集合(Collection)是 Java 程式設計中最基礎也最豐富的主題之一。表面上看,集合只是區分「在集合中」與「不在集合中」的物件,但深入探索後會發現,集合在結構與意圖傳達上有著遠超預期的豐富性。
集合混合了多種隱喻(metaphor),你所強調的隱喻會影響你使用集合的方式。每個集合介面傳達的是「一袋物件」的不同變體,每個實作類別則主要傳達效能特性的差異。因此,精通集合是學習用程式碼有效溝通的重要環節。
過去,類似集合的行為是透過資料結構本身的連結來實現的——例如文件中的每一頁都持有前一頁和後一頁的連結。現代做法則傾向使用獨立的集合物件來關聯元素,這使得同一個物件可以被放入多個不同的集合中,而無需修改物件本身。
集合之所以重要,是因為它們表達了程式設計中最基本的變化類型之一——數量的變化(variation of number):
- 邏輯的變化透過條件判斷或多型訊息來表達
- 資料基數的變化透過將資料放入集合來表達
- 集合的具體細節向讀者揭示了原始程式設計者的意圖
有一句古老的電腦諺語:唯一有趣的數字是 0、1 和 many。如果一個欄位的缺失代表「零」,欄位的存在代表「一」,那麼持有集合的欄位就是表達「多」的方式。
集合處於程式語言構造與函式庫之間的奇特地帶——它們如此普遍實用,使用方式也如此廣為理解,幾乎到了該讓主流語言支援類似 plural unique Book books; 這樣語句的時候了,而不是現在的 Collection<Book> books = new HashSet<Book>();。在集合成為語言的一等公民之前,了解如何使用現有的集合函式庫來直觀表達常見概念是很重要的。
本章的其餘部分分為六個部分:集合背後的隱喻、透過集合使用所表達的議題、集合介面及其對讀者的意義、集合實作及其傳達的資訊、Collections 工具類別的功能概覽,以及透過繼承擴展集合的討論。
Metaphors(隱喻)#
集合混合了不同的隱喻:
多值變數(Multi-Valued Variable)#
- 引用集合的變數在某種意義上是同時引用多個物件的變數
- 從這個角度看,集合作為獨立物件「消失了」,重要的只是它所引用的物件
- 如同所有變數,你可以對多值變數進行賦值(增刪元素)、取值,以及發送訊息(透過 for 迴圈)
物件(Object)#
- 在 Java 中,集合是具有**身份(identity)**的獨立物件,因此多值變數的隱喻有其局限
- 你可以取得集合、傳遞它、測試相等性、發送訊息
- 集合可以在物件之間共享,但這會產生**別名問題(aliasing problem)**的可能性
- 因為集合是一組相關的介面與實作,它們可以透過擴展介面和新增實作來延伸
兩種隱喻的結合效應#
這兩種隱喻的結合產生了一些奇特效果。因為集合被實作為可傳遞的物件,你會得到等同於 call-by-reference 的效果——傳遞的不是變數的內容,而是變數本身。對變數值的修改會反映在呼叫端。
Call-by-reference 在語言設計中已經過時數十年,因為可能產生非預期的副作用——當你無法確定一個變數會在哪些地方被修改時,程式就很難除錯。許多集合程式設計慣例的存在,就是為了避免難以預測集合在何處會被修改的情況。
