為何需要備份#
備份是 MySQL 營運中最關鍵的任務之一。如果不在前期規劃備份策略,之後可能會發現最佳方案已經無法實施(例如事後才想用 LVM 快照,但磁碟配置已經不允許)。
備份策略的核心思維:設計備份時,要從復原的角度出發。必須定義兩個關鍵指標:
- RPO(Recovery Point Objective):可容忍的最大資料遺失量(例如最多遺失 30 分鐘的資料)
- RTO(Recovery Time Objective):可容忍的最長停機時間(例如 4 小時內必須恢復服務)
每個人都知道需要備份,但不是每個人都意識到需要的是「可復原的備份」。備份能在幾小時內完成,但復原可能需要數天甚至數週,取決於硬體、schema、索引與資料量。最糟糕的發現復原需要多久的時機,就是你真正需要復原的時候。
本書不涵蓋的面向(但同樣重要):
- 安全性(備份存取權限、加密)
- 儲存位置(異地備份策略)
- 保留政策與法規要求
- 儲存媒體與壓縮
線上備份 vs 離線備份#
書中避免使用「hot / warm / cold」這些模糊術語,因為不同人對其定義不同。改用更精確的分類:
- 線上備份(Online):伺服器持續運行,不需停機,但可能造成額外負載
- 離線備份(Offline):伺服器需要停機或限制存取
關於備份一致性,有兩個層面需要考慮:
資料一致性(Data Consistency)#
備份必須是時間點一致的。例如在電商資料庫中,發票和付款紀錄必須一致。這代表不能逐表備份,必須同時處理所有相關表。
- 非交易引擎(MyISAM):必須使用
LOCK TABLES鎖定所有相關表 - InnoDB:利用 MVCC,在
REPEATABLE READ隔離等級下開啟交易即可取得一致快照,不阻塞其他操作
-- mysqldump 的 --single-transaction 選項就是利用這個原理
-- 但注意:這會造成長時間交易,對某些工作負載可能有不可接受的額外開銷檔案一致性(File Consistency)#
每個檔案必須內部一致(不能是寫到一半的狀態),且所有檔案之間也必須一致。
- MyISAM:使用
FLUSH TABLES WITH READ LOCK將記憶體變更刷到磁碟 - InnoDB:即使執行了
FLUSH TABLES WITH READ LOCK,背景執行緒仍持續運作(insert buffer、log、write threads),因此必須確保 log 和 tablespace 檔案在同一瞬間被複製
備份方法比較#
邏輯備份(Logical Backup)#
邏輯備份分為兩種:SQL dump 和 分隔檔案(Delimited files)。
SQL Dump#
最常見的方式,mysqldump 預設輸出格式。產生包含 CREATE TABLE 和 INSERT 語句的 SQL 檔案。
缺點:
| 缺點 | 說明 |
|---|---|
| Schema 和資料混在一起 | 難以單獨還原某張表或只還原資料 |
| 巨大的 SQL 語句 | 伺服器解析和執行 SQL 語句非常慢 |
| 單一巨大檔案 | 大多數文字編輯器無法處理 |
| 效率低下 | 必須從儲存引擎取出資料再透過 client/server protocol 傳輸 |
分隔檔案(Delimited Files)#
使用 SELECT INTO OUTFILE 匯出為 CSV 等格式,再用 LOAD DATA INFILE 載入。
-- 匯出
SELECT * INTO OUTFILE '/tmp/t1.txt'
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM test.t1;
-- 匯入
LOAD DATA INFILE '/tmp/t1.txt'
INTO TABLE test.t1
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';效能比較(15M 列,約 700 MB):
| 方法 | Dump 大小 | Dump 時間 | 還原時間 |
|---|---|---|---|
| SQL dump | 727 MB | 102 秒 | 600 秒 |
| Delimited dump | 669 MB | 86 秒 | 301 秒 |
分隔檔案的還原速度約為 SQL dump 的 2 倍。對大型資料集而言,這個差異非常顯著。
SELECT INTO OUTFILE 的限制:
- 只能寫入 MySQL 伺服器所在機器的檔案系統
- MySQL 程序必須有目錄寫入權限
- 不能覆寫已存在的檔案
- 不能直接壓縮
物理備份(Raw/Physical Backup)#
直接複製資料庫的底層檔案。比邏輯備份更快,但復原靈活性較低。
檔案系統快照備份#
檔案系統快照是執行線上備份的絕佳方式。支援快照的系統包括:FreeBSD filesystem、ZFS、GNU/Linux LVM、SAN 系統、NetApp 等。
