State#
本章的模式描述如何溝通你對狀態 (state) 的使用方式。
物件是行為與狀態的便利封裝——行為對外展示,狀態則在內部支撐行為。物件的一大優勢在於,它將程式中所有的狀態切割成微小的片段,每個片段實際上就像一台獨立的小型電腦。大量的狀態若被四處隨意引用,後續的程式修改就會變得困難,因為程式碼變動對狀態的影響難以預測。有了物件,分析哪些狀態會受到影響就容易得多——因為可引用的狀態命名空間大幅縮小了。
本章包含以下模式:
| 模式 | 說明 |
|---|---|
| State | 以隨時間變化的值進行計算 |
| Access | 透過限制對狀態的存取來維持彈性 |
| Direct Access | 在物件內部直接存取狀態 |
| Indirect Access | 透過方法存取狀態以獲得更大的彈性 |
| Common State | 將所有同類物件共有的狀態儲存為欄位 (field) |
| Variable State | 將因實例而異的狀態儲存為 map |
| Extrinsic State | 將與物件關聯的特殊用途狀態,儲存在使用該狀態的一方所持有的 map 中 |
| Variable | 變數為存取狀態提供命名空間 |
| Local Variable | 區域變數保存單一作用域的狀態 |
| Field | 欄位儲存物件生命週期內的狀態 |
| Parameter | 參數在單一方法被啟用期間傳遞狀態 |
| Collecting Parameter | 傳入參數以從多個方法中收集複雜結果 |
| Parameter Object | 將頻繁使用的長參數列表整合成一個物件 |
| Constant | 將不會變動的狀態儲存為常數 |
| Role-Suggesting Name | 以變數在計算中扮演的角色來命名 |
| Declared Type | 為變數宣告通用的型別 |
| Initialization | 盡可能以宣告式方式初始化變數 |
| Eager Initialization | 在實例建立時初始化欄位 |
| Lazy Initialization | 在欄位首次被使用前才初始化其值(適用於計算成本高的情況) |
State#
世界是持續存在的。如果一分鐘前太陽高掛天空,你可以確信它現在還在那裡,只是移動了一點。如果願意計算,我可以根據先前的觀測、地球自轉的知識、以及時間的流逝來預測它的新位置。
「把世界看成不斷變化的事物」這種思維方式,長久以來已被證明相當實用。當計算先驅們為程式設計挑選隱喻時,他們抓住了狀態隨時間變化這個概念。人腦對處理狀態有各式各樣的策略——有天生的,也有後天學會的。
然而,狀態也為程式設計師帶來問題:
- 只要你對某個狀態做出假設,程式碼就有風險——你可能假設錯誤,或者狀態可能已經改變
- 許多理想的程式設計工具(如自動重構器),在沒有狀態概念時更容易建構
- 並行性 (concurrency) 與狀態處不來——平行程式的許多問題在沒有狀態的情況下就會消失
函數式程式語言完全捨棄了可變狀態,但這類語言從未真正普及。作者認為狀態是一個有價值的隱喻,因為我們的大腦本就被結構化與訓練來處理變化的狀態。單次賦值或無變數的程式設計迫使我們放棄太多有效的思維策略。
物件導向語言是應對狀態的一種策略——它透過將系統狀態分割成離散的小塊,每塊都嚴格限制對其他塊的存取,來避免狀態在「背後」被改變的問題。追蹤幾個位元組比追蹤數百萬位元組容易得多。
有效管理狀態的關鍵是把相似的狀態放在一起,確保不同的狀態保持分離。判斷兩個狀態是否相似的兩個線索:
- 它們是否在同一個計算中被使用
- 它們是否同時產生和消亡
如果兩個狀態既一起使用又有相同的生命週期,那麼將它們放在彼此附近可能是個好主意。
flowchart TD
A["兩個狀態片段"] --> B{"在同一個計算中\n被使用?"}
B -->|"是"| C{"有相同的\n生命週期?"}
B -->|"否"| D["分開存放"]
C -->|"是"| E["放在一起\n同一物件/同一方法"]