數學集合(Mathematical Sets)#
- 集合就像數學集合——都是「一袋元素」
- 數學集合將世界分為集合內和集合外的元素;程式集合也是如此
- 兩個基本操作:求基數(cardinality)對應
size()方法,測試包含性對應contains()方法 - 數學隱喻只是近似的——聯集、交集、差集和對稱差等操作在集合中沒有直接對應
- 這些操作是因為本質上不太有用,還是因為不可用所以沒被使用,這是個有趣的辯題
Issues(議題)#
集合用於表達程式中數個正交概念。原則上,你應該盡可能精確地表達自己——使用最通用的介面作為宣告,使用最具體的實作類別。然而這不是絕對規則。
作者曾仔細地將 JUnit 中所有的變數宣告泛化,結果反而造成混亂——同一個物件在一處被宣告為
Iterable、另一處為Collection、又一處為List,這使程式碼更難閱讀。最後發現,統一宣告為List反而更清晰。
集合表達的概念包括:
| 議題 | 說明 |
|---|---|
| 大小(Size) | 陣列在建立時大小固定;大多數集合在建立後可以改變大小 |
| 順序(Order) | 元素之間有交互作用或外部使用者重視順序時,需要保留順序的集合。順序可以是元素加入的順序,也可以由外部影響(如字典排序)決定 |
| 唯一性(Uniqueness) | 有些計算只需要知道元素是否存在;有些則需要元素能在集合中出現多次 |
| 存取方式(Access) | 有時逐一迭代元素就夠了;有時需要透過 key 來存取和取回元素 |
| 效能(Performance) | 若線性搜尋夠快,通用的 Collection 就足夠了;若集合太大,則需要透過 key 來測試或存取元素,暗示使用 Set 或 Map |
關於效能:大多數程式設計者在大部分時間不需要擔心小規模操作的效能。然而,當經驗顯示效能需要改善、且測量指出瓶頸所在時,清楚地表達效能相關決策就很重要。為效能而寫的程式碼可能違反**局部後果(local consequences)**原則——對程式某部分的小改動可能影響另一部分的效能。例如,若某方法只有在傳入的集合能快速測試成員資格時才高效運作,那麼在程式其他地方將
HashSet替換為ArrayList可能會讓該方法變得極慢。作者的整體策略是:先用最簡單的實作,必要時再換更專門的集合類別,效能夠好時就停止調校。
flowchart TD
Q["選擇集合類型"] --> Q1{"需要透過 key\n存取元素?"}
Q1 -->|"是"| M["Map"]
Q1 -->|"否"| Q2{"元素需要\n唯一性?"}
Q2 -->|"是"| Q3{"需要排序?"}
Q2 -->|"否"| Q4{"需要\n穩定順序?"}
Q3 -->|"是"| SS["SortedSet"]
Q3 -->|"否"| S["Set"]
Q4 -->|"是"| L["List"]
Q4 -->|"否"| C["Collection"]Interfaces(介面)#