快照不等於備份。 快照使用 copy-on-write,只包含即時資料與快照時間點的差異。如果即時資料中某個未修改的 block 損毀,快照中看到的也是損毀的 block。快照只是「凍結」資料以便進行備份,但不能依賴快照本身作為備份。
LVM 快照的工作原理#
LVM 使用 copy-on-write 技術建立快照——即在某一瞬間建立整個 volume 的邏輯副本:
- 建立快照時:不複製任何資料,只記錄時間戳。讀取快照時直接從原始 volume 讀取,因此建立操作幾乎是瞬間完成的
- 原始 volume 被修改時:LVM 先將受影響的 block 複製到快照保留區(copy-on-write space),然後才寫入變更
- 只複製第一次修改:同一 block 的後續修改不再觸發複製
- 讀取快照:對已修改的 block 從保留區讀取,未修改的 block 從原始 volume 讀取
stateDiagram-v2
[*] --> Original: 建立快照(瞬間完成)
Original --> Copied: 第一次寫入觸發
Copied --> Copied: 後續寫入不再觸發複製
Original: 原始狀態
note right of Original: 讀取自 Live Volume
Copied: 已複製狀態
note right of Copied: 讀取自 CoW 保留區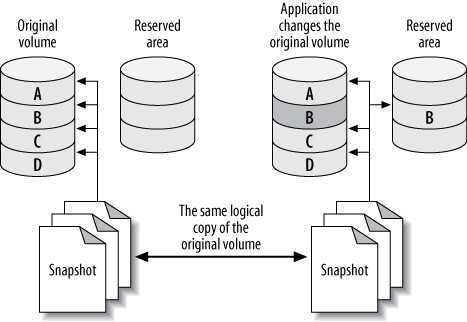
Figure 15.1: How copy-on-write technology reduces the size needed for a volume snapshot
LVM 快照操作#
前置條件:
- 所有 InnoDB 檔案(tablespace + transaction log)必須在同一個 logical volume
- 如需備份表定義,MySQL data directory 也必須在同一 volume
- Volume group 中必須有足夠的未分配空間
# 查看 volume group
vgs
# 查看 logical volumes
lvs
# 建立快照(16 GB copy-on-write 空間)
lvcreate --size 16G --snapshot --name backup_mysql /dev/vg/mysql
# 掛載快照
mkdir /tmp/backup
mount /dev/mapper/vg-backup_mysql /tmp/backup
# 監控快照使用量
watch 'lvs | grep backup'
# 完成後卸載並移除
umount /tmp/backup
rmdir /tmp/backup
lvremove --force /dev/vg/backup_mysql帶鎖的線上備份(with FLUSH TABLES WITH READ LOCK)#
-- 1. 鎖定並刷新所有表
FLUSH TABLES WITH READ LOCK;
SHOW MASTER STATUS;
-- 2. 記下 binary log 位置,保持連線不斷開# 3. 建立 LVM 快照
lvcreate --size 16G --snapshot --name backup_mysql /dev/vg/mysql-- 4. 立即釋放鎖
UNLOCK TABLES;# 5. 掛載快照,複製檔案到備份位置sequenceDiagram
participant SQL as MySQL Session
participant OS as OS Shell
SQL->>SQL: FLUSH TABLES WITH READ LOCK
SQL->>SQL: SHOW MASTER STATUS
Note over SQL: 保持連線不斷開(持有鎖)
OS->>OS: lvcreate --snapshot(建立 LVM 快照)
Note over OS: 快照瞬間完成
SQL->>SQL: UNLOCK TABLES
Note over SQL: 鎖定時間極短
OS->>OS: mount 快照
OS->>OS: 複製檔案(可慢慢來)
OS->>OS: umount 並移除快照無鎖 InnoDB 備份(Lock-free)#
如果只使用 InnoDB,可以省略 FLUSH TABLES WITH READ LOCK。InnoDB 是 ACID 系統,快照中的檔案看起來像伺服器突然斷電的狀態,但 InnoDB 的復原程序會自動處理:
- 在 transaction log 中找到已提交但尚未寫入資料檔案的交易並套用
- InnoDB 復原完成後會在 log 中印出對應的 binary log 位置
InnoDB: Last MySQL binlog file position 0 3304937, file name
/var/log/mysql/mysql-bin.000001務必驗證備份:在快照上啟動 MySQL 實例,讓 InnoDB 執行復原,檢查所有表。這既能驗證備份完整性,也能加速未來的復原(因為已經跑過復原程序)。
LVM 快照的效能影響#
- 快照會對原始 volume 和快照都造成效能影響
