如同 2000 年代初期開發的許多應用,FTGO 的第一版是一個巨石——單一 Java Web Application Archive(WAR)檔。一開始,巨石架構運作良好,讓 FTGO 業務迅速擴張,成為美國領先的線上美食外送公司之一。
但隨著業務成長,應用與工程組織也快速膨脹:工程團隊從 1 個團隊變成 20 多個團隊,程式碼變得龐大且複雜。儘管團隊持續努力,FTGO 還是逐漸演變成 Foote 與 Yoder 提出的「Big Ball of Mud(大泥球)」反模式典型範例——一個結構雜亂、處處膠帶與鐵絲、義大利麵般的程式碼叢林。最後,開發速度慢到甚至危及 FTGO 的海外擴張計畫。
FTGO 應用架構#
FTGO 應用的核心其實很單純:
- 消費者透過官網或行動應用在當地餐廳點餐。
- FTGO 協調外送員(courier)送餐,並負責支付餐廳與外送員。
- 餐廳透過官網編輯菜單與處理訂單。
- 對外整合 Stripe(payment)、Twilio(訊息)、Amazon SES(email)等第三方服務。
FTGO 採用六角架構(hexagonal architecture,第 13 章詳述):
- 核心:業務邏輯,由多個領域物件模組組成,例如 Order Management、Delivery Management、Billing、Payments。
- 入站介接卡(inbound adapter):REST API、Web UI 等,接收外部請求並呼叫業務邏輯。
- 出站介接卡(outbound adapter):存取 MySQL、呼叫 Twilio、Stripe 等雲端服務。
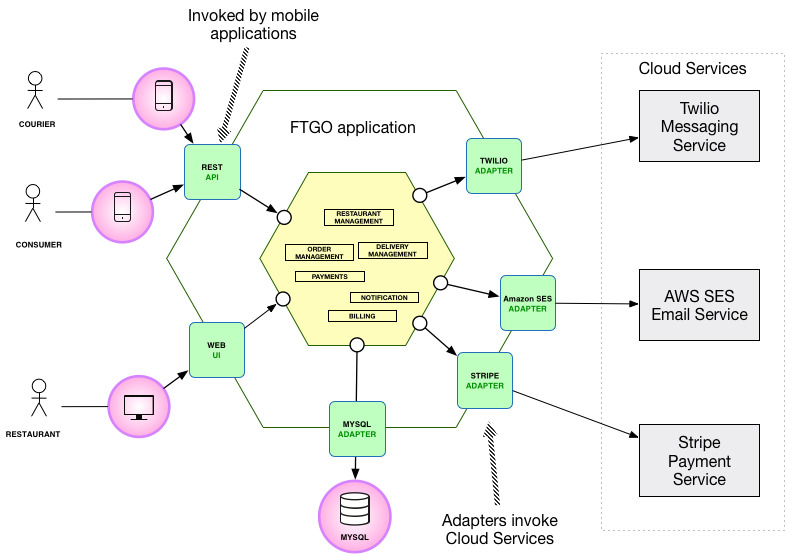
Figure 2.1: The FTGO application has a hexagonal architecture with business logic surrounded by adapters
邏輯上 FTGO 是模組化的,但部署上仍是單一 WAR 檔——這是典型的巨石風格。
巨石本身不是壞事——FTGO 在初期選擇巨石是合理決定。
為何巨石起初運作良好#
早期 FTGO 享受了巨石的多項優勢:
- 開發簡單:IDE 與工具圍繞單一應用設計,體驗一致。
- 大幅變更容易:程式碼與資料庫 schema 可以一起修改、建置、部署。
- 測試直觀:用 Selenium 撰寫端到端測試,啟動應用、呼叫 REST API、驗證 UI。
- 部署直觀:把 WAR 檔複製到裝有 Tomcat 的伺服器即可。
- 擴展容易:用負載平衡器(load balancer)後面跑多個應用實例。
但隨著時間推移,開發、測試、部署與擴展都越來越困難。到 2016 年,情況已惡化為痛苦的「死亡行軍」(death march)。
自以為的巨石地獄是怎麼形成的#
如同許多成功的應用,FTGO 應用每個 sprint 累加更多 story,程式碼庫不斷成長;隨著公司更成功,工程組織也擴大,管理開銷與耦合度同步攀升。當小應用變成大應用、單一團隊變成多團隊,敏捷開發與部署實質上不可能。
壓倒性的複雜度#
雖然六角架構在圖上看起來乾淨,但 FTGO 開發者與管理者忽視了設計與程式碼品質,實際上的領域並不模組化。
