的類型與強度 |
|---|---|
| I | 來自至少一篇多個設計良好隨機對照試驗(randomized controlled trial, RCT)系統性回顧的強證據 |
| II | 來自至少一篇適當規模、設計良好 RCT 的強證據 |
| III | 來自無隨機化的良好設計試驗(單組、世代、時間序列或配對病例對照研究)的證據 |
| IV | 來自一個以上中心或研究團隊的良好設計非實驗性研究的證據 |
| V | 受尊敬權威基於臨床證據、描述性研究或專家委員會報告的意見 |
統計顯著與臨床顯著(Statistical versus clinical significance)#
研究結果具統計顯著(statistically significant)不代表該發現重要。大型試驗或大型統合分析(meta-analysis)有能力找出組間極小的統計顯著差異,因此判讀顯著結果時,重要的是評估其臨床顯著(clinical significance)程度。
- 「臨床顯著」指人們在判斷介入效果幅度的意義時所做的價值判斷。
- 例如某昂貴藥物使收縮壓(systolic blood pressure, SBP)平均顯著降低 2mmHg,須考量其臨床價值:SBP 降 2mmHg 對病人有何重要健康益處?值得投資昂貴介入嗎?有無更便宜且降壓更多的藥物?
- 嚴謹的 RCT 應招募足夠受試者,以偵測研究前即判定為臨床顯著的組間差異。
勝算比與相對風險(Odds ratios and relative risk)#
什麼是勝算比#
雖然應治數(number needed to treat, NNT)是描述治療益處(或害處)非常有用且易於詮釋的指標,但多數論文未使用它。許多研究(尤其系統性回顧)與部分試驗以勝算比(odds ratio)或勝算比的變化報告結果;流行病學研究也常用勝算比描述暴露可能造成的害處。
計算勝算#
- 事件發生的勝算 = 事件數 ÷ 非事件數。例如某大城市有 24 名藥師待命,6 名被呼叫,被呼叫的勝算為 6 ÷ 18(未被呼叫者)= 0.33。
- 勝算比 = 治療/暴露組的勝算 ÷ 對照組的勝算。
- 流行病學研究多在找造成害處的因子——勝算比 > 1。臨床試驗多在找降低事件率的治療——勝算比 < 1,此時常引用勝算比的百分比下降,而非勝算比本身。例如 ISIS-4 試驗報告 captopril 使死亡勝算下降 7%,而非報告勝算比 0.93。
相對風險#
- 多數人難以自然詮釋以勝算比報告的事件率,理解風險與相對風險較易。
- 上例中被呼叫的風險(機率)= 6 ÷ 24(待命總數)= 0.25(25%)。相對風險(relative risk)又稱「風險比(risk ratio)」;若報告改善等正向結果,可稱「相對益處」。
風險與勝算#
- 當事件罕見時,風險與勝算非常接近。例如 ISIS-4 中對照組 29 022 人中有 2231 人在 35 天內死亡:風險 0.077,勝算 0.083,絕對差約千分之 6 或相對誤差約 7%。