集合程式碼的讀者在查看你為變數宣告的介面和選擇的實作時,尋找的是不同的答案。介面宣告告訴讀者關於集合的資訊:集合是否有特定順序、是否有重複元素、是否能透過 key 查找元素。
以下介面依序說明:
| 介面 | 說明 |
|---|---|
| Array | 最簡單且最不靈活的集合:固定大小、簡單存取語法、速度快 |
| Iterable | 基本集合介面,只允許迭代 |
| Collection | 提供新增、刪除、測試元素的功能 |
| List | 元素有順序,可透過位置存取(如「給我第三個元素」) |
| Set | 不含重複元素的集合 |
| SortedSet | 有序且不含重複元素的集合 |
| Map | 透過 key 儲存和取回元素的集合 |
classDiagram
class Iterable {
<<interface>>
+iterator()
}
class Collection {
<<interface>>
+add()
+remove()
+contains()
+size()
}
class List {
<<interface>>
+get(index)
+set(index)
}
class Set {
<<interface>>
+不含重複元素
}
class SortedSet {
<<interface>>
+comparator()
+first()
+last()
}
class Map {
<<interface>>
+put(key, value)
+get(key)
+keySet()
}
Iterable <|-- Collection
Collection <|-- List
Collection <|-- Set
Set <|-- SortedSetArray#
Array 是最簡單的集合介面,但不幸的是,它們與其他集合沒有相同的協定(protocol),因此從 array 轉換為集合比在集合之間轉換更困難。與大多數集合不同,array 的大小在建立時就固定了。Array 也不同於其他集合,因為它內建於語言中,而非由函式庫提供。
- Array 在簡單操作上比其他集合更有效率
- 測試顯示 array 存取(
elements[i])比等效的ArrayList操作(elements.get(i))快十倍以上 - 其他集合類別的靈活性使它們在大多數情況下更有價值
- 當應用程式的某小部分需要更高效能時,array 是一個方便的選擇
Iterable#
將變數宣告為 Iterable 只表示它包含多個值。Iterable 是 Java 5 中 for 迴圈的基礎——任何宣告為 Iterable 的物件都可以在 for 迴圈中使用,這是透過靜默呼叫 iterator() 方法來實現的。
Iterable和Iterator沒有提供宣告式地表達「集合不應被修改」的方式- 一旦有了
Iterator,就可以呼叫其remove()方法來刪除底層Iterable中的元素 - 你的
Iterable不會被新增元素,但可能在擁有者不知情的情況下被移除元素
