對數字派而言,這應該是黃金時代——過去要花幾個月的工作,現在幾秒就能完成。但工具普及,也讓數字被誤用、操弄、誤讀的機會大增。本章把處理數字的工作拆成三步:蒐集、分析、呈現,並在每一步檢視可能的偏誤與防範方法。
從資料到資訊:三個階段#
我們其實活在「資料時代」而非「資訊時代」。資料(data)是原始數字,資訊(information)是處理過、能用於決策的訊號。我們面臨的不是資訊過載,而是資料過載。
資料蒐集 → 資料分析 → 資料呈現- 資料蒐集(data collection):可能是查詢資料庫、做實驗或調查
- 資料分析(data analysis):用統計學總結、找出資料間的關係
- 資料呈現(presentation):讓他人(也讓自己)能讀懂分析結果
別在每個階段的細節裡迷路。終極目標是用資訊做出更好決策——任何幫助達成這個目標的就是好的,任何讓你偏離的就是干擾。
第一階段:資料蒐集#
多少資料才夠?#
統計學的「大數法則(law of large numbers)」告訴我們:樣本越大,計算出的統計量越精確,因為個別錯誤會被平均掉。所以選擇通常是:
- 小而精:少量但仔細整理的資料
- 大而雜:大量但有雜訊與錯誤的資料
蒐集財務資料的常見抉擇#
- 上市 vs. 私人公司:上市公司有揭露義務,資料容易取得;私人公司通常難以接觸
- 會計 vs. 市場資料:上市公司既有財報,也有交易資料(價格變動、買賣價差、成交量)
- 本國 vs. 全球資料:很多研究者偏好本國資料(熟悉、易得),但全球化的決策需要全球資料
- 量化 vs. 質性資料:資料庫偏量化(容易儲存)。社群媒體興起後,質性資料的分析技術也在進步
蒐集偏誤#
資料看似客觀,但蒐集本身就是偏誤的入口。
選樣偏誤(Selection Bias)#
樣本必須真正隨機,但商業情境中極難做到:
- 顯性:研究者為了得到想要的結論,特意挑選樣本(如只選 S&P 500 公司來證明「企業普遍做出好投資」——這些公司之所以入選正是因為過去成功)
- 隱性:受限於資料庫只收錄某類公司(如只有上市公司資料),結論卻被推廣到所有企業
取樣時,也要看你排除掉了什麼,這能幫你發現潛藏的偏誤。
倖存者偏誤(Survivor Bias)#