- 此近似在事件罕見時成立。
為何用勝算比而非相對風險#
- 多數理由與勝算比優越的數學性質有關。勝算比恆可取 0 到無限大之值,相對風險則否。
- 相對風險可取的範圍取決於基線事件率,在事件率差異大的試驗統合分析中會造成問題。
- 勝算比具對稱性:若反轉結果(看好結果而非壞結果),關係呈倒數勝算比,相對風險則否。
- 病例對照研究(疾病盛行率未知)一律用勝算比,因表觀盛行率僅取決於抽樣比例(純屬人為)。這也是其在統合分析應用的歷史淵源——常規統計方法源自 1950 年代分層病例對照研究的分析方法。
- 校正干擾因子需用邏輯斯迴歸(以勝算運作並報告勝算比)。
與相對風險相同,要看勝算比是否統計顯著,可看其 95% 信賴區間是否未包含 1(相當於 < 1/20 機率,即 p < 0.05)。
公式:
勝算比 = 治療組勝算 ÷ 對照組勝算 (= 1 表示無差異)
風險比 = 治療組風險 ÷ 對照組風險 (= 1 表示無差異)二元與連續資料(Binary and continuous data)#
統計檢定大致分為比較二元(binary,又稱 dichotomous)結果資料與連續(continuous)結果資料兩類。
- 二元結果只能取兩種值,如死或活、有痛或無痛、吸菸或不吸菸。對二元資料的檢定(如相對風險)比較組間事件率,並使 NNT 的計算成為可能。
- 連續結果衍生自可取尺度上任意值的資料,如身高、血壓、時間或測驗分數。對連續資料的檢定(如 t 檢定)比較各組平均值的差異。
L’Abbé 圖(L’Abbé plots)#
L’Abbé 圖以 Kristen L’Abbé 及同事的論文命名,是理解系統性回顧極有價值的貢獻——以簡單圖形呈現試驗資訊,無須複雜統計。
- 散布圖上每個點代表回顧中的一篇試驗。將實驗介入達成結果的病人比例對對照組事件率作圖。
- 治療:實驗介入優於對照的試驗位於圖的左上方(y 軸與等值線之間);無差異則落在等值線上;對照較優則位於右下方(x 軸與等值線之間)。
- 預防:此型態相反。因預防減少壞事件(如心肌梗塞後用 aspirin 減少死亡),預期被治療傷害的病人比例小於對照組;故實驗介入較優時,試驗結果應落在 x 軸與等值線之間。
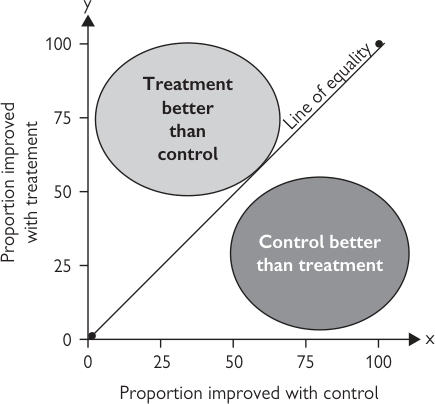
圖 7.1:L'Abbé 圖(L'Abbé plot)
平均差與標準化平均差(Mean difference and standardized mean difference)#
連續資料分析常顯示比較組平均值的差異。在統合分析中可:
- 若結果測量單位相同(如皆以公分量身高),直接比較兩組試驗的平均差(mean difference)。
- 若使用不同評估量表量測主觀狀況(如情緒、憂鬱、疼痛),則標準化結果並比較標準化平均差(standardized mean difference)。
在連續資料統合分析中,若實驗介入與對照效果相同,平均差或標準化平均差為零。因此:
- 若平均差信賴區間下限 > 0,實驗組平均顯著高於對照組。