確保集合不被修改的幾種方式:用 unmodifiable collection 包裝、建立會在修改時拋出例外的自訂 iterator,或回傳安全副本。
Iterable 很簡單——它甚至不允許你測量實例的大小,你只能迭代元素。Iterable 的子介面提供更多有用行為。
Collection#
Collection 繼承自 Iterable,但新增了新增、刪除、搜尋和計數元素的方法。將變數或方法宣告為 Collection 為實作類別留下了許多選擇——盡可能模糊地保留宣告,可以保持日後更換實作類別的自由,而不會讓變更擴散到整個程式碼中。
Collection有點像數學集合的概念- 但執行聯集、交集和差集等效操作的方法(
addAll()、retainAll()、removeAll())會修改接收者,而非回傳新配置的集合
List#
List 在 Collection 的基礎上加入了元素處於穩定順序的概念。可以透過提供索引來取回元素。
- 當集合中的元素彼此交互時,穩定的序列很重要
- 例如,應按到達順序處理的訊息佇列應儲存在 list 中
Set#
Set 是不包含重複元素的集合(元素之間會透過 equal() 判斷相等性)。這與數學集合的概念密切對應,但隱喻並不完美——向 Set 新增元素會修改集合,而非回傳包含新元素的新集合。
Set捨棄了大多數集合保留的資訊——元素出現的次數- 當只關心元素是否存在而不關心出現次數時,這不是問題
- 例如,若要知道圖書館中所有書的作者是誰,不在乎每位作者寫了幾本書,
Set是合適的選擇 Set中的元素沒有特定順序;一次迭代的順序不保證下次相同- 在元素之間不交互的情況下,缺乏可預測的順序不是限制
若想在某個操作中去除重複但原集合可能有重複,可建立臨時的 Set:
printAuthors(new HashSet<Author>(getAuthors()));SortedSet#
集合的順序性和唯一性並非互斥。有時你希望保持集合有序但消除重複。SortedSet 儲存有序且唯一的元素。
- 與
List的順序不同(List的順序與元素加入順序或透過add(int, Object)指定的索引有關),SortedSet的順序由 Comparator 提供 - 若未指定明確的排序方式,則使用元素的「自然順序」——例如字串按字典順序排序
計算圖書館作者並按字母排序的範例:
public Collection<String> getAlphabeticalAuthors() {
SortedSet<String> results= new TreeSet<String>();
for (Book each: getBooks())
results.add(each.getAuthor());
return results;
}若 Book 的作者以物件表示,程式碼可能如下:
public Collection<String> getAlphabeticalAuthors() {
Comparator<Author> sorter= new Comparator<Author>() {