紐約大學教授 Stephen Brown 研究避險基金時發現,許多研究都從「現存」的基金回溯計算報酬,自動忽略已倒閉的基金——這讓報酬被高估約 2–3%。失敗率越高的群體(如科技新創)越受倖存者偏誤影響。
雜訊與錯誤#
- 即使最仔細維護的資料庫也有輸入錯誤,做研究前要先過濾離譜值
- 缺漏資料的處理:直接刪除會減少樣本並引入偏誤;保留則需要近似估計(達莫達蘭以美國公司的租賃承諾資料推估其他市場公司的租賃情況,作為折衷)
第二階段:資料分析#
基本工具#
- 平均值(mean):簡單算術平均
- 標準差(standard deviation):捕捉資料圍繞平均值的離散程度
- 中位數(median):50% 分位數,適合不對稱分配
- 眾數(mode):出現最多次的值
- 偏度(skewness):捕捉樣本的對稱性
- 峰度(kurtosis):捕捉與平均差異極大的樣本出現頻率
視覺化工具#
- 頻率分配(frequency distribution):離散資料用,例如各信用評等的公司數
- 直方圖(histogram):連續資料用,例如本益比分組統計
- 散佈圖(scatter plot):兩個變數之間的關係(如本益比 vs. 預期成長率)
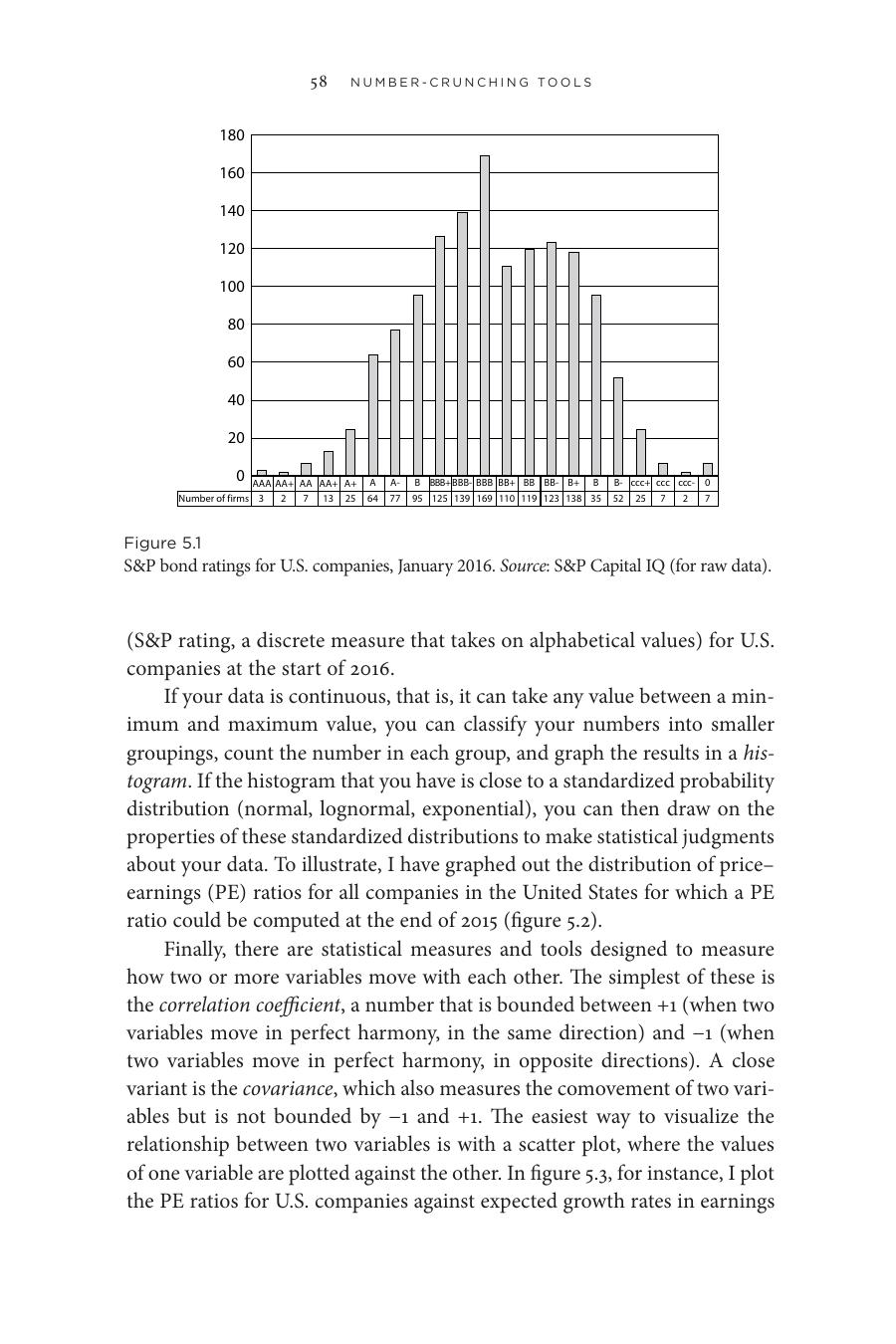
Figure 5.1: 美國公司 S&P 債券評等分布(2016 年 1 月)
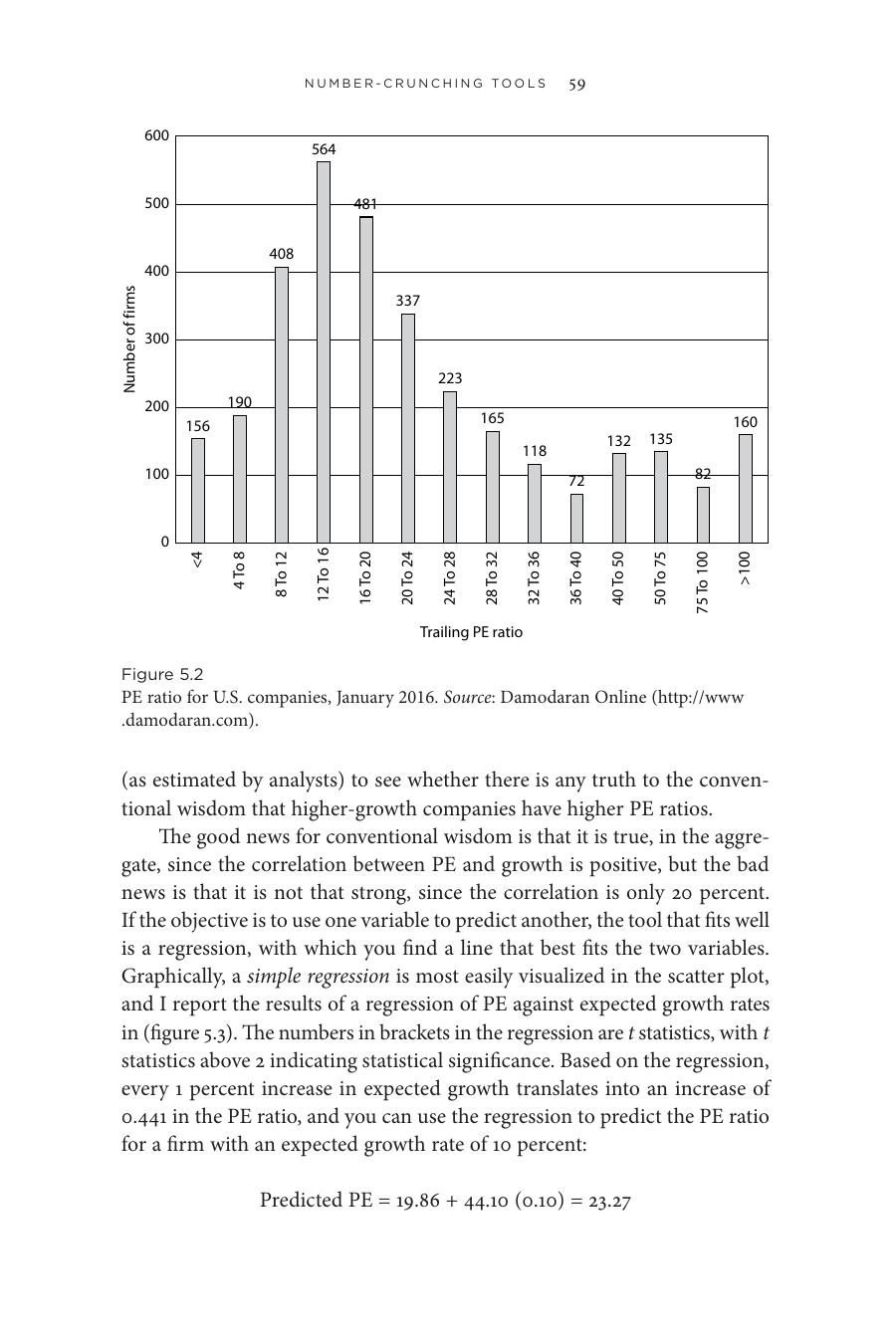
Figure 5.2: 美國公司本益比直方圖(2016 年 1 月)
關係衡量#
- 相關係數(correlation coefficient):範圍在 −1 到 +1 之間
- 共變異數(covariance):類似但不限制範圍
- 迴歸(regression):找出最能解釋兩變數關係的直線,並可推廣為多變量迴歸
達莫達蘭(Aswath Damodaran)以本益比對預期 EPS 成長率做迴歸,發現公式為 PE = 19.86 + 44.10 × 預期成長率,R² 僅 21%——意味預測能力有限,預測值的範圍很寬。
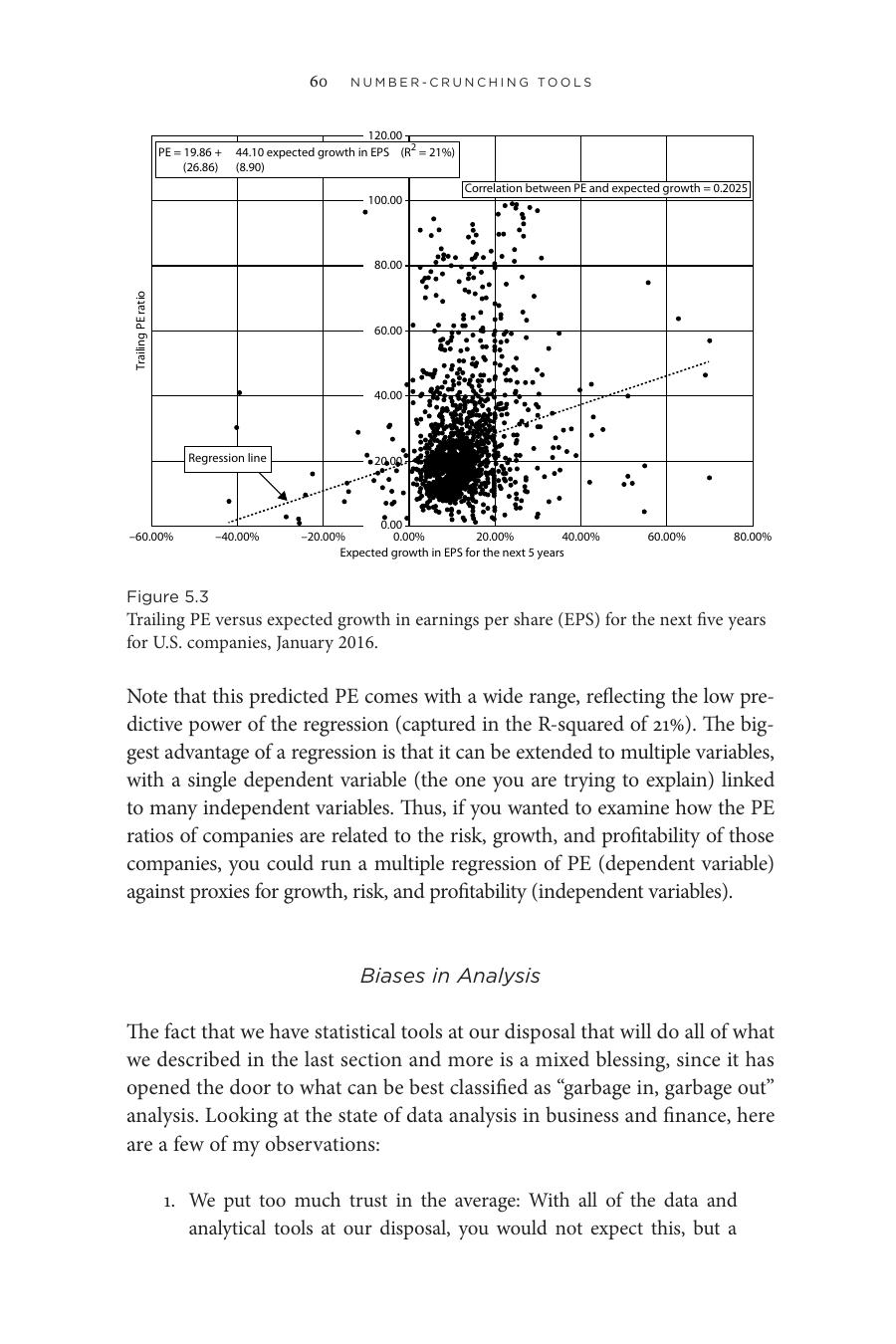
Figure 5.3: 落後本益比與未來五年預期 EPS 成長率的散佈圖