例如
Order類別膨脹到上千行,負責整個訂單生命週期(建立、配送、付款),沒人能完全理解。
複雜度形成惡性循環:
- 程式碼難懂 → 開發者難以正確修改 → 每次修改都讓程式碼更複雜 → 下一個開發者更難修改。
- 圖上「乾淨、模組化」的架構,逐漸與真實現況脫節。
開發速度變慢#
- 龐大的程式碼讓 IDE 卡頓。
- 建置時間長。
- 應用啟動慢。
- 「edit-build-run-test」迴圈拖長,生產力嚴重受影響。
從 commit 到部署的路長且痛苦#
- 每月才部署一次,通常選在週五或週六深夜。
- 對照 SaaS 的最佳實踐(continuous deployment,例如 Amazon 在 2015 年達到每天 13 萬次部署、約每 0.66 秒一次),FTGO 連「每月超過一次」都像遙遠夢想。
- FTGO 部分採用 agile(squad、兩週 sprint),但 code complete 到上線的路依然漫長:
- 多人提交到同一個程式碼庫,build 經常處於不可釋出狀態。
- 改用 feature branch 又造成漫長且痛苦的 merge。
- 一個 sprint 結束後,要花長時間做測試與穩定。
- 因為程式碼複雜、變更影響不明,整套測試都得跑,部分還需要手動測試,診斷失敗也很慢——一個測試週期要好幾天。
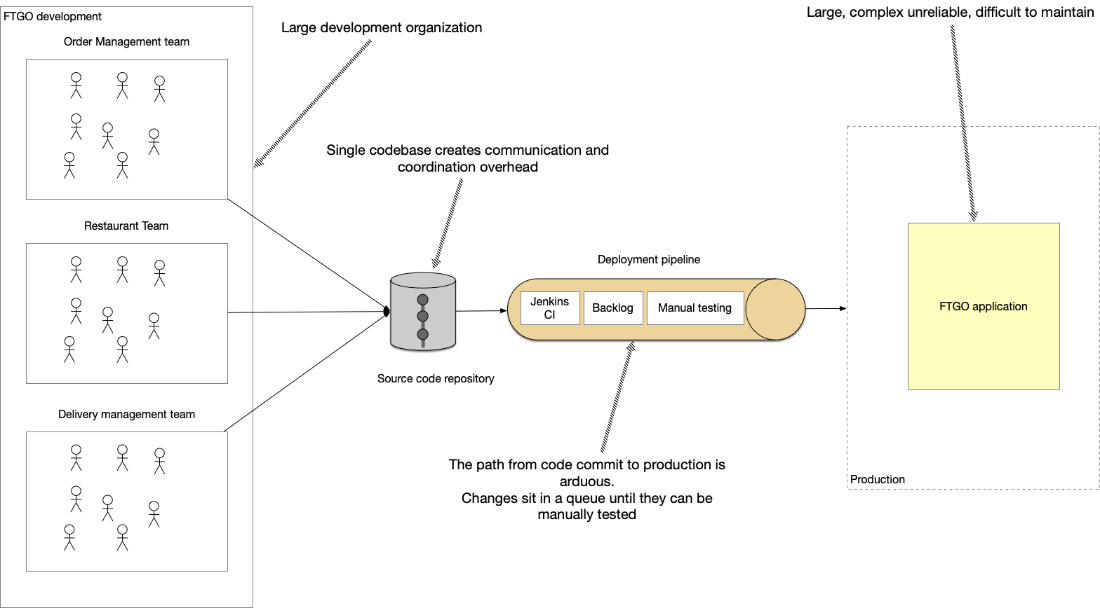
Figure 2.2: A case of outgrowing a monolithic architecture — long path from commit to production, manual testing
可靠性差、難以交付#
- 應用太大,難以充分測試;bug 因此進入生產。
- 所有模組跑在同一個 process 裡,缺乏故障隔離(fault isolation):某個模組的記憶體洩漏會逐一拖垮所有應用實例。
- 部署不頻繁,每次 release 累積大量變更,事故根因排查像「在草堆裡找針」。
- 開發者在半夜被叫醒救火;業務端蒙受營收與信任損失;客戶在最想點宵夜的時候點不到,有些人從此流失。
擴展困難#
不同模組對資源的需求不同,但因為在同一個 process,只能折衷:
- 餐廳資料放在大型記憶體資料庫,需要記憶體大的伺服器。
- 影像處理模組是 CPU 密集,需要 CPU 強的伺服器。
- 同一個應用無法同時最佳化兩種需求。
技術棧難以演進#
- 升級 JVM 與框架/函式庫經常牽動整個應用,有時要動員整個工程組織。
- 業務不願核准這類升級,擔心新功能交付被拖。
- 結果:技術棧落後好幾個版本;當安全性漏洞需要急修時,出現週期性的恐慌。
- 巨石架構讓組織被鎖在 JVM 上,難以實際嘗試 Go 或 Rust 等非 JVM 語言。所幸 JVM 生態系仍然蓬勃,這個問題沒有變得更糟。
FTGO V1 的這些症狀——開發慢、部署慢、可靠性差、難擴展、難演進——是「monolithic hell」的典型樣貌,也是 CTO Mary 後來決定全面轉向微服務架構的直接原因。下一節會看到她如何把 FTGO 帶進另一種地獄。