public int compare(Author o1, Author o2) {
if (o1.getLastName().equals(o2.getLastName()))
return o1.getFirstName().compareTo(o2.getFirstName());
return o1.getLastName().compareTo(o2.getLastName());
}
};
SortedSet<String> results= new TreeSet<String>(sorter);
for (Book each: getBooks())
results.add(each.getAuthor());
return results;
}Map#
Map 是最後一個集合介面,是其他介面的混合體:
- 以 key 儲存 value,但與
List不同的是,key 可以是任何物件而不僅是整數 - key 必須唯一(類似
Set),但 value 可以重複 - 元素沒有特定順序(類似
Set) - 因為
Map不完全像其他任何集合介面,它獨立存在,不繼承自任何介面 Map同時是兩個集合——key 的集合連結到 value 的集合- 你無法直接要求
Map的 iterator,因為不確定是要迭代 key、value,還是 key-value 對
Map 對於實作兩個實作模式特別有用:
- Extrinsic State(外部狀態):將與物件相關的特殊用途資料獨立於物件本身儲存。以
Map實作,key 為物件,value 為相關資料 - Variable State(可變狀態):同一類別的不同實例儲存不同的資料欄位。讓物件持有一個
Map,將字串(代表虛擬欄位名稱)對應到值
Implementations(實作)#
選擇集合的實作類別主要是效能考量。如同所有效能議題,最好先選擇簡單的實作,再根據經驗進行調校。
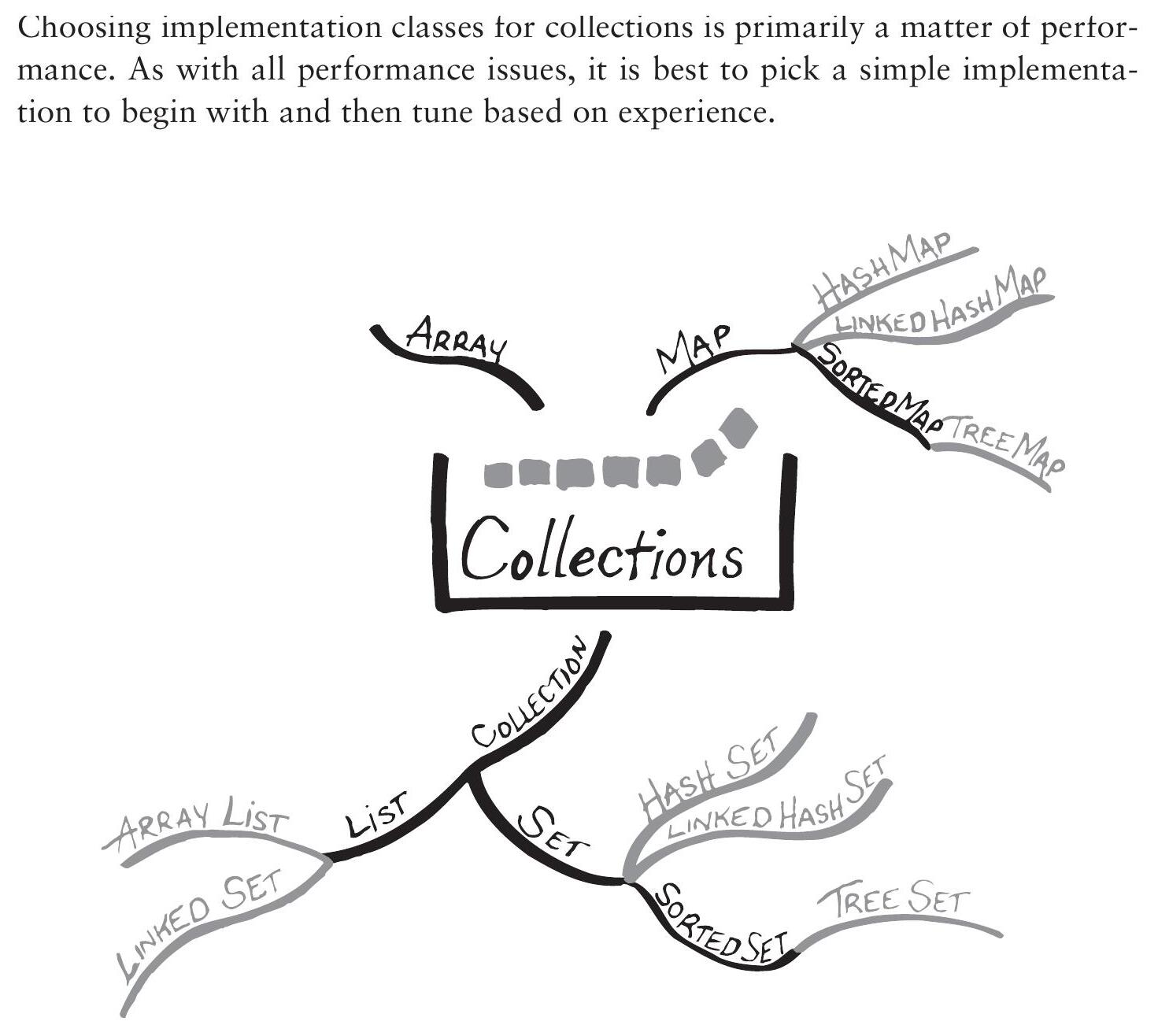
Figure 9.1: Collection interfaces and classes
在本節中,每個介面都會介紹替代的實作。因為效能考量主導了實作類別的選擇,每組替代方案都附有重要操作的效能測量。
絕大多數集合都使用 ArrayList 實作,HashSet 是遙遠的第二名(Eclipse+JDK 中約 3400 次引用
ArrayList,約 800 次引用HashSet)。快速做法是根據需求選擇這兩個類別之一。
選擇實作類別時的最終考量是集合的大小。下面的資料顯示的是大小從 1 到 100,000 的集合效能。若你的集合只包含一兩個元素,選擇可能與預期擴展到數百萬元素時不同。在許多情況下,切換實作類別帶來的效能提升有限,你可能需要尋找更大規模的演算法變更來進一步改善效能。
Collection 的實作#
實作 Collection 的預設類別是 ArrayList。ArrayList 的潛在效能問題是 contains(Object) 及依賴它的操作(如 remove(Object))所花時間與集合大小成正比。