分析中的偏誤#
1. 過度信任平均值#
- 太多投資判斷只用「行業平均本益比」就斷定股票便宜或昂貴
- 對非對稱分配,平均值是糟糕的中央代表
- 1960 年代或許還能說工具受限,今天的資料環境根本沒藉口
2. 常態分配並非常態(Normality is not the norm)#
統計課最大的遺毒:大家只記得常態分配。它優雅、簡潔(只需平均值與標準差就能描述),但真實世界、特別是商業與金融資料,幾乎都不是常態分配。分析師仍硬套常態,於是不斷被「3 個標準差以外的事件」嚇到。
3. 離群值問題(The Outlier Problem)#
- 離群值會削弱結論,研究者本能地想剔除
- 但剔除離群值是危險的:不符合先入為主的離群值容易被刪,符合的卻被保留
- 商業與投資中,真正該注意的可能正是離群值——危機就藏在那裡
第三階段:資料呈現#
表格與圖表#
兩種表格:
- 參考表(reference table):大量資料供查詢
- 演示表(demonstration table):摘要不同子群的差異
三種常用圖表:
- 折線圖(line chart):時間趨勢與系列比較
- 柱狀/長條圖(column / bar chart):在少數類別間比較統計量
- 圓餅圖(pie chart):拆解整體為各組成
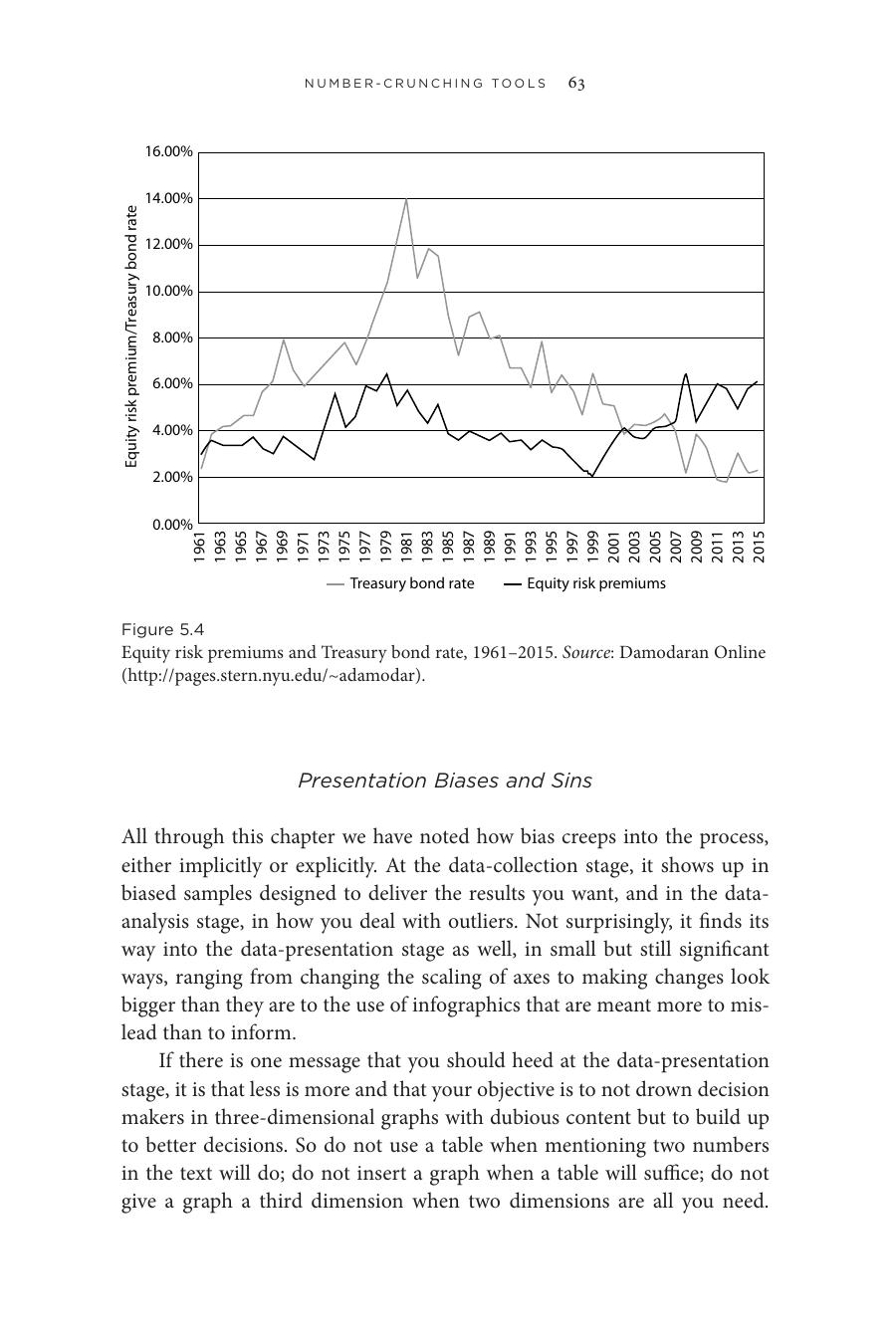
Figure 5.4: 股票風險溢酬與美國國庫券利率的時間序列(1961–2015)
達莫達蘭推崇資料視覺化大師塔夫特(Edward Tufte):突破試算表的限制,讓圖像本身會說故事。資訊圖表(infographic)已成為一門專業學科。
呈現偏誤與罪過#
呈現階段的常見偏誤:改變座標軸縮放讓變化看起來更大、用炫目卻誤導的資訊圖表。
呈現階段的金科玉律:少即是多。
- 用兩個數字能講清楚的,不要做表格
- 用表格能說清楚的,不要做圖
- 用 2D 能呈現的,不要硬塞 3D
達莫達蘭自承也會犯這些錯,但他鼓勵讀者抓他的錯。
案例研究#
案例 5.1:製藥業的 R&D 與獲利(2015)#
- 1991 年起的舊故事:藥廠靠專利保護、健保支出成長、保險公司分散議價,享有強大定價權。投資人按 R&D 支出與產品線豐富度評價藥廠