C -->|"否"| F["考慮不同的\n儲存機制"]Access#
程式語言中有一個二分法:存取已儲存的值 vs. 呼叫計算。這兩個概念可以用彼此來理解:
- 存取記憶體就像呼叫一個回傳當前儲存值的函式
- 呼叫函式就像讀取一個記憶體位置,只不過其內容恰好是計算而來而非單純回傳
然而,我們的程式語言將呼叫計算與存取記憶體分開了,因此我們需要能有效溝通兩者的差異。
決定什麼要儲存、什麼要計算會影響程式的:
- 可讀性 (readability)
- 彈性 (flexibility)
- 效能 (performance)
這些目標有時會彼此衝突,而且情境會改變,昨天合理的儲存與計算的劃分今天可能不再適用。做出當下可行的決定,同時保留未來改變心意的彈性,是良好軟體開發的關鍵。正因為需要未來的變更,你才需要清楚地溝通「儲存 vs. 計算」的決策。
物件的目標之一是管理儲存。每個物件就像擁有自己記憶體的小型電腦,在某種程度上與其他小電腦隔離。但現代語言(包括 Java)透過提供 public 欄位模糊了物件之間的邊界。物件間存取的便利性不值得犧牲物件之間的獨立性。
Direct Access#
表達「我在取資料」或「我在存資料」最簡單的方式就是直接變數存取:
x = 10;優點:表達清晰——當你讀到 x = 10;,你確切知道會發生什麼。
缺點:
- 喪失彈性——如果將值儲存在變數中,就只能做這件事。若從程式多處將值存入該變數,要做更動就可能需要改動所有那些地方。
- 屬於實作細節——低於大多數程式思考的層次。
比較以下三種寫法:
doorRegister = 1;openDoor();door.open();大多數程式設計時的想法與儲存無關。廣泛的直接存取會使溝通變得雜亂。只有在你真的在思考「什麼東西儲存在哪裡」時,才使用直接存取來表達那些想法。
沒有適用於所有人的直接存取通用規則。有人堅持「只在 accessor 方法和建構子內部使用直接存取」、有人說「只在單一類別內、或類別與其子類別內、或整個 package 內」。沒有萬用規則——程式設計師需要思考、溝通、學習,這是專業的一部分。
Indirect Access#
你可以將對狀態的存取和修改隱藏在方法呼叫後面。這些 accessor 方法以犧牲清晰度與直接性為代價提供彈性。客戶端不再假設某個值是直接儲存的,因此你可以改變儲存決策而不影響客戶端程式碼。
作者的預設策略:
- 類別內部(含 inner class):允許直接存取
- 客戶端:使用間接存取
這個策略的優點是大多數存取都是清晰、直接的。
flowchart TD
A["存取物件狀態"] --> B{"存取者是誰?"}
B -->|"類別內部\n含 inner class"| C["Direct Access\n直接存取欄位"]
B -->|"外部客戶端"| D["Indirect Access\n透過方法存取"]
D --> E{"資料是否耦合?"}
E -->|"是"| F["必須使用 Indirect Access\n例:setter 更新快取"]
E -->|"否"| G["Indirect Access\n保持彈性"]如果物件狀態的大多數存取來自物件外部,那代表有更深層的設計問題潛伏著。
另一種策略是全面使用間接存取,但這會導致清晰度下降:
- 大多數 getter/setter 方法都是瑣碎的
- 它們常常數量超過真正執行有用工作的方法,使程式碼難以閱讀
- 大量的 getter/setter 很誘人——與其思考計算該放在哪裡,不如直接在任意位置實作然後用 accessor 方法取得所需狀態
間接存取的明確使用場景:兩筆資料是耦合的。有時耦合非常直接,例如快取值:
// Rectangle
void setWidth(int width) {
this.width = width;
area = width * height;
}有時耦合較間接,透過 listener:
// Widget
void setBorder(int width) {
this.width = width;