- 效能可能下降至 5 倍慢(取決於工作負載和檔案系統)
- 估算所需 copy-on-write 空間:
修改比例 x 每秒寫入量 x 快照保持時間
Binary Log 管理與備份#
Binary log 是備份中最重要的元素之一,它是實現**時間點復原(Point-in-Time Recovery)**的關鍵。
為何 Binary Log 如此重要#
- 如果有某個時間點的完整備份加上之後的所有 binary log,就能透過重放 binary log 復原到任意時間點
- Binary log 也用於 replication,因此備份策略常與 replication 配置交互影響
最佳實務:
- 將 binary log 存放在獨立的 volume
- 頻繁備份 binary log(如 RPO 為 30 分鐘,至少每 30 分鐘備份一次)
- MySQL 5.6 的
mysqlbinlog支援即時鏡像 binary log
Binary Log 格式#
每個事件包含固定大小的 header:
# at 277
#071030 10:47:21 server id 3 end_log_pos 369 Query thread_id=13 exec_time=0
error_code=0
SET TIMESTAMP=1193755641/*!*/;
insert into test(a) values(2)/*!*/;若使用 row-based logging(MySQL 5.1+),事件不是 SQL 語句,而是不可讀的「image」,記錄的是行級修改。
安全清除舊 Binary Log#
-- 正確方式:使用 PURGE 命令
PURGE MASTER LOGS BEFORE CURRENT_DATE - INTERVAL N DAY;# 或設定自動過期
# my.cnf: expire_logs_days = N絕對不要用
rm刪除 binary log! 這會導致mysql-bin.index與磁碟檔案不同步,SHOW MASTER LOGS等命令會靜默失敗。
從 Replica 備份#
從 replica 備份的最大優勢是不影響 master 的效能,即使不需要 replica 做負載平衡或高可用,這也是建立 replica 的好理由。
關鍵注意事項:
- 備份時保存所有 replication 資訊(replica 相對於 master 的位置)
- 確保停止 replica 時沒有開啟的 temporary table
- **延遲 replication(Delayed Replica)**非常有用:例如延遲 1 小時,若 master 上發生意外操作,有 1 小時的窗口可以在 replica 上阻止
Replication 不是備份。 Replica 的資料可能與 master 不一致(這比想像中更常見)。MySQL 沒有內建方法偵測此問題,唯一的方式是使用
pt-table-checksum。RAID、SAN、快照也都不是備份。
從備份復原#
復原的一般流程#
- 停止 MySQL 伺服器
- 記錄伺服器配置與檔案權限
- 將備份資料移入 MySQL data directory
- 修改配置(如有需要)
- 修正檔案權限(確保
mysql使用者和群組擁有正確權限) - 以限制存取模式重啟伺服器
- 載入邏輯備份檔案
- 檢查並重放 binary log
- 驗證還原結果
- 以正常模式重啟伺服器
flowchart TD
A["1. 停止 MySQL"] --> B["2. 記錄配置與權限"]
B --> C["3. 搬入備份資料"]
C --> D["4. 修改配置"]
D --> E["5. 修正檔案權限"]
E --> F["6. 限制存取模式重啟"]
F --> G["7. 載入邏輯備份"]
G --> H["8. 重放 Binary Log"]
H --> I["9. 驗證還原結果"]
I --> J["10. 正常重啟,開放存取"]
style F fill:#ffa,stroke:#333
style I fill:#ffa,stroke:#333復原期間,使用
--skip-networking和--socket=/tmp/mysql_recover.sock啟動 MySQL,確保應用程式無法連入,直到復原完成並驗證。
還原物理備份(Raw Files)#
| 引擎 | 還原方式 | 注意事項 |
|---|---|---|
| MyISAM | 直接複製 .frm、.MYI、.MYD 檔案 | 伺服器運行中也能操作 |
| InnoDB(共用 tablespace) | 停止 MySQL,複製檔案後重啟 | Transaction log 必須與 tablespace 檔案匹配 |
| InnoDB(file-per-table) | 還原個別 .ibd 檔案,使用 ALTER TABLE ... IMPORT TABLESPACE | 有諸多限制 |
啟動前務必:
- 檢查檔案的 owner 和 permissions
- 監控 error log:
