當機器接手,自我意識去了哪裡#
2009 年 6 月,一架法國航空 Airbus A330 從里約飛往巴黎,在大西洋上空墜毀。當夜雲層中的冰造成感測器失靈,自動駕駛斷開,副駕駛接手後因不熟練的操作讓飛機失速。
諷刺的是:飛機愈先進,駕駛員愈少有機會親手操作;當需要他們接手時,許多基本技能已經生疏。自動化的代價,往往是人類自我意識的退場。
蘇格拉底在《費德羅篇》中借由古埃及王 Thamus 對「文字」這項新發明的擔憂,提醒我們類似的風險:「人們將顯得無所不知,實際上一無所知;他們將擁有智慧的形式,而沒有智慧的實質。」
文字最終並未帶來這樣的災難。但 AI 與機器學習可能不同——因為它們不像書本那樣透明。
AI 的不透明性#
過往的工具雖會擴增能力,但都是透明系統:印刷版每次印出同樣的書、按 Enter 鍵就換行、計算機按 2+2 永遠等於 4。
機器學習系統不一樣:
- 它們在某種意義上「有自己的心智」——但這個心智無法解釋自己
- 為何拒絕貸款申請?演算法本身往往說不清楚
- 為何會在某些罕見情境中誤判?訓練者也未必能事先預知
- 它們的能力遠超人類,但它們的自我覺察幾近於零
AI 的智慧能力與自我意識能力正在分道揚鑣。我們可能進入一個機器愈來愈聰明、卻愈來愈無法說明自己的世界——而我們則愈來愈被迫盲目信任它們。
兩種未來:兩條路徑#
作者提出兩條因應路徑:
- 路徑 A:把自我意識設計進機器——讓 AI 自身具備某種後設認知
- 路徑 B:讓機器保持「聰明但不自我覺察」,但人機介面設計成能放大人類的自我意識,讓人類能精確監督機器
兩者都有根據,也各有風險。
為說明這些概念,書中以一台名為 Val 的玩具車為例——前方裝攝影機與兩盞顏色不同的燈,作為討論機器知覺與後設認知的縮影。
Val:書中用以討論機器自我意識的玩具車示意。© Stephen M. Fleming
路徑 A:能反思的機器#
要為機器加入後設認知,可以從追蹤不確定性開始:
- Dropout 技術:跑多份略為不同架構的網絡,預測的分歧度即代表不確定性
- 自駕車或無人機可以根據這個訊號主動避開信心低的決策
- 一個訓練成功的「自省無人機」(introspective drone)能在密林中即時判斷某個動作會不會撞機而放棄
這還只是初步。更進階的後設認知,需要對自己「為何」不確定有一個解釋——例如:「光線改變了?」「遇到沒見過的物體?」這已朝著「自我敘事」逼近。
哲學家 Andy Clark 與心理學家 Annette Karmiloff-Smith 在 1993 年就指出:
神經網絡的知識「在」系統中(in the system),而非「為」系統而存在(for the system)。
- 它能解問題,但不知道自己是怎麼解的
- 知識儲存於權重之中,無法被另一個系統讀取或被擁有者言說
- 必須加入「表徵的再描述」(representational redescription)——把學到的知識抽象化,才能進一步反思與分享
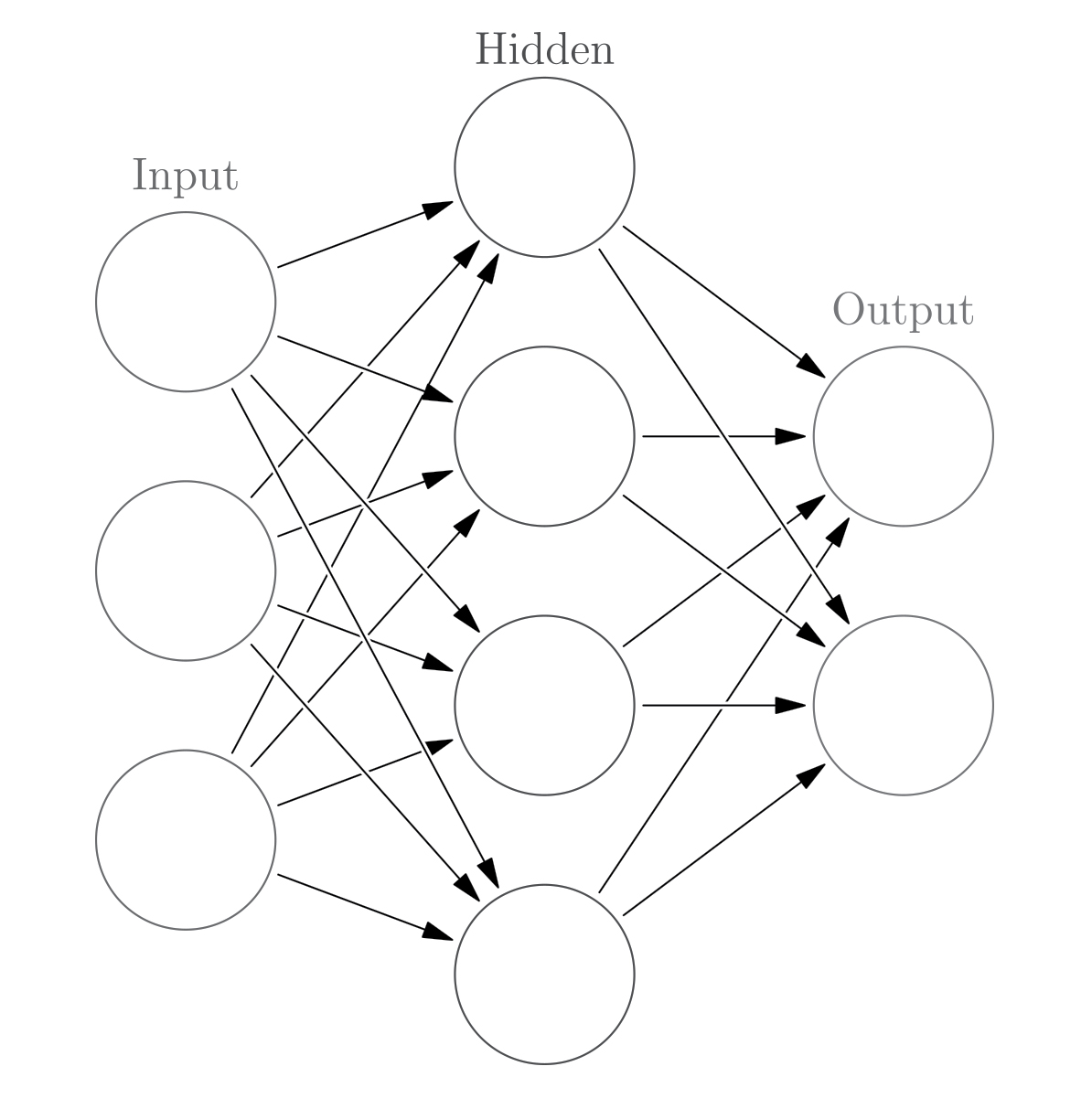
人工神經網絡的多層結構示意。圖:Glosser.ca,CC-BY-SA-3.0