notifyListeners();
}這種耦合不太理想(容易忘記維護隱含的約束),但可能是最佳的可用選項。在這種情況下,間接存取是最好的選擇。
Common State#
許多計算共享相同的資料元素(即使值不同)。當你發現這樣的計算時,透過在類別中宣告欄位來溝通。例如,所有笛卡爾座標點的計算都需要 x 軸和 y 軸座標。由於所有笛卡爾座標點共享對這些值的需求,最清楚的表達方式就是宣告為欄位:
class Point {
int x;
int y;
}Common state 的優點:
- 從程式碼(無論是欄位本身或完整建構子)就能清楚得知,要建立一個格式正確的物件需要哪些資料
- 讀者會想知道成功呼叫物件功能所需的條件,common state 精確地溝通了這一點
物件中的 common state 應該都具有相同的作用域和生命週期。如果你被誘惑引入一個只被部分方法使用、或只在某個方法執行時才有效的欄位——通常可以透過找到其他地方來儲存該資料(例如 parameter 或 helper object)來改善程式碼。
Variable State#
有時同一物件根據使用方式需要不同的資料元素。不只是值不同——同一類別的物件中,完全不同的元素可能存在或不存在。
Variable state 通常儲存為一個 map,其鍵是元素名稱(以字串或列舉表示),值是資料值:
class FlexibleObject {
Map<String, Object> properties = new HashMap<String, Object>();
Object getProperty(String key) {
return properties.get(key);
}
void setProperty(String key, Object value) {
properties.set(key, value);
}
}Variable state 比 common state 靈活得多,但主要缺點是溝通不佳:
- 只有 variable state 的物件,需要哪些資料元素才能正常運作?只有仔細閱讀程式碼甚至觀察執行才能回答這個問題
- 如果程式設計師過度使用 variable state(例如每個物件的 property map 中都有完全相同的鍵),改用欄位宣告會更易讀
何時適合使用 Variable State#
一個合理的場景是:某個欄位的狀態暗示了其他欄位的需求。例如,一個 widget 的 bordered 旗標為 true 時,才需要 borderWidth 和 borderColor。這可以用 variable state 來溝通,如 Figure 6.1 上方的設計。
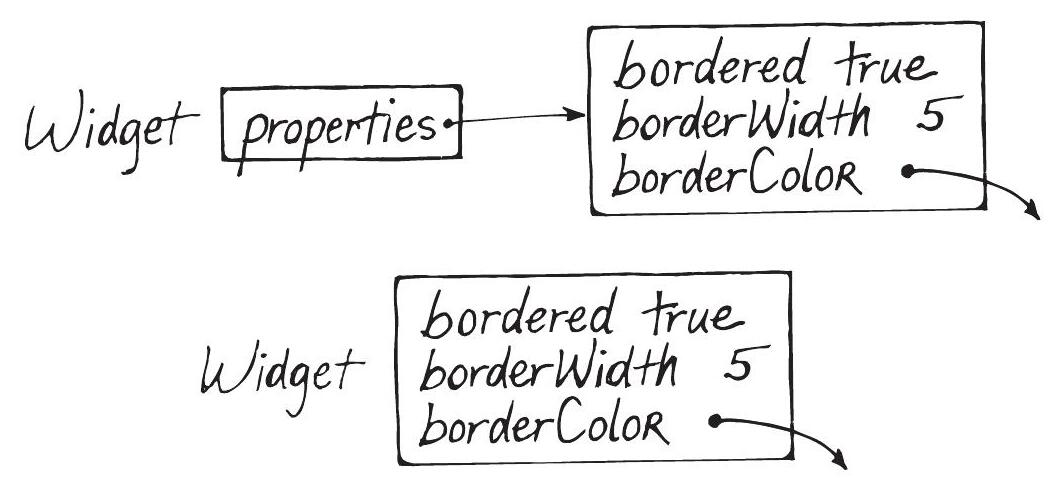
Figure 6.1: Border represented by variable state and common state
Common state 也能表達這一點(如 Figure 6.1 下方)。但 common state 的做法違反了「物件中所有變數應有相同生命週期」的原則。多型 (polymorphism) 提供了更清晰的解釋:一個類別代表無邊框狀態,另一個代表有邊框狀態,後者用 common state 表示其參數。
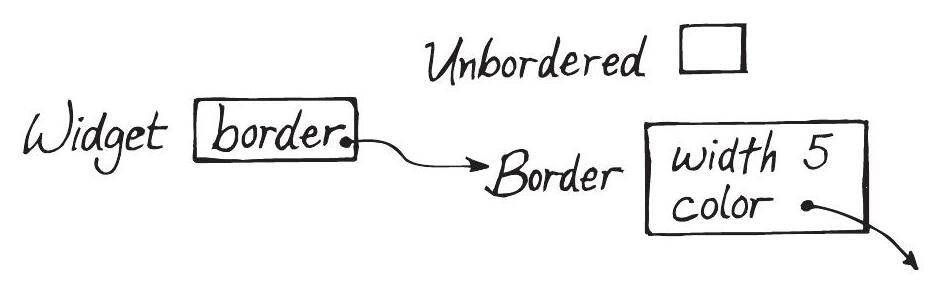
Figure 6.2: A helper object cleans up the design
多個變數共用相同的前綴,是某種 helper object 可能有用的線索。
盡可能使用 common state。只有在物件的欄位可能因使用方式不同而需要或不需要時,才使用 variable state。
Extrinsic State#
有時程式的某個部分需要與物件關聯的狀態,但系統的其餘部分並不關心。例如,物件在磁碟上的儲存位置資訊對持久化機制有用,但對其餘程式碼沒有意義。將這類資料放入欄位會違反對稱性 (symmetry) 原則——其他所有欄位都對整個系統有用。