- 若上限 < 0,實驗組平均顯著低於對照組。
- 若信賴區間包含 0,組間平均無顯著差異。
範例:某 Cochrane 回顧比較極低熱量飲食(very low calorie diets, VLCD)與其他介入對第 2 型糖尿病病人的減重效果。兩篇試驗統合分析顯示平均差為 −2.95kg(VLCD 組平均較對照組輕 2.95kg),但 95% 信賴區間包含 0(−6.42 至 0.53),表示減重差異無統計顯著。
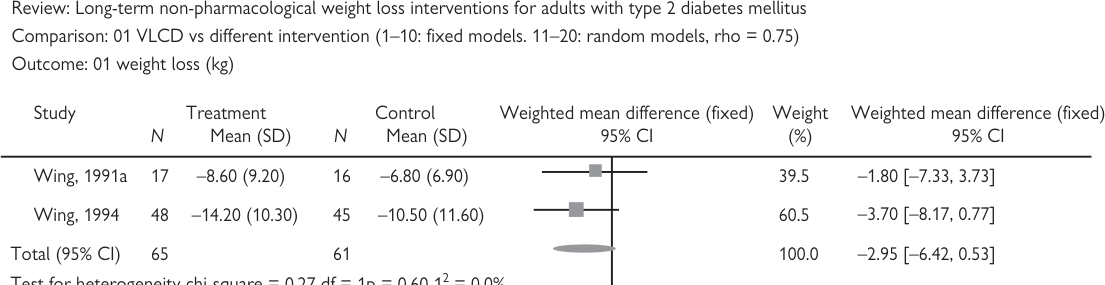
圖 7.2:統合分析森林圖(meta-analysis forest plot)
評估隨機研究的品質(Assessing the quality of randomized studies)#
隨機研究的評估工具廣泛可得,但都無法涵蓋所有重要議題。以下簡易方法(Jadad 等人,1996)涵蓋隨機化、盲性與病人退出三大主要議題,全部符合時最高品質分數為 5。
| 評估項目 | 分數 |
|---|---|
| 研究是否隨機化?是 | +1 |
| 隨機化是否適當?是(如亂數表) | +1 |
| 隨機化不適當(如交替病人、出生日期、病歷號) | −1 |
| 研究是否雙盲?是 | +1 |
| 盲性是否正確執行?是(如雙重虛擬 double dummy) | +1 |
| 盲性執行不當(如治療外觀不同) | −1 |
| 是否描述了退出與失訪?是 | +1 |
此外,更一般的評估工具會檢視:隨機化方法是否適當(如電腦產生)、盲性方法是否充分、試驗是否敏感(能否偵測組間差異,如使用安慰劑)、基線值是否足以衡量治療後變化、各組起始是否相似(相似病人、明確診斷標準、相似基線)、試驗規模是否足夠、結果是否清楚定義並適當量測(是否臨床有意義、為主要或代理結果)、結果資料是否清楚呈現(多重檢定時是否不當僅呈現陽性結果)。
系統性回顧的批判性評讀(Critical appraisal of systematic reviews)#
系統性回顧若執行良好且評估多篇隨機試驗,被視為最佳層級的證據,對回答臨床問題特別有用,但僅在過程遵循嚴謹科學原則時才可靠。作者應明確陳述回顧主題,並合理嘗試辨識所有相關研究。
以下十個問題(Oxman 等人,1994)有助評估。若論文未通過前兩個問題,便不值得繼續讀下去。
A. 回顧的結果是否有效?
- 回顧是否處理一個清楚聚焦的議題(族群、介入、結果)?
- 作者是否尋找適當類型的論文(RCT,或有納入其他研究類型的明確理由)?
值得繼續嗎?
- 你認為相關重要研究是否被納入(搜尋方法、參考清單、未發表與非英語文獻)?
- 作者是否充分評估納入研究的品質(通常以 RCT 評估工具形式)?
- 若結果被合併,這樣做是否合理?
B. 結果為何?
- 回顧的整體結果為何(是否有清楚的數值表達)?
- 結果有多精確(信賴區間為何)?
C. 結果能否協助我的在地情況?
- 結果能否應用於在地?
- 是否考量所有重要結果?
- 益處是否值得其害處與成本?