- 過去十年的轉變:
- 健保成本成長放緩
- 健康保險公司整併,談判力提升
- 政府透過 Medicaid、Medicare 對藥價施壓
- 連鎖藥房整併,加入定價談判
- 資料檢驗:1991–2014 年的毛利資料只「微弱地」支持「定價權減弱」的假設
- R&D 對營收的回報:用「營收成長率 ÷ R&D 占營收比」衡量,從 1991–1995 年的 1.80 一路掉到 2011–2014 年的 0.08,幾近於零
- 解讀:藥廠仍獲利,但 R&D 的回報持續下滑——這也解釋了為何藥廠紛紛轉向併購年輕公司,買它們研發中的產品
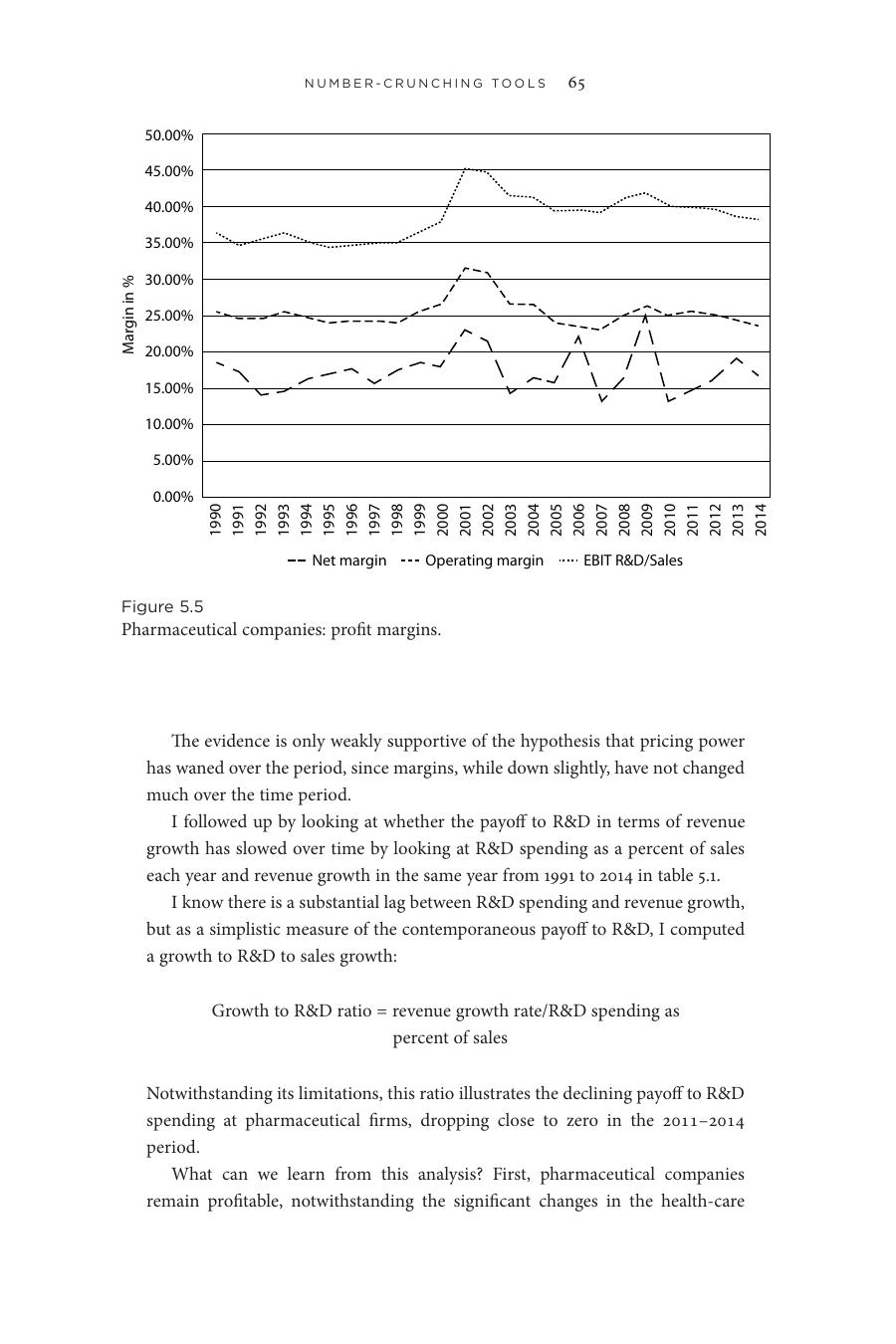
Figure 5.5: 製藥公司歷年毛利率走勢
案例 5.2:埃克森美孚對油價的曝險(2009 年 3 月)#
- 評估埃克森美孚(ExxonMobil)時,油價已從約 80 美元跌到 45 美元,但財報還反映高油價時的營收
- 把 1985–2008 年的營業利益對年均油價做迴歸,R² 高達 90.7%——油價幾乎完全解釋公司營收