做法:將與物件關聯的特殊用途資訊,儲存在靠近其使用位置的地方,而非儲存在物件中。例如,持久化機制會儲存一個 IdentityMap,其鍵是被儲存的物件,值是關於它們儲存位置的資訊。
Extrinsic state 的弱點:
- 複製困難——複製具有 extrinsic state 的物件不只是複製其欄位那麼簡單;所有 extrinsic state 也必須正確複製,且可能需要根據使用方式做不同處理
- 除錯困難——傳統的 inspector 不會顯示與物件關聯的所有資料
由於這些困難,extrinsic state 很少見,但在必要時仍然有用。
Variable#
在 Java 中,物件透過變數來引用。讀者需要了解變數的作用域 (scope)、生命週期 (lifetime)、角色 (role) 和執行期型別 (runtime type)。雖然有人發明了精心設計的命名方案來將所有資訊編碼在變數名稱中,但透過簡化程式碼並使用簡單名稱是更好的選擇。
作用域 (Scope)#
變數的作用域(可被引用的範圍)有三種類型:
| 作用域 | 說明 |
|---|---|
| Local | 只在當前作用域中可存取 |
| Field | 在物件內任何地方都可存取 |
| Static | 任何同類別的物件都可存取 |
flowchart TD
A["需要儲存狀態"] --> B{"使用範圍?"}
B -->|"單一方法內"| C["Local Variable\n區域變數"]
B -->|"整個物件"| D["Field\n欄位"]
B -->|"所有實例共享"| E["Static Field\n靜態欄位"]
C -.- C1["最小作用域\n最短生命週期"]
D -.- D1["物件作用域\n物件生命週期"]
E -.- E1["類別作用域\n程式生命週期"]欄位的作用域可透過修飾詞擴展:public、package(預設值,但卻是最少使用的——是個奇怪的預設選擇)、protected、private。
為降低耦合,你應該主要使用 local 和 field,偶爾使用 static field 和
private修飾詞。透過這有限的組合,上下文就足以告訴讀者他看到的是 local 還是 field——如果能看到宣告就是 local,看不到就是 field。這消除了在變數名稱中包含作用域資訊的需要。前提是你能將程式碼拆分成小塊,這可以透過應用其他實作模式(特別是 Composed Method)來達成。
生命週期 (Lifetime)#
變數的生命週期可以比其作用域小。例如,一個欄位可能只在某個方法在堆疊上執行時才有效——但那會很醜陋。要努力確保變數的生命週期接近其作用域,並確保同一作用域內的兄弟變數都有相同的生命週期。
型別 (Type)#
變數的型別透過型別宣告就已充分溝通。確保宣告的型別盡可能清楚地溝通(參見 Declared Type)。唯一的例外是:持有多個值(包含集合)的變數名稱應使用複數形式——單一值與多值之間的差異對讀者很重要。
當作用域、生命週期和型別都透過其他方式充分溝通後,名稱就可以用來傳達變數在計算中的角色。透過將需要傳達的資訊減到最少,你就能自由選擇簡單、易讀的名稱。
Local Variable#
區域變數只能從其宣告點存取到其作用域結束。遵循「資訊應盡可能少地擴散」的原則,在使用前才宣告區域變數,並放在最內層的可能作用域中。
區域變數有幾種常見角色:
- Collector——收集資訊以供後續使用的變數。收集器的內容通常作為函式的回傳值。當收集器將被回傳時,命名為
result或results。 - Count——一種特殊的收集器,收集某些物件的計數。
- Explaining——如果有複雜的運算式,將部分指派給區域變數可以幫助讀者理解:
int top = ...;
int left = ...;
int height = ...;
int bottom = ...;
