概觀#
當 MySQL 已被高度最佳化,僅佔使用者所感受到的回應時間中極小的比例時,就該把焦點轉移到應用層面。效能瓶頸不一定在資料庫——透過 分層剖析(per-tier profiling) 才能可靠地找到真正的問題來源。有時即使問題出在 MySQL,從系統其他部分解決反而更容易。
工具推薦:前端可用 Firebug / YSlow 進行剖析,後端可用 New Relic 做全棧效能分析。先量測,再最佳化。
常見問題清單#
以下是應用層經常出現的效能問題:
資源使用#
- CPU / 磁碟 / 網路 / 記憶體 的使用量是否合理?例如 Apache 建立 1,000 個 worker process、每個耗用 50 MB 記憶體,可透過設定減少 worker 數量或降低單一 process 記憶體用量
- 應用程式是否取得了多餘的資料?例如查詢 1,000 筆但只顯示 10 筆(除非刻意快取其餘資料)
查詢與處理分工#
- 應用層 vs 資料庫的分工是否正確? 資料庫擅長計數(
COUNT),應用語言擅長正規表達式——用對的工具做對的事 - 查詢太多? ORM 產生的巢狀迴圈查詢應改寫為 JOIN
- 查詢太少? 有時「手動 JOIN」在應用層執行反而能獲得更細緻的快取、更少的鎖定,甚至比 MySQL 的 nested loop join 更快
連線管理#
- 不必要的連線:如果資料可從快取取得,就不應連線 MySQL
- 重複連線:應用程式不同模組各自開連線,應改為共用同一連線
- 垃圾查詢:連線前 ping、每次查詢前
SELECT DATABASE()、SET NAMES UTF8(此為錯誤做法,不會改變 client library 的字元集)、Java driver 的過度連線準備 - 連線池(Connection Pool):限制連線數有好處(特別是 Ajax 應用),但要注意 transaction、暫存表、連線設定等副作用
- 持久連線(Persistent Connections):通常是壞主意,除非網路延遲高、查詢極短、或 client 端 port 不足。設定
skip-name-resolve、足夠的thread_cache、提高back_log可減少連線成本 - 閒置連線佔用:連線到多台 MySQL 時,多數連線處於
Sleep狀態。應批次操作並在完成後關閉連線
持久連線 vs 連線池的差異:持久連線是 per-process 建立,無法跨 process 共享;連線池則將連線排隊共享,通常產生較少的伺服器連線數,且可設定佇列策略避免 MySQL 過載。
Web 伺服器議題#
Apache 的問題#
Apache 搭配 mod_php / mod_perl / mod_python 的 prefork 模式下,每個 process 可能耗用 50-100 MB 記憶體。當請求結束後 process 不會釋放全部記憶體,再被分配去處理靜態檔案時就造成資源浪費。另外兩個主要問題:
- Keep-Alive:長時間保持 fat Apache process 存活
- Spoon-feeding:client 端下載速度慢導致 process 長時間佔用(也讓 DoS 攻擊變得容易)
最佳化策略#
- 靜態內容分離:使用 Nginx 或 lighttpd 處理靜態檔案,不要用 Apache
- 快取代理伺服器:使用 Squid 或 Varnish 攔截請求,搭配 ESI(Edge Side Includes) 將動態片段嵌入快取的靜態頁面
- 設定內容過期策略:為動態和靜態內容設定過期時間,並透過檔案版本化(如
/css/123_frontpage.css)避免快取失效造成頁面破版 - 使用反向代理處理 Keep-Alive:讓 proxy 面對 client 處理 Keep-Alive,Apache 只與 proxy 之間保持少量連線,快速完成請求後釋放 process
- 啟用 gzip 壓縮:對現代 CPU 成本極低,節省大量流量
- 精簡 Apache 模組:移除不需要的模組以減少記憶體足跡
flowchart LR
C["Client"] --> Proxy["反向代理\nNginx / Varnish"]
Proxy -->|"靜態內容"| Static["直接回應"]
Proxy -->|"動態內容"| Apache["Apache"]
Apache --> MySQL["MySQL"]
Apache --> MC["Memcached"]
subgraph note [" "]
direction LR
N1["Keep-Alive 僅在 Client ↔ Proxy 之間"]
end
style note fill:#fff3cd,stroke:#ffc107
style N1 fill:#fff3cd,stroke:none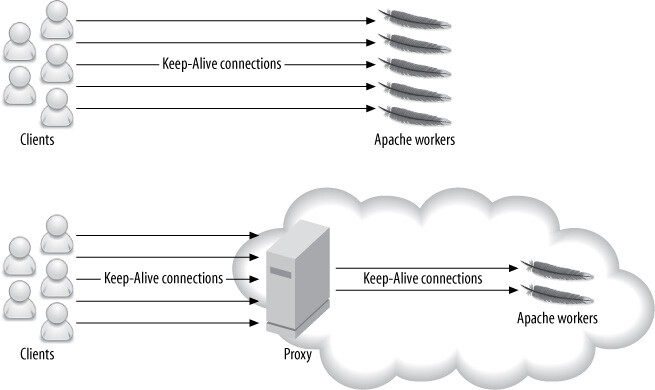
Figure 14.1: A proxy can shield Apache from long-lived Keep-Alive connections
最佳並行數(Optimal Concurrency)#
每個 Web 伺服器都有一個最佳並行連線數——超過此數後,吞吐量趨於平穩甚至下降,而回應時間(延遲)因排隊而增加。
- CPU-bound 工作負載:最佳並行數 = CPU 核心數