論文的批判性評讀(Critical assessment of papers)#
閱讀臨床試驗論文時,很容易快速讀摘要並略過主文。完整批判性評讀雖耗時,但若資訊將用於決定治療選項或支持處方集申請,則需更審慎。以下原則同樣可調整應用於其他類型臨床論文。
不必是統計學家或試驗設計專家才能評讀論文,多數評讀靠常識。即使只是記住這些原則,也能從閱讀中獲益更多。
- 題目:是否準確反映內容?理想上應陳述研究問題而非宣告結果(以免使讀者偏見)。過於晦澀的題目可能暗示作者不確定主題。
- 作者:應來自與主題相符的專業/機構。對製藥業員工撰寫的論文應謹慎但不全盤否定。作者過多可能代表工作潦草。是否列有統計學家可提供統計正確的保證。
- 期刊:不可因刊於主流期刊就假設是好論文;但對冷門期刊的論文更應謹慎。
- 前言:應提供相關背景並合理鋪陳至研究主題。冗贅或不相關的前言令人懷疑作者是否真懂主題。
- 方法:寫得好的方法應足以讓他人重現研究,包括:
- 研究類型(如 RCT、世代、病例研究)。
- 涉及人數,理想含檢力(powering)細節。
- 病人選擇與隨機化——應提供人口學細節,各組基線特性應大致相同(若不同應說明)。
- 納入/排除標準——是否適當。排除標準太多則研究可能與臨床情境不相關。
- 結果量測——因子應適當且盡量直接相關。對代理標記(surrogate marker)應謹慎,須確認其貼近整體目標結果。
- 適當的對照藥物應以標準劑量使用;新藥應對標準療法測試。若與安慰劑或過時/罕用藥比較,須問為什麼。
- RCT 理想應雙盲。若為開放標籤(open-label)或單盲(single-blind)可能有偏差。
- 對交叉試驗(crossover trial)謹慎——若疾病可自行隨時間改善(尤其自限性或季節性),交叉試驗不適當,且須有足夠的「廓清(washout)」期。
- 應提供統計檢定細節,且檢定須適合資料類型。對使用大量統計檢定的試驗存疑——為何需這麼多檢定?
- 結果:應回答原問題且易於理解。
- 圖表應相關且清楚。圖表過多暗示作者難以證明論點。注意座標軸標記是否被扭曲(如未從零開始)。
- 若引用平均值,也應引用變異數與/或中位數,以判斷平均是否為真正「平均」或被極端值扭曲。
- 結果可能統計顯著,但是否臨床顯著?以勝算比、相對風險或 NNT 呈現的結果通常較易應用於臨床。
- 討論:應由結果合邏輯地建構並回答原問題。若作者稱「需進一步研究」,須問為何——是否原設計不當?任何疑點或矛盾應妥善處理而非搪塞。
- 結論:應符合資料並給出明確最終答案。結論含糊則質疑研究是否有意義或僅為「湊論文」。
- 參考書目:應最新且相關。對冷門期刊參考過多應謹慎;應能透過所引原文追溯文中陳述。
- 致謝:留意作者清單外的專家(若對作者專業有疑慮可提供保證)。注意對結果有既得利益方(尤其製藥業)的資助或贊助;但不應因製藥業贊助就全盤否定。
指引(Guidelines)#