return new Rectangle(top, left, height, width);Explaining local 雖然在計算上不是必要的,但幫助讀者理解原本會是冗長複雜的運算式。Explaining local 通常是通往 helper method 的一步——運算式變成方法的主體,區域變數的名稱暗示了方法的名稱。
- Reuse——當運算式的值會變化,但你需要多次使用同一個值時,將值儲存在區域變數中。例如,需要對多個物件使用相同的時間戳記時,不能每次重新取得:
// 錯誤:每次取得的時間不同
for (Clock each : getClocks())
each.setTime(System.currentTimeMillis());使用 reuse 區域變數來「凍結」時間:
long now = System.currentTimeMillis();
for (Clock each : getClocks())
each.setTime(now);- Element——保存正在迭代的集合元素。如上例所示,
each是元素區域變數的簡潔明瞭名稱。若想知道「each 什麼?」,只需看上方的 for 語句。對於巢狀迴圈,在元素名稱後附加集合名稱以做區分:
broadcast() {
for (Source eachSender : getSenders())
for (Destination eachReceiver : getReceivers())
...;
}Field#
欄位的作用域和生命週期與其所屬物件相同。由於欄位的首要歸屬是整個物件,應將欄位宣告集中放在類別的開頭或結尾:
- 放在開頭——宣告為讀者提供重要的上下文,用以閱讀後續程式碼
- 放在結尾——傳達「行為才是王道;資料只是實作細節」的訊息
你可以選擇將欄位宣告為 final,告訴讀者該欄位在建構子執行後不會改變。雖然作者心理上會追蹤哪些欄位是 final 哪些不是,但他個人不一定會明確宣告。不過,若程式碼會被許多人長期修改,區分 final 與 volatile 欄位就值得明確標示。
Field 的常見角色#
- Helper——持有被物件的許多方法使用的物件引用。如果某個物件被作為參數傳給許多方法,考慮將該參數替換為在完整建構子中設定的 helper 欄位。
- Flag——布林 flag 欄位表達「這個物件可以兩種不同方式行動」。如果有該 flag 的 setter 方法,則額外表達「……而且行為可以在物件的生命週期中改變」。Flag 欄位如果只用於少數幾個條件判斷則沒問題。如果基於 flag 的決策程式碼被重複,考慮改用 strategy 欄位。
- Strategy——當你想表達物件計算的某個部分有替代方式時,在欄位中儲存一個只執行可變部分計算的物件。如果此行為變異不會在物件生命週期中改變,就在完整建構子中設定 strategy 欄位;否則提供更改它的方法。
- State——State 欄位類似 strategy 欄位,部分行為委派給它。但 state 欄位在被觸發時會自行設定下一個狀態,而 strategy 欄位(如果會被改變的話)是由其他物件來更改。以這種方式實作的狀態機可能難以閱讀(因為狀態和轉換沒有在同一處表達),但對簡單的狀態機來說足夠了。
- Components——持有被引用物件「擁有」的物件或資料。
Parameter#
除了非私有變數(欄位或靜態欄位)之外,物件之間傳遞狀態的唯一方式就是透過參數 (parameter)。由於非私有變數在類別之間引入強耦合,且這種耦合傾向隨時間增長,在靜態欄位和參數都可行的所有情況下,參數都是更好的選擇。
參數引入的耦合比物件間的永久引用弱。 例如,樹狀結構內部的計算有時需要某節點的父節點。與其持有對父節點的永久引用(Figure 6.3),不如將參數傳給需要它的方法,這會削弱節點之間的耦合。沒有對父節點的永久引用,一個子樹就可以成為多棵樹的一部分。
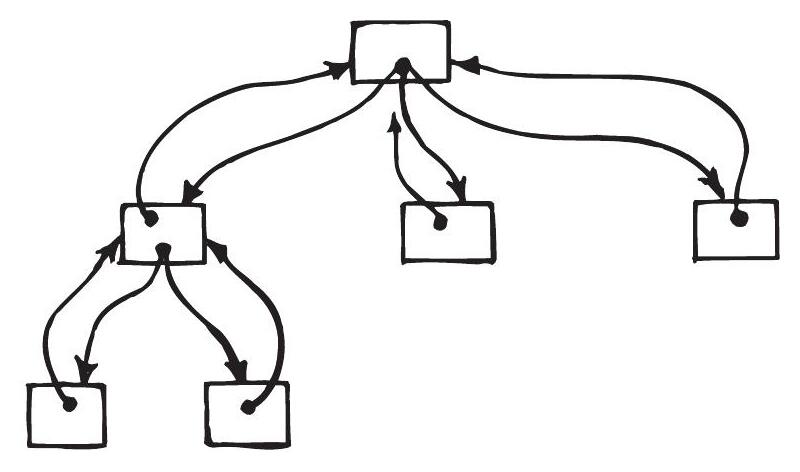
Figure 6.3: Highly coupled tree structure with parent pointers