- 實際情況:process 會執行 I/O、資料庫查詢、網路請求等阻塞操作,因此最佳並行數通常高於 CPU 核心數
- 可使用 Percona Toolkit 的 pt-tcp-model 工具從 TCP dump 量測和建模系統的可擴展性
以單一 CPU 處理 100 個需要 1 秒 CPU 時間的請求為例:排隊處理(concurrency=1)的平均延遲為 50 秒,而平行處理(concurrency=100)的平均延遲為 100 秒。吞吐量相同,但延遲差距顯著。
快取策略#
快取對高負載應用至關重要,通常能帶來數量級的效能改善。關鍵在於找到正確的粒度(granularity)和過期策略(expiration policy)。
被動快取 vs 主動快取#
| 類型 | 行為 | 範例 |
|---|---|---|
| 被動快取(Passive Cache) | 僅儲存與返回資料;miss 時回傳「不存在」 | memcached |
| 主動快取(Active Cache) | miss 時自動將請求轉發給後端產生結果,然後儲存並返回 | Squid proxy |
設計應用時通常偏好主動(透明)快取,因為它隱藏了 check-generate-store 邏輯。可在被動快取之上建構主動快取。
快取不一定有幫助#
快取本身有開銷:檢查快取、命中時取出資料、未命中時產生並儲存資料。只有當這些成本低於直接產生資料的成本時,快取才有意義。
快取成本 = 檢查成本 + (miss 機率 × 產生成本) + (hit 機率 × 快取取出成本)
無快取成本 = 每次請求的產生成本例如:從 Nginx 記憶體直接 serve 通常比從 proxy 的磁碟快取 serve 更快。
應用層快取的四種類型#
Local Cache(本地快取)
- 存在於 process 記憶體中,僅限於單次請求的生命週期
- 實作為變數或 hash table,避免重複查詢同一資源
<?php
function get_name_from_id($user_id) {
static $name; // static makes the variable persist
if ( !$name ) {
// Fetch name from database
}
return $name;
}
?>
Local Shared-Memory Cache(本地共享記憶體快取)
- 容量中等(數 GB),存取速度極快
- 適合半靜態的小型資料(城市列表、分片映射表等)
- 難以跨多台機器同步
Distributed Memory Cache(分散式記憶體快取)
- 代表:memcached
- 容量大、易擴展,每筆資料只存一份避免一致性問題
- 延遲較高,應使用 multi-get 操作降低網路往返次數
- 新增或移除節點時需使用 consistent hashing 避免效能衝擊
On-Disk Cache(磁碟快取)
- 適合持久性物件、無法放入記憶體的物件、靜態內容
- 404 error handler 技巧:將快取 miss 導向 error handler 產生內容、寫入磁碟,後續請求直接從檔案系統取得
- 失效策略:刪除檔案即可;TTL 可透過定期刪除超過 N 分鐘的檔案;LRU 可依最後存取時間刪除(需啟用檔案系統的 atime)
flowchart TD
A["請求"] --> B{"Local Cache\n命中?"}
B -->|命中| Z["回傳資料"]
B -->|未命中| C{"Shared Memory Cache\n命中?"}
C -->|命中| Z
C -->|未命中| D{"Distributed Cache\n命中?"}
D -->|命中| Z
D -->|未命中| E{"On-Disk Cache\n命中?"}
E -->|命中| Z
E -->|未命中| F["查詢 MySQL"]
F --> Z快取控制策略#
| 策略 | 機制 | 適用情境 |
|---|---|---|
| TTL(Time to Live) | 設定過期時間,到期後由 purge process 移除或下次存取時替換 | 變更不頻繁或不需即時更新的資料 |
| Explicit Invalidation(顯式失效) | Write-invalidate:更新來源資料時標記快取為過期;Write-update:更新來源資料時同步更新快取內容。可在背景執行失效與重新產生 | 需要即時反映資料變更的場景 |
| Invalidation on Read(讀取時失效) | 讀取快取時才檢查資料是否過期,將失效成本分散到多次讀取中 | 需避免一次大量失效造成延遲高峰的場景 |
物件版本化(Object Versioning) 是一種簡單的 read-based invalidation 實作。快取物件時一併儲存其依賴資料的版本號。讀取時比較版本號,若依賴的版本號更大,表示快取已過期。這是 Tagged Cache 的簡化版——tagged cache 可追蹤多種依賴的版本號。
快取物件階層#
以電商搜尋結果為例,不要快取完整的搜尋結果列表,而是:
- 快取搜尋結果的產品 ID 清單(最小化資訊)
- 分別快取每個產品物件
好處:
- 不重複儲存相同產品資料
- 單一產品變更時可精確失效
- 使用 memcached 的
mget()一次取回多個產品物件
flowchart TD
A["搜尋請求"] --> B["查詢搜尋結果快取"]