指引發展(guideline development)是引進新作法或停止某些現行作法的常見方式,雖耗時且昂貴,但有證據顯示若謹慎準備並同儕審查可有效。Shekelle 等人(1999)提出以下關鍵步驟:
- 辨識並精煉主題領域。
- 建立指引發展小組。
- 基於系統性回顧:評估關於臨床問題或病況的證據;將證據轉化為指引中的建議。
- 確保指引經外部審查。
Shaneyfelt 等人(1999)回顧約 270 份指引,列出約 25 項準備指引時應考量的要點,包括陳述指引目的、使用到期日,以及依證據強度分級建議。
應治數(Number needed to treat, NNT)#
NNT 是臨床顯著的量度,將觀點由「某治療有效嗎?」轉為「某治療效果多好?」。此概念不僅本身有用,也能直接比較治療。理想 NNT 為 1(如麻醉劑可達此標準),但實務上多 > 1。
- 定義:須治療多少人才能使一名病人受益。NNT 以特定臨床結果表達,並應附信賴區間。
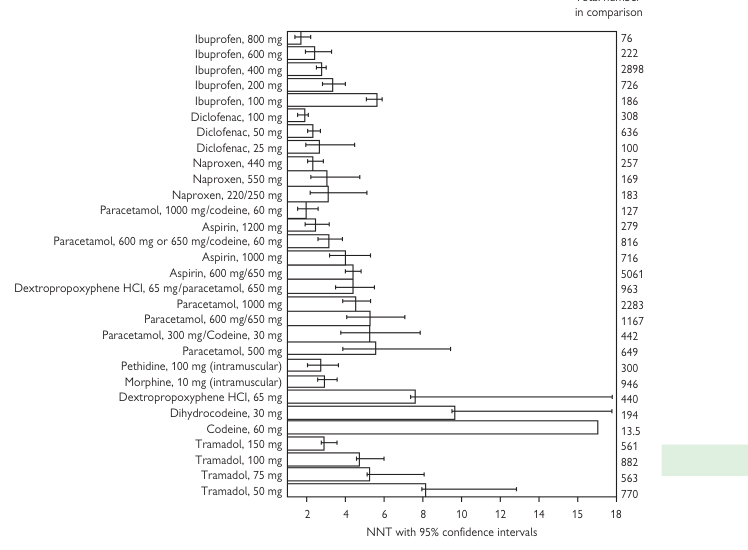
圖 7.3:達 ≥50% 止痛的 NNT 排序表
計算 NNT#
NNT 是絕對風險降低的倒數,但計算時無須理解此概念。
- 預防的 NNT = 1 ÷(對照介入受益病人比例 − 實驗介入受益病人比例)。
- 積極治療的 NNT = 1 ÷(實驗介入受益病人比例 − 對照介入受益病人比例)。
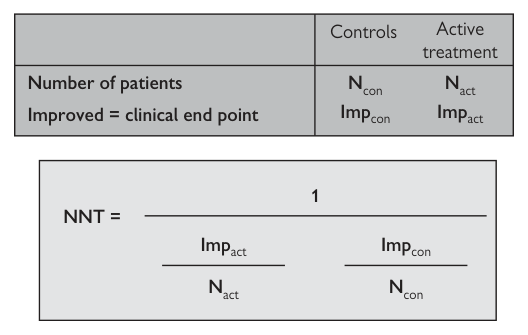
圖 7.4:益一需治數 NNT 計算
對照組若有任何反應,NNT 必 > 1。好的 NNT 取決於是治療(理想範圍 2–4)或預防(通常較大)。毒性與成本也有影響——例如便宜安全、可預防嚴重疾病但 NNT 為 100 的介入,仍可能可接受。
以 NNT 表達害處#
需治療害數(number needed to harm, NNH)也有助益,以類似公式但使用不良事件資料(而非期望效果)計算。
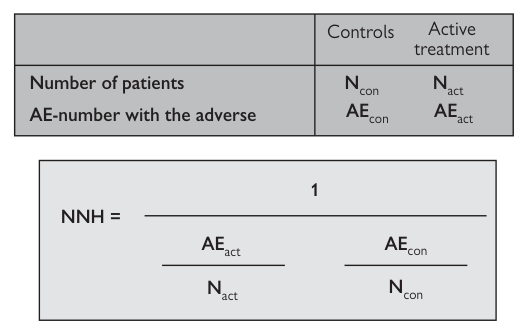
圖 7.5:害一需治數 NNH 計算
信賴區間(Confidence intervals)#
多數藥師熟悉以 p 值判斷結果是否(統計上)顯著,但 p 的使用日漸過時,新的顯著報告方法已出現。
- 最常見的是信賴區間(confidence interval),讓我們估計誤差範圍。例如量測 100 名成人血壓得一平均;再量另 100 人會得相似但不同的數字。信賴區間(以百分比表達)讓我們計算誤差範圍,告知平均值的可靠度。
- 通常設為 95%,故我們可有信心真實平均落在上下估計之間;換言之,結果落在計算界限外的機率僅 5%。
- 統計上源自點估計上下 1.96 個標準差的範圍;99% 信賴區間則用 2.58 個標準差。
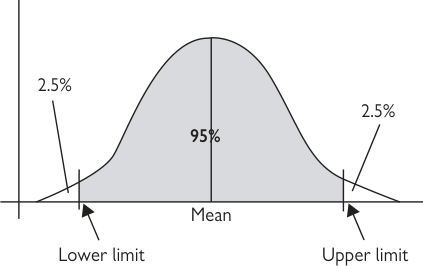
圖 7.6:95% 信賴區間示意
計算信賴區間#
公式見標準統計著作,網路上也有許多信賴區間計算器,僅需輸入計算出的點估計與樣本數即可在給定百分比下求出信賴區間。