然而,如果從一個物件到另一個物件的許多訊息都需要相同的參數,可能更好的做法是將該參數永久附加到被呼叫的物件上。參數是連結物件的細線,但就像《乘利佛遊記》中的小人國人一樣,夠多的細線可以讓一個物件無法被更改。
Figure 6.4 展示了單一參數的情況:
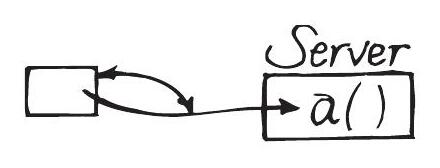
Figure 6.4: A single parameter introduces little coupling
以程式碼來說:
Server s = new Server();
s.a(this);重複相同的參數五次會大幅增加耦合:
Server s = new Server();
s.a(this);
s.b(this);
s.c(this);
s.d(this);
s.e(this);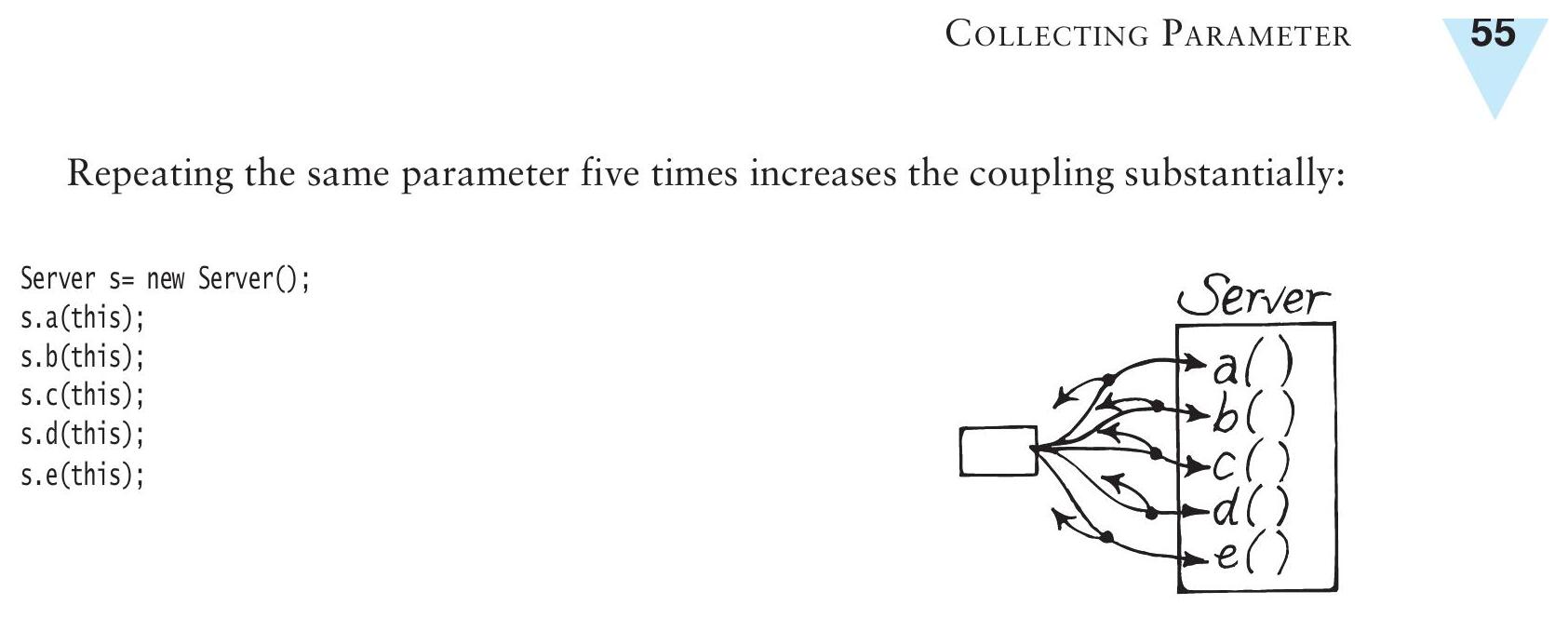
Figure 6.5: Repeated parameter increases coupling
在這種情況下,將參數替換為指標 (pointer),兩個物件就更能獨立運作:
Server s = new Server(this);
s.a();
s.b();
s.c();
s.d();
s.e();
Figure 6.6: Reference reduces coupling
Collecting Parameter#
從多個方法呼叫中收集結果的計算,需要某種方式來合併這些結果。一種方式是讓所有方法都回傳值,若值很簡單(如整數),這就行得通:
// Node
int size() {
int result = 1;
for (Node each : getChildren())
result += each.size();
return result;
}當合併結果比簡單加法更複雜時,傳入一個用來收集結果的參數會更直接。例如,將樹狀結構線性化時,collecting parameter 就很有幫助:
// Node
asList() {
List results = new ArrayList();
addTo(results);
return results;
}
addTo(List elements) {
elements.add(getValue());
for (Node each : getChildren())
each.addTo(elements);
}其他更複雜的 collecting parameter 範例:
- 在 widget 樹中傳遞的
GraphicsContext - 在 JUnit 的測試樹中傳遞的
TestResult
Optional Parameter#
有些方法可以接受參數,也可以在參數不存在時使用預設值。在這種情況下:
- 必要參數放前面
- 選擇性參數放後面
這使得盡可能多的參數保持一致,選擇性參數則作為末尾的替代選項出現。
ServerSocket 的建構子示範了 optional parameter:
public ServerSocket()
public ServerSocket(int port)
public ServerSocket(int port, int backlog)有 keyword parameter 的語言可以更直接地表達 optional parameter。由於 Java 只有位置參數 (positional parameter),參數是否為選擇性只能透過慣例來表達。有人稱此為 telescoping parameter pattern,以物理類比來描述參數集合如何層層建構。
Var Args#
有些方法可以接受任意數量的同型別參數。簡單的做法是始終傳入一個集合作為參數,但呼叫端會因中間集合的存在而變得雜亂:
Collection<String> keys = new ArrayList<String>();
keys.add(key1);
keys.add(key2);