- 若效能分析顯示這些方法是瓶頸,考慮將
ArrayList替換為 HashSet - 替換前,確認你的演算法不受捨棄重複元素的影響
- 若資料本身已保證不含重複,切換不會造成差異
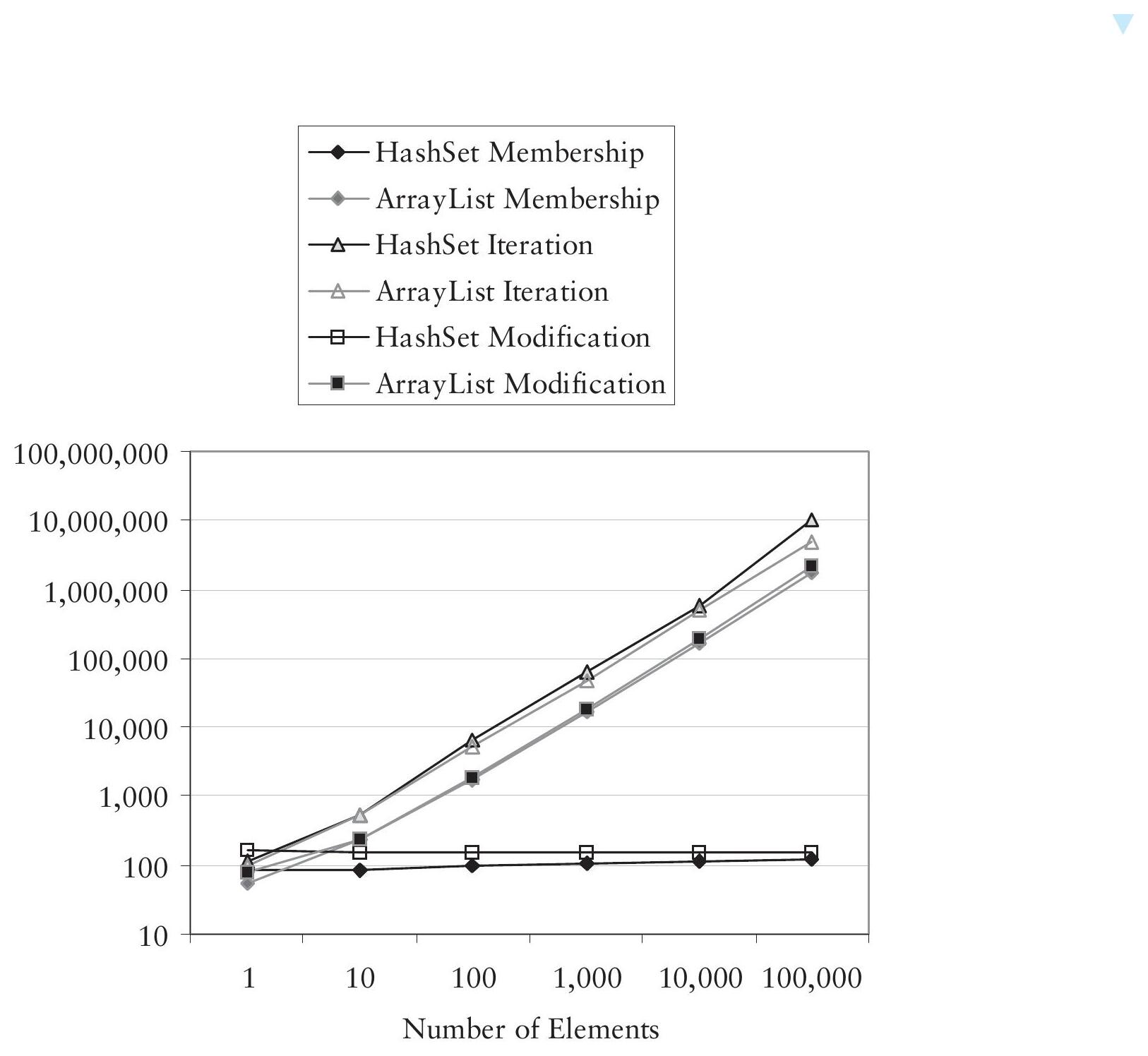
Figure 9.2: Comparing ArrayList and HashSet as implementations of Collection
List 的實作#
List 在 Collection 的協定上加入了元素有穩定順序的概念。常用的兩個 List 實作是 ArrayList 和 LinkedList。
這兩個實作的效能特性互為鏡像:
- ArrayList:存取元素快,增刪元素慢
- LinkedList:存取元素慢,增刪元素快
若效能分析顯示主要是 add() 或 remove() 呼叫,考慮將 ArrayList 切換為 LinkedList。
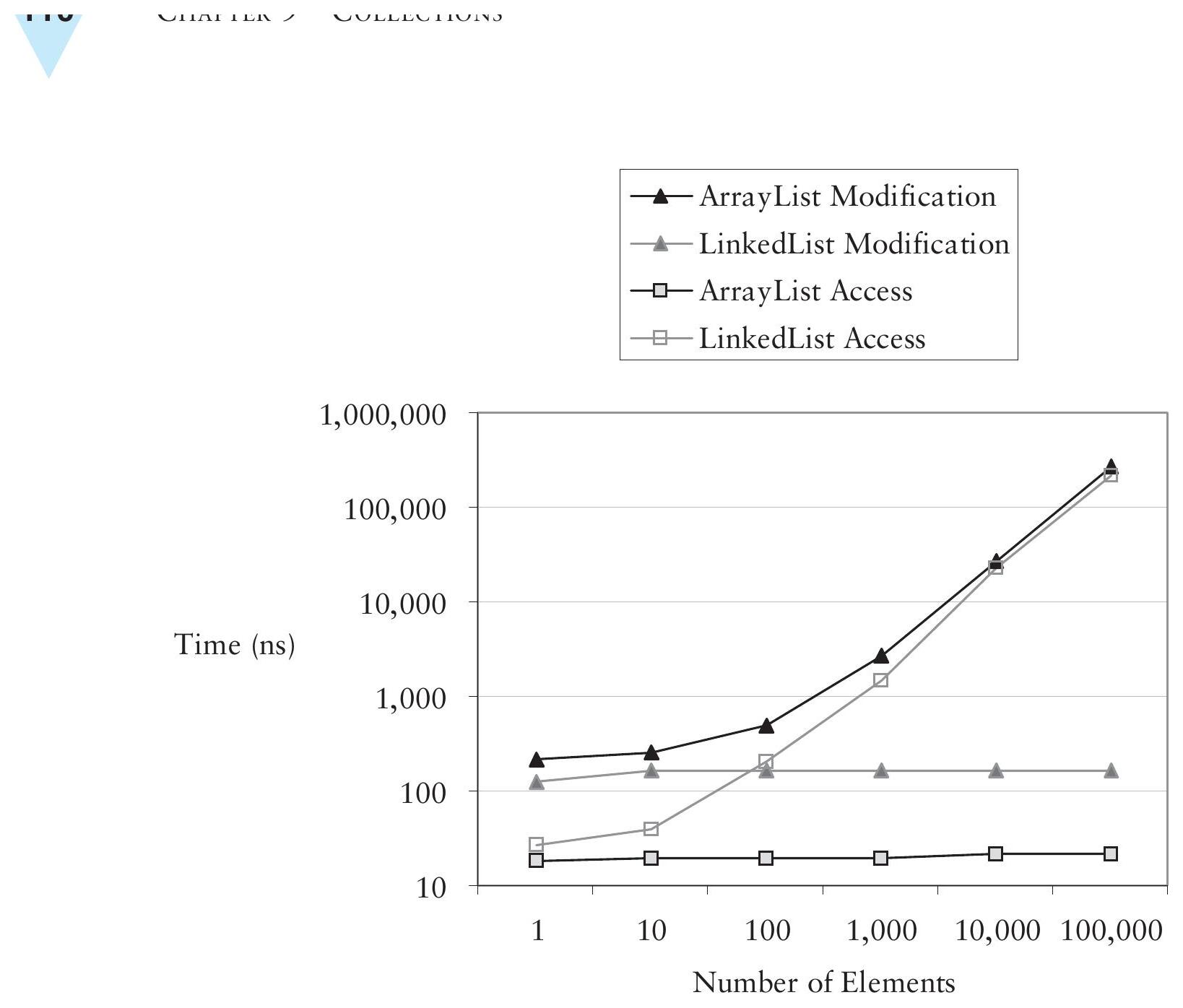
Figure 9.3: Comparing ArrayList and LinkedList
Set 的實作#
Set 有三個主要實作:HashSet、LinkedHashSet 和 TreeSet(實際實作 SortedSet):
| 實作 | 說明 |
|---|---|
| HashSet | 最快,但元素沒有保證的順序 |
| LinkedHashSet | 維持元素加入的順序,但增刪元素有額外約 30% 的時間開銷 |
| TreeSet | 根據 Comparator 保持元素排序,但增刪和測試成員資格的時間與 log n 成正比 |
若需要元素順序穩定,選擇 LinkedHashSet。例如外部使用者可能希望每次取得相同順序的元素。
Figure 9.4: Comparing Set implementations
Map 的實作#
Map 的實作遵循與 Set 類似的模式:
| 實作 | 說明 |
|---|---|
| HashMap | 最快且最簡單 |
| LinkedHashMap | 保留元素順序,按插入順序迭代 |
TreeMap(實際實作 SortedMap) | 根據 key 的順序迭代,但插入和包含性測試的時間與 log n 成正比 |
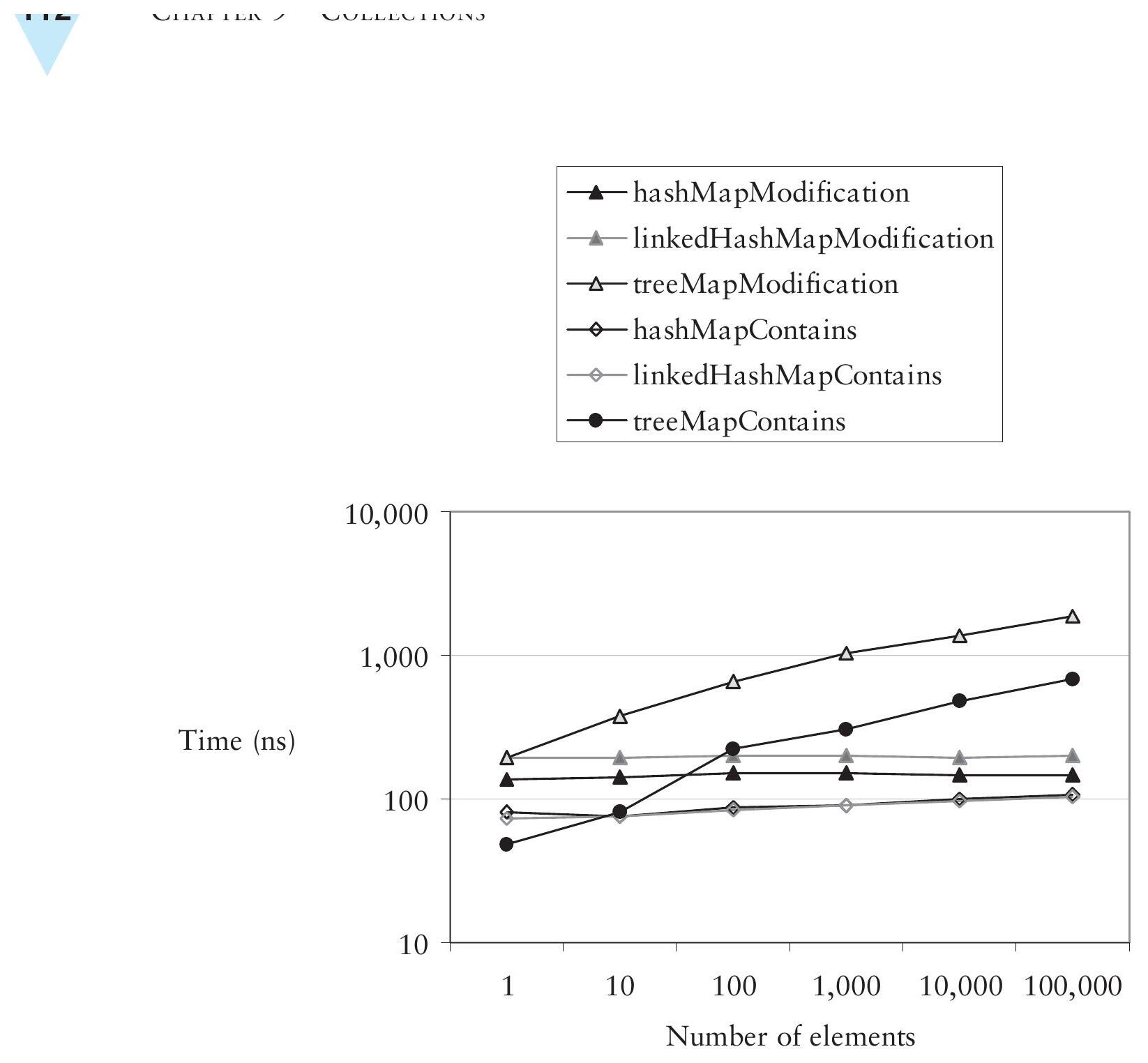
Figure 9.5: Comparing Map implementations
flowchart TD
A["選擇實作類別"] --> B{"介面類型?"}
B -->|"Collection/List"| C{"效能瓶頸?"}
B -->|"Set"| D{"需要順序?"}
B -->|"Map"| E{"需要順序?"}
C -->|"contains 慢"| C1["HashSet"]
C -->|"add/remove 慢"| C2["LinkedList"]