- 把 45 美元代回去,得到調整後營業利益約 345 億美元,遠低於前 12 個月的呈報數字
- 這份調整成為他在第 13 章正式估值埃克森美孚的依據
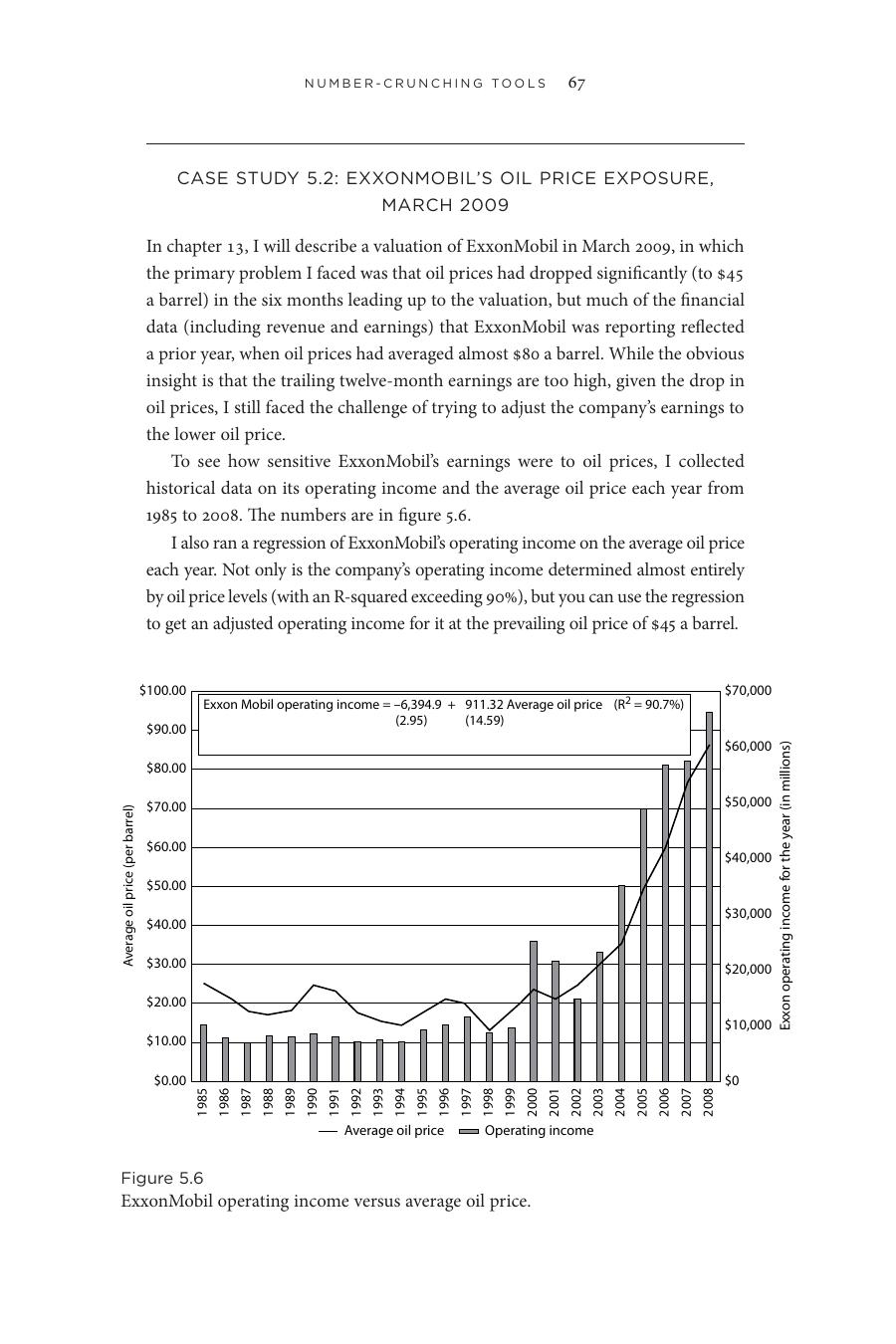
Figure 5.6: 埃克森美孚營業利益與年均油價的迴歸關係
案例 5.3:Petrobras 的價值毀滅迴圈(2015)#
達莫達蘭用一張圖描繪巴西石油(Petrobras)市值蒸發近 1,000 億美元的循環:
1. 大量再投資,且投資得很差
2. 營收成長,毛利下滑
3. 像公用事業一樣派發高股息
4. 借更多錢補窟窿
5. 任務完成(價值毀滅)
6. 重來一遍達莫達蘭坦言這張圖違反多項視覺化原則、塞了太多資訊。但他想表達的是:這些行動之間有嚴密的邏輯因果——大投資加上不顧獲利,逼公司舉債支應,又因要維持高股息而循環惡化。
Figure 5.7: Petrobras 2015 年的價值毀滅路線圖
結語#
處理資料的三步(蒐集、分析、呈現)每一步都可能讓資料服膺先入之見。願意保持開放心態、向資料學習,數字才會強化你的故事力,並引向更好的決策。