object.index(keys);這個問題常見到 Java 提供了傳遞可變數量引數的機制。將方法宣告為 method(Class... classes) 後,客戶端可以用任意數量的引數呼叫:
object.index(key1, key2);Var args 必須是最後一個參數。如果方法同時有 var args 和 optional argument,optional argument 必須放在 var args 之前。
Parameter Object#
如果一組參數經常一起被傳遞給多個方法,考慮建立一個物件,其欄位就是那些參數,然後改為傳遞該物件。一旦用 parameter object 取代了冗長的參數列表,看看是否有只使用 parameter object 欄位的程式碼片段可以轉變為 parameter object 上的方法。
例如,Java 圖形函式庫中常以獨立的 x、y、width、height 參數表示矩形。這四個參數有時會穿過多層方法呼叫,導致程式碼比必要的更冗長、更難閱讀:
setOuterBounds(x, y, width, height);
setInnerBounds(x + 2, y + 2, width - 4, height - 4);將矩形明確化為物件能更好地解釋程式碼:
setOuterBounds(bounds);
setInnerBounds(bounds.expand(-2));引入 parameter object 的好處:
- 縮短程式碼
- 解釋意圖
- 為演算法提供歸屬——例如擴展和收縮矩形的演算法,否則必須在每個需要的地方重複(程式設計師經常忘記擴展因子需要對寬和高加倍,導致頻繁錯誤)
許多強大的物件最初都是以 parameter object 的身份誕生的。資料在多個參數列表中一起出現,是它們強烈相關的明顯線索。一個帶有固定欄位列表的類別,就是「這組資料強烈相關」的明確溝通方式。
反對 parameter object 最常見的理由是效能——分配所有那些 parameter object 需要時間。但在大多數情況下,這不會成為實際問題。如果物件分配確實成為瓶頸,可以在必要處將 parameter object 內聯 (inline),還原為明確的參數列表。最好的最佳化對象是可讀、經過分解和測試的程式碼;parameter object 有助於達成這些目標。
Constant#
有時你的程式中有多處需要但不會改變的資料值。如果這些值在編譯時已知,就儲存在宣告為 static final 的變數中,並在整個程式中引用該變數。慣例上,常數名稱使用全大寫字母以強調它們不是普通變數。
使用常數的重要性:
- 避免一整類錯誤——如果你的程式碼中散布著
5,當你決定把5改成6時,很容易漏掉某個。若5有兩個隱含意義(例如「畫邊框」和「接下來是確認封包」),更改常數就更容易出錯。 - 最強烈的理由是溝通——你可以用常數名稱來傳達值的含義。讀者理解
Color.WHITE遠比理解0xFFFFFF容易。如果顏色編碼改變了,使用常數的程式碼不需要修改。
常數的常見用途是溝通介面中訊息的變體。例如,置中文字可以呼叫 setJustification(Justification.CENTERED)。這種 API 風格的優點是可以透過新增常數來增加既有方法的新變體,而不會破壞實作者。然而,這類訊息的溝通不如為每個變體提供單獨方法來得好。以此風格,上述呼叫會變成 justifyCentered()。
如果某個方法的所有呼叫都以字面常數作為引數,可以考慮為每個常數值提供一個單獨的方法來改善介面。
Role-Suggesting Name#
如何決定變數的命名?許多相互衝突的限制影響著這個問題:
- 想透過名稱充分傳達意圖——這通常暗示使用較長的名稱
- 想讓名稱簡短以簡化程式碼格式
- 名稱被閱讀的次數遠多於被打字的次數,因此應為可讀性最佳化,而非打字的方便
理解一個變數時,需要幾項資訊:
- 它在計算中的目的是什麼?
- 變數引用的物件如何被使用?
- 變數的作用域和生命週期是什麼?
- 變數被引用的範圍有多廣?