C -->|"無瓶頸"| C3["ArrayList ⭐"]
D -->|"插入順序"| D1["LinkedHashSet"]
D -->|"排序順序"| D2["TreeSet"]
D -->|"不需要"| D3["HashSet ⭐"]
E -->|"插入順序"| E1["LinkedHashMap"]
E -->|"key 排序"| E2["TreeMap"]
E -->|"不需要"| E3["HashMap ⭐"]Collections 工具類別#
Collections 工具類別是一個提供不適合放在任何集合介面中的集合功能的函式庫類別。以下是可用功能的快速概覽。
Searching(搜尋)#
indexOf() 操作所花時間與 list 大小成正比。然而,若元素已排序,**二分搜尋(binary search)**可在 log₂n 時間內找到元素的索引。
- 呼叫
Collections.binarySearch(list, element)回傳元素在 list 中的索引 - 若元素不在 list 中,回傳負數
- 若 list 未排序,結果不可預測
- 二分搜尋只對具有常數時間隨機存取的 list(如
ArrayList)有效能改善
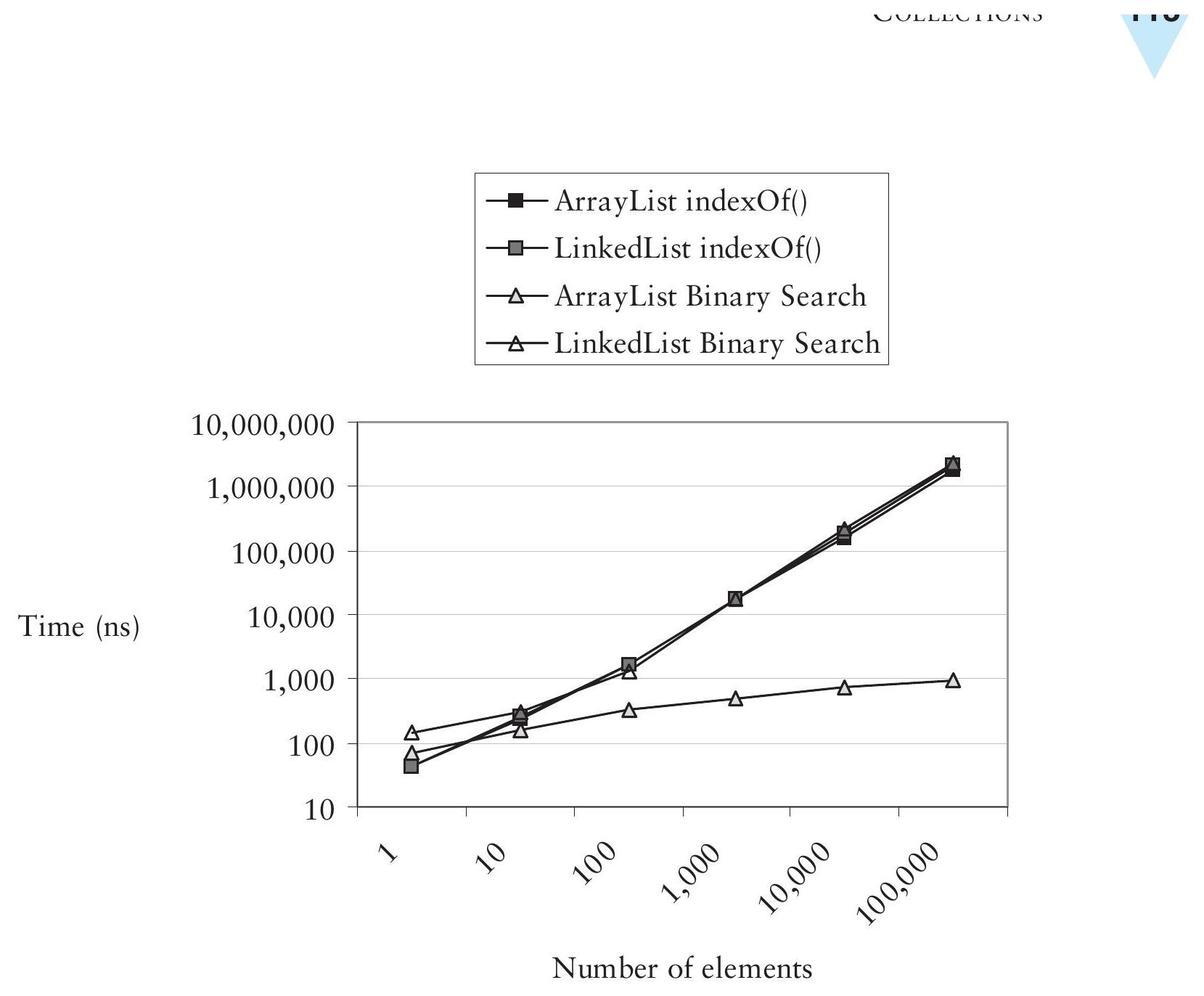
Figure 9.6: Comparing indexOf() and binary search
Sorting(排序)#
Collections 也提供改變 list 元素順序的操作:
reverse(list)— 反轉所有元素的順序shuffle(list)— 將元素隨機排列sort(list)和sort(list, comparator)— 將元素按升序排列
與二分搜尋不同,
ArrayList和LinkedList的排序效能大致相同,因為元素會先被複製到 array 中,排序 array,然後再複製回去。
Unmodifiable Collections(不可修改集合)#
即使最基本的集合介面也允許修改集合。若要將集合傳遞給不受信任的程式碼,可以讓 Collections 將它包裝在一個嘗試修改時拋出執行期例外的實作中。有適用於 Collection、List、Set 和 Map 的變體。
@Test(expected=UnsupportedOperationException.class)
public void unmodifiableCollectionsThrowExceptions() {
List<String> l= new ArrayList<String>();
l.add("a");
Collection<String> unmodifiable= Collections.unmodifiableCollection(l);
Iterator<String> all= unmodifiable.iterator();
all.next();
all.remove();
}Single-Element Collections(單元素集合)#
