可部署性(Deployability) 與可測試性共同決定部署管線的速度——具體來說,它描述「一個已被部署管線驗證的元件,被送到生產環境的速度、便利度與可靠性」。流暢交付的組織每位開發者每天至少部署一次,因此高可部署性是必備條件。
部署管線完成驗證後,會交給「部署機制(deployment mechanism)」把元件送上線。部署機制的細節依技術不同。例如,把 Spring Boot 部署到 Kubernetes 通常包含三步:
- 建構 container image,推送到 registry。
- 更新生產環境的 Kubernetes YAML,指向新版 image。
- 觸發 rolling update,以新實例取代舊實例。
可部署性的場景#
幾個典型場景:
- 快速、不中斷部署:測試完成後 5 分鐘內部署成功,沒有違反 SLA。
- 配置錯誤導致啟動失敗:啟動失敗被偵測,部署回滾,沒有違反 SLA。
- 效能異常:新版的某 REST endpoint 因低效查詢延遲過高,被偵測並回滾,沒有違反 SLA。
高可部署性的設計面向#
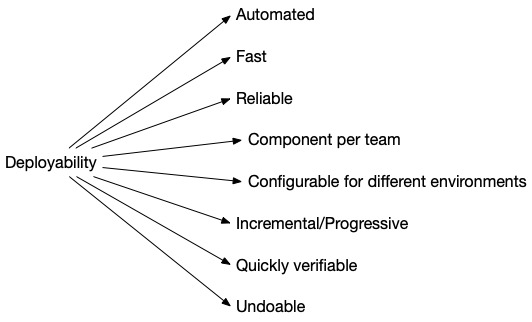
Figure 5.17: The dimensions of deployability that are important for fast flow
自動化部署#
- 人工部署既慢又易錯,跟不上流暢交付的變更速度,且會增加團隊認知負荷。
- DevOps 的技術實踐之一:部署管線完成測試後,自動部署元件。
部署速度要快#
部署過程通常包含三步:
- 把元件包成可上線格式(如 container image),推送到 registry。
- 配置生產環境使用新版,觸發資源調度與新版 rollout。
- 等待新實例 ready 接受生產流量。
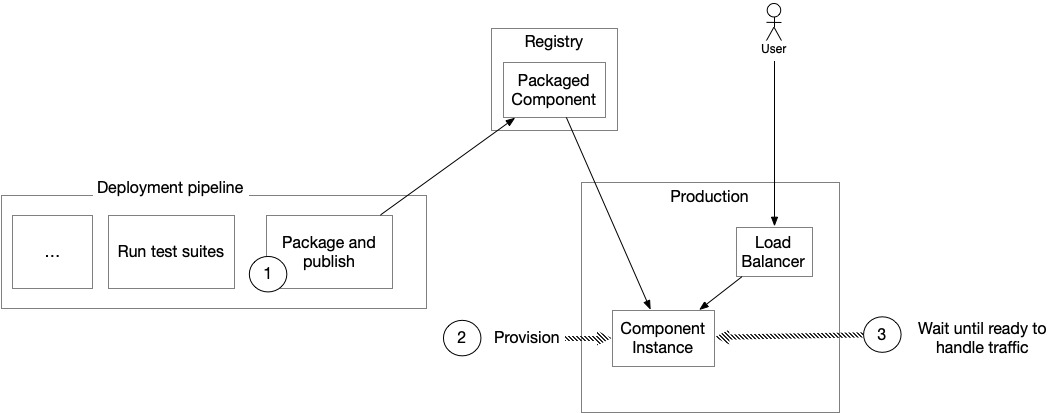
Figure 5.18: The deployment process consists of three steps — package & publish, configure production, instances become ready
整個流程應該以「分鐘」為計量。
- 資源調度要快:特別是漸進式部署(下面會講)會讓新舊版同時存在。
- 元件啟動要快:大型 Java 元件啟動可能要數分鐘——多元件架構的元件較小,啟動時間自然短。
- 多元件架構並行部署:每個元件有自己的管線,可平行運行;單一元件架構則容易因頻繁推送變更導致部署機制塞車。
可靠性#
部署不該隨機失敗——失敗多耗在診斷與修復,得不償失。除了自動化以外,還要從設計面下手:
- 連線排空(connection draining):在終止舊實例前,把進行中的(HTTP)請求處理完。
- 長時間背景任務可中斷可恢復:大型批次工作要設計成可中斷、可續跑,避免拖延升級或丟失工作成果。
每個團隊一個元件#
《Accelerate》發現:高效能團隊能不需協調就部署自家變更。最直接的做法是把每個團隊綁定一個元件,讓每個元件有自己的部署管線。
可被配置給不同環境#
元件只建一次,但可部署到多個環境(test、staging、production)而不重建。
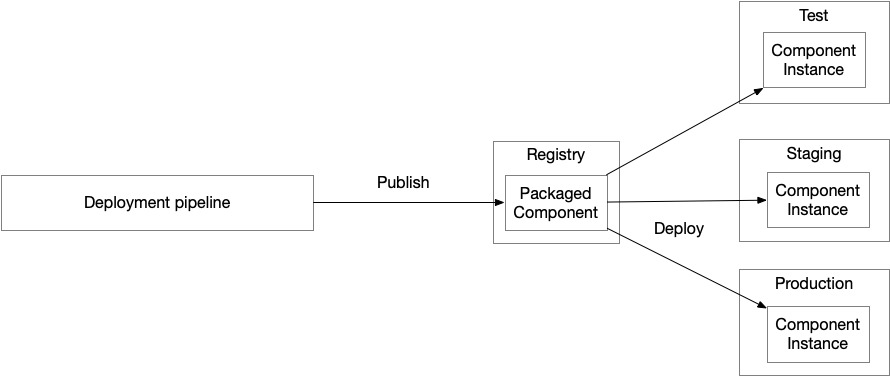
Figure 5.19: A packaged component built once by the deployment pipeline can be deployed to multiple environments
實作:
- 不要把執行環境資訊寫死進元件。
- 所有配置(資料庫主機、憑證等)在執行期透過環境變數或外部配置注入。
- 第 17 章的 External Configuration 模式處理這個問題。
漸進式部署(Incremental / Progressive Deployments)#
即使測試做得再徹底,生產環境的 bug 仍不可避免。漸進式部署的關鍵心法:把「部署」與「釋出」解耦。
- 部署:把新版本跑起來。
- 釋出:把流量導到新版本。
最常見策略:Canary release
- 新版與舊版並存。
- 起初只把少量流量導向新版。
- 比例逐漸提高,直到 100%。
- 若 telemetry(見可觀測性)顯示問題,立即回滾。
可快速驗證#
部署成功與否需要快速判斷。「啟動成功」只是基本指標——元件可能啟動了卻每個請求都回 HTTP 500,或某查詢效率差導致延遲飆升。
解法是借助可觀測性:部署機制應分析新元件的 telemetry(error rate、latency 等),若數據異常就視為失敗。
可回滾(Undoable)#
部署失敗時,部署機制應能快速回滾。
- 理想:回滾就是把流量切回仍在執行的舊版實例。
- 次選:重啟舊版本元件——通常較慢,且讓失敗影響擴大。