為什麼不在名稱中編碼型別資訊#
既然已經一再告訴編譯器變數的型別,何必再將同樣的資訊嵌入變數名稱中?在不太防止型別錯誤的語言(如 C)中,包含型別資訊在名稱中可以理解。但 Java 提供了充分的型別錯誤防護,而且 IDE 能快速告訴你變數的型別。
為什麼不在名稱中編碼作用域#
有些命名慣例將作用域編碼為前綴(如 fCount 是欄位、lCount 是區域變數)。但透過撰寫相對短的 composed method,你很少會對變數的作用域感到困惑——如果在此方法中看不到宣告,它最可能是一個欄位。
用名稱傳達角色#
這就留下了變數的角色作為名稱主要要傳達的資訊,通常導向簡短、清晰的名稱。如果你掙扎於找到一個名稱,通常是因為你對計算本身理解不夠。
一些常見的變數名稱:
result——儲存將從函式回傳的物件each——在迭代時儲存集合的個別元素(也可以使用集合名稱的單數形式,例如for (Node child : getChildren()))count——儲存計數
如果有多個變數想使用相同名稱,就加以限定:eachX 和 eachY,或 rowCount 和 columnCount。
避免在變數名稱中縮寫單詞。這是以閱讀為代價來最佳化打字——由於變數被閱讀的次數遠多於被寫入的次數,這是錯誤的取捨。如果你想用多個單詞命名一個變數使其太長,看看周圍的上下文——為什麼需要這麼多單詞來區分這個變數的角色?這通常會引導你簡化設計,讓你能再次安心地寫出簡短的變數名稱。
總結:透過名稱溝通變數扮演的角色。其他所有重要的資訊——生命週期、作用域和型別——通常都能透過上下文來溝通。
Declared Type#
Java 及其他悲觀型別語言 (pessimistically typed language) 的特徵之一是需要宣告變數的型別。既然必須宣告型別,不如善用它作為溝通的機會。選擇能傳達變數如何被使用的宣告型別,而非它如何被實作。
List<Person> members = new ArrayList<Person>();這告訴我 members 將被當作 List 使用。我預期會看到像 get() 和 set() 這樣的操作,因為 List 與 Collection 的區別在於對元素的索引存取。
務實而非教條#
作者起初教條式地撰寫這個模式,嘗試了「所有變數都應盡可能宣告為通用型別」的嚴格規則。結果發現:
- 額外的泛化努力不值得
- 有時一個變數是
List,然後傳給只使用Collection協定的方法 - 宣告之間的不一致,對讀者造成的問題比精確度不足更大
盡可能以通用型別宣告變數和方法是有用的。但為了維持一致性而損失一點精確度和通用性,是合理的取捨。
泛化宣告型別最大的好處是為日後修改開啟選項。如果宣告為 ArrayList,就不能輕易改成 HashSet;但如果宣告為 Collection 就可以。一般而言,決定傳播得越遠,未來改變的彈性就越小。為維持彈性,讓盡可能少的資訊盡可能窄地傳播。
「members 包含一個 ArrayList」比「members 包含一個 Collection」傳達了更多資訊——而資訊越多,耦合越強。
專注於溝通是維持彈性的好啟發法則。 當你說一個變數持有一個 Collection,你說得精確。良好的溝通提供最佳的彈性。
Initialization#
在程式設計之前,你需要知道可以依靠什麼。能做出準確的假設有助於你專注於學習所需的知識。關於變數的狀態能做出假設是很有幫助的。初始化 (initialization) 是在使用變數之前將其置入已知狀態的過程。
初始化變數有幾個議題:
- 盡可能使初始化宣告式——如果初始化和宣告放在一起,就只有一個地方可以回答關於變數的問題
- 效能考量——初始化成本高的變數可能需要在其存在一段時間後才初始化(例如 Eclipse 中為了維持快速啟動時間,盡可能延遲載入類別)
以下是兩種初始化模式:eager 和 lazy。
Eager Initialization#
一種初始化風格是在變數一出現就初始化——無論是在宣告時,還是在其所屬物件被建立時(宣告或建構子)。
Eager initialization 的優點:你可以確保變數在使用前已被初始化。
盡可能在宣告中初始化變數,這讓宣告型別與實際型別靠在一起,方便讀者閱讀:
class Library {
List<Person> members = new ArrayList<Person>();
...
}如果無法在宣告中初始化,就在建構子中初始化:
class Point {
int x, y;
Point(int x, int y) {
this.x = x;
this.y = y;
}
}在同一處(宣告或建構子)初始化物件的所有欄位有一定的對稱性。然而,混合兩種風格似乎不會造成困擾,只要物件保持在合理的大小。
Lazy Initialization#
Eager initialization 在你不介意在變數出現時就支付計算成本的情況下運作良好。當計算成本高昂且你希望延遲支付(也許該變數永遠不會被使用)時,建立一個 getter 方法並在 getter 首次被呼叫時初始化欄位:
// Library
Collection<Person> getMembers() {
if (members == null)
members = new ArrayList<Person>();
return members;
}Lazy initialization 曾是更常見的技術,因為原始計算能力更常成為問題。在計算能力受限的環境中(如 Eclipse,啟動必須快速),lazy initialization 很重要——用來避免在使用前載入外掛程式。
Lazy initialization 的欄位比 eager initialization 的更難閱讀——讀者至少需要查看兩個地方才能理解欄位的實作型別。在寫程式時,你是在為未來的讀者儲存資訊。Lazy initialization 傳達的訊息是:「效能在這裡很重要。」
結語#
State 模式討論了如何溝通程式中狀態表示的決策。下一章將呈現另一面——如何溝通控制流程的決策。