若你有一個元素但需要傳給期望集合的介面,可以呼叫 Collections.singleton() 快速轉換為 Set。也有轉換為 List 或 Map 的變體。所有回傳的集合都是不可修改的。
@Test public void exampleOfSingletonCollections() {
Set<String> longWay= new HashSet<String>();
longWay.add("a");
Set<String> shortWay= Collections.singleton("a");
assertEquals(shortWay, longWay);
}Empty Collections(空集合)#
類似地,若你需要使用期望集合的介面但沒有元素,Collections 會為你建立一個不可修改的空集合。
@Test public void exampleOfEmptyCollection() {
assertTrue(Collections.emptyList().isEmpty());
}Extending Collections(擴展集合)#
常見的做法是讓類別繼承某個集合類別。例如,持有書籍列表的 Library 可以透過繼承 ArrayList 來實作:
class Library extends ArrayList {...}這個宣告提供了 add()、remove()、迭代和其他集合操作的實作。
然而,繼承集合類別來獲得類集合行為有幾個問題:
- 不適當的操作暴露:集合提供的許多操作對用戶端不適用。例如,用戶端通常不應該能對
Library呼叫clear()或toArray()。最好的情況是隱喻混亂,最壞的情況是所有這些操作都需要透過實作並拋出UnsupportedOperationException來取消繼承 - 浪費繼承:為了取得幾行有用的實作程式碼,你卻阻止了以更高槓桿方式使用繼承的可能性
在這種情況下,**委派(delegate)**給集合比繼承更好:
class Library {
Collection<Book> books= new ArrayList<Book>();
...
}透過這種設計:
- 你可以只暴露有意義的操作,並給予有意義的名稱
- 你可以自由使用繼承來與其他模型類別共享實作
- 若
Library透過多個不同的 key 提供書籍存取,你可以適當命名操作:
Book getBookByISBN(ISBN);
Book getBookByID(UniqueID);只有在實作通用的集合類別(可以加入
java.util的東西)時才繼承集合。在所有其他情況下,將元素儲存在附屬的集合中。
Conclusion(結論)#
本章描述了使用集合類別的模式。至此,Java 及其集合類別的模式已全部介紹完畢。前述的模式都偏向應用程式開發——簡潔和易於溝通能降低成本,且可以一次性地改變整個應用程式的設計。下一章將描述在建構**框架(framework)**時如何調整這些模式——在框架中,複雜性是可接受的,只要它保留了在不改變所有應用程式碼的情況下持續演進框架的能力。