科學界已開始建構帶有「後設認知層」的網絡:
- Yeung、Cohen、Botvinick(2004)的研究:在 Stroop 任務上加一個簡單的「衝突偵測」單元,就能模擬人類錯誤偵測的諸多現象
- Cleeremans 團隊:訓練第二層網絡監控第一層的輸入輸出,並能成功模擬盲視——切斷兩層的連結即可重現患者的行為模式
自我意識作為通用模型#
人類後設認知的一大優勢是抽象與遷移:
- 我對「自己」的認識,跨越所有情境通用
- 我相信自己擅長語言、不擅長運動——這個信念能引導我做出更好的選擇
- 在陌生城市使用地鐵時,我能用過去的「地鐵抽象模型」快速適應
機器若能內建這類「自我抽象」,就能:
- 知道自己擅長什麼、不擅長什麼
- 在陌生情境中保留必要的不確定性
- 不過度自信,也不過度保守
想像一個未來:自駕車根據自己的信心水準發出不同顏色的光——藍色代表「我很有把握」,黃色代表「我不太確定」。
- 兩台 AI 車相遇於路口時,能據此互相讓行
- 人類乘客也能據此判斷何時該介入
- 機器與機器、人與機器之間的「集體後設認知」由此誕生
路徑 B:與機器共腦#
第二條路是把人類的後設認知與機器的能力緊密耦合。
腦機介面(Brain-Computer Interface, BCI)的進展令人驚奇:
- 1980 年代起,研究者已能解碼運動皮質的訊號預測手部方向
- 四肢癱瘓的 Matt Nagle 在 2002 年透過植入裝置,靠思考移動電腦游標、轉換電視頻道
- 馬斯克(Elon Musk)的 Neuralink 等公司正積極開發精細植入技術
- 非侵入性的 EEG 結合機器學習,也可達到相似效果
多數現有 BCI 研究專注於「用大腦控制裝置」。但同樣的原理可以反過來——讓大腦監控自動裝置。
我們不需要懂引擎內部如何運作,就能在開車時感覺「不對勁」並停下;同樣地,未來機器可以由我們的後設認知監控,無需我們閱讀「使用說明書」即能即時介入。
兩種選擇背後的價值問題#
我們想活在哪一種世界?
- 選擇路徑 A:自我意識的機器將擁有某種道德地位——它們能犯錯、能知錯,這引發新的責任歸屬問題
- 選擇路徑 B:保留人類為「最後解釋者」——機器再聰明,也由人類負責賦予敘事與意義
「可解釋 AI」(Explainable AI)的常見方案是把機器內部「畫出來」給使用者看。但這就像給你一張 fMRI 腦造影圖,要你解釋自己為何選了某個三明治——那不是法律或社會意義上的解釋。
真正有意義的「為什麼」,需要後設認知層級的敘事——而這目前只有人腦能做。
結語:知己 + 知機#
歷史學家 Yuval Noah Harari 說:「我們投入到提升人工智慧的每一塊錢與每一分鐘,也應該等量投入到提升人類意識上。」
自我意識的科學提醒我們:在追求機器更聰明的同時,必須讓人類更清楚自己——以及更清楚自己與機器之間的關係。
未來的世界,可能不只是「認識你自己」(know thyself),而是同時要**「認識你的機器」**(know thy machine)。
下一章,我們將回到一個古老問題:認識自己這件事,能不能透過訓練變得更好?