tail -f /var/log/mysql/mysql.err - 啟動後執行
SHOW TABLE STATUS檢查每個資料庫
還原邏輯備份#
載入 SQL 檔案#
# 基本還原
mysql < sakila-backup.sql
# 壓縮檔直接還原(不要先解壓再載入!)
gunzip -c sakila-backup.sql.gz | mysql
# 從壓縮備份中還原單張表
gunzip -c sakila-backup.sql.gz | grep 'INSERT INTO `actor`' | mysql sakila-- 在 MySQL 內部還原(可關閉 binary logging)
SET SQL_LOG_BIN = 0;
SOURCE sakila-backup.sql;
SET SQL_LOG_BIN = 1;載入分隔檔案#
# 使用 named pipe 避免解壓到磁碟
mkfifo /tmp/backup/payment.fifo
chmod 666 /tmp/backup/payment.fifo
gunzip -c payment.txt.gz > /tmp/backup/payment.fifoSET SQL_LOG_BIN = 0;
LOAD DATA INFILE '/tmp/backup/payment.fifo'
INTO TABLE sakila.payment;使用 named pipe(FIFO) 可以避免先解壓到磁碟再載入,直接串流解壓資料進 MySQL,大幅減少 I/O 和所需磁碟空間。
時間點復原(Point-in-Time Recovery)#
最常見的做法是還原最近的完整備份,然後重放 binary log(roll-forward recovery)。
範例:復原被誤刪的表
# 1. 停止 MySQL,還原備份
/etc/init.d/mysql stop
mv /var/lib/mysql/sakila /var/lib/mysql/sakila.tmp
cp -a /backup/sakila /var/lib/mysql
# 2. 設定限制存取模式後啟動
# my.cnf 加入: skip-networking 和 socket=/tmp/mysql_recover.sock
/etc/init.d/mysql start
# 3. 找到誤操作的 binary log 位置
mysqlbinlog --database=sakila /var/log/mysql/mysql-bin.000215 \
| grep -B3 -i 'drop table sakila.payment'
# 輸出: # at 352 ... end_log_pos 429
# 4. 重放 binary log,跳過誤操作
mysqlbinlog --database=sakila /var/log/mysql/mysql-bin.000215 \
--stop-position=352 | mysql -uroot -p
mysqlbinlog --database=sakila /var/log/mysql/mysql-bin.000215 \
--start-position=429 | mysql -uroot -pflowchart LR
A["備份時間點"] -->|"正常事件重放"| B["Position 352"]
B -->|"跳過 DROP TABLE"| C["Position 429"]
C -->|"繼續重放"| D["現在時間"]
style B fill:#fbb,stroke:#333
style C fill:#bfb,stroke:#333Binary log 重放速度約等於 replication 速度。若 SQL thread 約 50% 利用率,復原一週的 binary log 可能需要 3~4 天。
進階復原技術#
延遲 Replica 快速復原#
若有延遲 replica,且在 replica 執行到誤操作之前發現問題:
- 停止 replica
- 用
START SLAVE UNTIL重放到誤操作之前的位置 - 用
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1跳過錯誤語句 - 執行
START SLAVE讓 replica 跑完剩餘 relay log - 將 replica 提升為 master
使用 Log Server 復原#
Replication 比 mysqlbinlog 更可靠,可利用 log server 進行更精確的復原:
- 將備份還原到另一台伺服器(server2)
- 設定 log server 提供原始伺服器的 binary log
- 在 server2 設定
replicate-do-table=sakila.payment只復原特定表 - 讓 server2 成為 log server 的 replica,用
START SLAVE UNTIL重放到目標位置 - 從 server2 複製還原好的表回原始伺服器
sequenceDiagram
participant Orig as 原始伺服器
participant LS as Log Server
participant S2 as Server2
Note over S2: 還原備份到 Server2
S2->>LS: 設定為 Log Server 的 Replica
Note over S2: 設定 replicate-do-table 過濾
LS-->>S2: 傳送 Binary Log 事件
S2->>S2: START SLAVE UNTIL 目標位置
S2->>S2: 重放完成
S2-->>Orig: 複製還原好的表回原始伺服器InnoDB 損毀復原#
損毀的常見原因#
| 原因 | 說明 |
|---|---|
| 硬體問題 | 電源故障、記憶體損毀 |
| 硬體設定錯誤(最常見) | 未配備電池的 RAID 卡啟用了 writeback cache、硬碟啟用了 writeback cache |