B --> C["取得產品 ID 清單"]
C --> D["mget 批次查詢產品物件快取"]
D --> E{"全部命中?"}
E -->|是| G["組裝結果回傳"]
E -->|部分未命中| F["查詢 MySQL 取得缺失物件"]
F --> F2["回填快取"]
F2 --> G小心快取一致性問題:若搜尋結果用 TTL 失效、產品用顯式失效,當產品描述改變而搜尋結果尚未過期時,使用者會看到過時的搜尋結果。可透過版本化快取解決。
遠端快取存取的網路往返約 0.3 毫秒。一個複雜的網頁可能需要上千次快取存取,累計就是 3 秒延遲。Multi-get 和本地快取階層在此情境至關重要。
預先產生內容(Pregenerating Content)#
透過背景 process 預先請求頁面並儲存為靜態檔案,或預先產生頁面片段搭配 SSI(Server-Side Includes) 組裝。
主要好處:
- 應用程式碼不需處理 hit/miss 兩條路徑
- 避免 miss path 過慢的問題——確保 miss 永遠不會發生
- 避免快取 miss 時的驚群效應(thundering herd / cache stampede)
sequenceDiagram
participant BG as 背景程序
participant App as 應用伺服器
participant FS as 靜態檔案
participant User as 使用者
participant Web as Web 伺服器
rect rgb(230, 245, 255)
Note over BG,FS: 預熱階段
BG->>App: 請求頁面
App-->>BG: 產生頁面內容
BG->>FS: 儲存為靜態檔案
end
rect rgb(230, 255, 230)
Note over User,Web: 實際請求階段
User->>Web: 請求頁面
Web->>FS: 讀取靜態檔案
FS-->>Web: 回傳內容
Web-->>User: 回傳(不需經過 App Server)
end設計快取時務必考慮 miss path 的延遲。如果平均效能提升很多但偶發請求極慢,可能比不用快取更糟。一致的效能通常與快速的效能同等重要。
快取作為基礎設施元件#
快取可能在不知不覺中成為不可或缺的基礎設施。例如快取命中率 90% 時,若快取失效,資料庫負載會增加 10 倍——很可能超出資料庫容量。
建議措施:
- 為快取設計高可用方案
- 量測停用快取的效能影響
- 設計應用的功能降級(graceful degradation) 機制
繞過 SQL 的存取路徑#
對於簡單的小型查詢,SQL 解析、權限檢查、執行計畫產生等開銷可能佔很大比例。兩種 NoSQL 存取 MySQL 的方案:
HandlerSocket
- 由日本社群網站 DeNA 開發的 daemon plugin
- 繞過 MySQL 上層直接存取 InnoDB Handler 物件
- 報告顯示可達到超過 750,000 QPS
- 隨 Percona Server 發佈
memcached Protocol Access
- MySQL 5.6 lab release 提供的 plugin
- 透過 memcached 協定存取 InnoDB
- 支援的存取方法較 HandlerSocket 少
這兩種方案最大的好處是簡化架構——不再需要外部快取層及其伴隨的失效邏輯和額外基礎設施。
延伸與替代 MySQL#
延伸 MySQL#
- 自訂 Storage Engine:Brian Aker 編寫了 skeleton storage engine 範本。許多公司為特殊需求(社交圖譜、模糊搜尋)建立自訂引擎
- Sphinx Storage Engine:作為 MySQL 與 Sphinx 全文搜尋之間的介面
MySQL 的替代方案#
某些工作完全在 MySQL 之外處理會更好:
| 替代方案 | 適用場景 |
|---|---|
| 檔案系統 | 圖片等大型二進位檔存在檔案系統中,MySQL 只存檔名。在 web 應用中透過 <img src="..."> 取得 |
| 全文搜尋(Lucene / Sphinx) | 表現遠優於 MySQL 內建的全文搜尋 |
| NDB API | 繞過 SQL 層直接操作 NDB Cluster,適合 session 儲存和用戶註冊資料。另有 Apache 模組 mod_ndb |
| Redis | 適合高寫入量的 key-value 資料(MySQL replica 跟不上時的替代方案),也因其佇列操作支援而被廣泛使用 |
| Hadoop | 混合 MySQL/Hadoop 部署常用於處理大型或半結構化資料集 |
| 圖形資料庫 | 圖關係和樹狀遍歷不適合關聯式資料庫範式 |
本章小結#
- 先量測:使用分層剖析(per-tier profiling)找出真正的瓶頸。如果使用者體驗主要受限於瀏覽器端 DOM rendering,再怎麼最佳化 MySQL 查詢也無濟於事
- Web 伺服器是常見的低垂果實——Apache 的設定、靜態/動態內容分離、反向代理都能帶來顯著改善
- 快取能以遠低於 MySQL 的成本交付大量內容——選擇正確的快取類型、粒度和失效策略是關鍵
- 不是所有問題都需要 MySQL 解決——善用 Sphinx、Redis、Hadoop 等工具處理各自擅長的工作