| NAS 儲存 | fsync() 完成只代表裝置收到資料,不保證資料已安全寫入 |
三種損毀類型與復原方式#
| 損毀類型 | 嚴重程度 | 復原方式 |
|---|---|---|
| Secondary index 損毀 | 低 | OPTIMIZE TABLE 或 dump/reload 重建 |
| Clustered index 損毀 | 中 | 可能需要 innodb_force_recovery 匯出資料 |
| System structures 損毀 | 高 | 通常需要完整 dump 和 restore |
innodb_force_recovery 參數:
- 正常值為 0
- 值 1~4:相對安全,只是放寬完整性檢查,不會傷害資料
- 值 5~6:更激進地嘗試修復,但可能造成進一步損毀
若 InnoDB 損毀到完全無法啟動 MySQL,可使用 Percona 的 InnoDB Recovery Toolkit 直接從檔案中提取資料。
備份工具比較#
| 工具 | 推薦度 | 說明 |
|---|---|---|
| Percona XtraBackup | 推薦 | 物理備份(開源免費)。熱備份、串流/增量/壓縮/多執行緒、不需連接 MySQL |
| MySQL Enterprise Backup | 推薦 | 物理備份(商業授權)。前身為 InnoDB Hot Backup,Oracle 官方工具 |
| mylvmbackup | 推薦 | LVM 快照備份。Perl 腳本自動化 LVM 快照流程 |
| ZRM(Zmanda Recovery Manager) | 推薦 | 備份與復原管理器,整合 mysqldump、LVM snapshot、XtraBackup |
| mydumper | 推薦 | 多執行緒邏輯備份工具,備份和還原速度遠快於 mysqldump |
| mysqldump | 不推薦 | 不建議用於大量資料備份,對伺服器影響大,還原時間不可預測 |
| mysqlhotcopy | 不推薦 | 舊工具,只對 MyISAM 有效,對 InnoDB 不安全 |
| mk-parallel-dump / mk-parallel-restore | 不推薦 | 已知不安全 |
Percona XtraBackup 工作原理#
- 背景執行緒持續「tailing」InnoDB log 檔案
- 同時複製 InnoDB 資料檔案(各檔案可能處於不同時間點)
- 資料檔案複製完成後停止 log 複製
- Prepare 階段:將 log 套用到資料檔案(利用 InnoDB crash recovery 機制),使所有檔案達到一致狀態
- 整個過程完全在 MySQL 外部執行
sequenceDiagram
participant XT as XtraBackup
participant Log as InnoDB Log
participant Data as InnoDB Data Files
par 並行作業
XT->>Log: 持續 tailing InnoDB log
and
XT->>Data: 複製 InnoDB 資料檔案
end
Note over XT: 資料檔案複製完成
XT->>Log: 停止 log tailing
XT->>XT: Prepare 階段:套用 log 到資料檔案
Note over XT: 利用 InnoDB crash recovery 機制備份腳本建構要素#
撰寫備份腳本的關鍵步驟(依執行順序):
- 嚴格錯誤檢查
set -u # 未定義變數時報錯
set -e # 程式執行錯誤時中止- 取得資料庫與表清單(注意過濾
INFORMATION_SCHEMA、lost+found) - 鎖定與刷新表
FLUSH TABLES WITH READ LOCK;- 刷新 binary log(鎖定後、備份前)
FLUSH LOGS;- 記錄 binary log 位置
SHOW MASTER STATUS\G
SHOW SLAVE STATUS\G- 匯出資料(mysqldump / mydumper /
SELECT INTO OUTFILE) - 複製資料到備份位置
- 釋放鎖
mysqldump 常用選項#
# 完整伺服器備份(InnoDB,包含 binary log 位置)
mysqldump --all-databases \
--single-transaction \
--master-data \
--opt \
--tz-utc \
--quote-names \
--result-file=dump.sql重要選項說明:
| 選項 | 說明 |
|---|---|
--single-transaction | 利用 InnoDB MVCC 取得一致快照,不需 LOCK TABLES |
--master-data | 記錄 binary log 座標(但會短暫使用 FLUSH TABLES WITH READ LOCK) |
--opt | 停用緩衝(防止記憶體不足)、最佳化 INSERT 語句 |
--lock-all-tables | 跨資料庫全域一致備份 |
--tab | 使用 SELECT INTO OUTFILE 匯出分隔檔案 |
--skip-extended-insert | 每列一個 INSERT(方便挑選特定列還原,但檔案更大、匯入更慢) |
備份策略建議#
定期測試復原,確保備份可用。 最好的做法是每天將備份還原到開發或 staging 伺服器,一石二鳥:既驗證備份,又更新開發環境。
書中推薦的備份策略核心:
- 使用 Percona XtraBackup 或檔案系統 / SAN 快照進行非侵入式物理備份
- 從還原的備份再匯出一份邏輯備份作為額外保障
- 頻繁備份 binary log
- 保留足夠世代的備份和 binary log,即使最新備份損毀也能復原
- 從 replica 備份以減少對 master 的影響
- 用
pt-table-checksum驗證 replication 完整性 - 備份必須通過
DROP TABLE測試(模擬誤操作)和資料中心遺失測試