什麼是高可用性#
高可用性(High Availability, HA)的本質就是「減少停機時間」。它通常以百分比表示,暗示著不存在絕對的高可用——只有相對更高的可用性。100% 的可用性是不可能的。
可用性的量化:Nines 規則#
業界常用「幾個九」(nines)來衡量可用性目標:
| 可用性等級 | 年停機時間 |
|---|---|
| 99%(2 nines) | ~3.65 天 |
| 99.9%(3 nines) | ~8.76 小時 |
| 99.99%(4 nines) | ~52.6 分鐘 |
| 99.999%(5 nines) | ~5.26 分鐘 |
每增加一個九的可用性,所需成本與努力呈非線性增長。在設定目標前,先評估停機成本與降低停機的成本之間的平衡。
可用性的定義不僅是「伺服器在跑」#
可用性應包含服務是否以良好效能回應請求。例如 MySQL 重啟後,大型伺服器可能需要數小時暖機(warm up)才能提供可接受的回應時間——此時雖然伺服器在跑,但並不算真正可用。
降低可用性需求的策略#
- 分離關鍵與非關鍵元件:對較小的關鍵子系統實現高可用,成本遠低於對整個系統
- 計算風險暴露值(Risk Exposure)= 故障機率 x 故障成本,用以排定優先順序
導致停機的原因#
根據 Percona 對客戶事件資料庫的分析,停機事件按表現形式分為四大類:
| 類別 | 佔比 | 最常見原因 |
|---|---|---|
| 運作環境(OS、磁碟、網路) | ~35% | 磁碟空間耗盡 |
| 效能問題 | ~35% | 不良 SQL 執行、schema/索引設計不佳 |
| 複製問題 | ~20% | 主從資料不一致 |
| 資料遺失/損毀 | ~10% | DROP TABLE + 缺少可用備份 |
複製(replication)本身是用來提升可用性的手段,卻也經常反過來造成停機——通常是因為使用不當。許多高可用策略都可能適得其反。
實現高可用的兩大方向#
高可用透過兩個實踐來達成,兩者應並行:
- 提升 MTBF(Mean Time Between Failures):預防停機發生
- 降低 MTTR(Mean Time to Recovery):確保停機發生時能快速恢復
flowchart TD
HA["高可用 HA"] --> MTBF["提升 MTBF(預防故障)"]
HA --> MTTR["降低 MTTR(快速恢復)"]
MTBF --> B1["定期備份"]
MTBF --> B2["完善系統管理"]
MTBF --> B3["持續監控"]
MTTR --> R1["訓練有素的人員"]
MTTR --> R2["自動故障轉移機制"]
MTTR --> R3["標準化操作程序"]提升 MTBF:預防勝於治療#
根據 Percona 的分析,大多數停機事件可透過常識性的系統管理來避免。核心建議包括:
備份與測試
- 測試恢復工具與流程,包括從備份還原
- 定期驗證備份的可還原性
系統管理
- 遵循最小權限原則
- 保持系統整潔,使用清晰的命名慣例(區分開發/正式環境)
- 按合理排程升級資料庫,升級前用
pt-upgrade測試
MySQL 設定
- 使用 InnoDB 並設為預設儲存引擎
- 用
skip_name_resolve停用 DNS - 停用 Query Cache(除非已證明有效益)
- 避免不必要的複雜性(replication filters、triggers 等)
監控與維護
- 監控關鍵項目(磁碟空間、RAID 狀態),避免誤報
- 盡可能記錄歷史指標,永久保留
- 定期驗證複製完整性
- 設定從庫為唯讀,不讓複製自動啟動
- 定期進行查詢審查
- 歸檔並清除不需要的資料
- 在檔案系統中預留空間(使用
mke2fs -m、LVM 空間、或建立可刪除的 dummy 檔案)
系統變更管理的疏失是導致停機事件的最重要原因——草率升級、未經測試的 schema 變更、未規劃磁碟容量等。
降低 MTTR:快速恢復#
降低 MTTR 不僅是技術問題,更有人員與組織的面向:
- 人員是最重要的高可用資產:良好的恢復程序、訓練有素的團隊比純技術方案更可靠
- 工具和系統無法理解細微情境,有時會做出在一般情況下正確、但在你的場景中災難性的事
- 審查停機事件有助於組織學習,但要注意事後諸葛亮的偏誤——避免過度追求「單一根因」
所有停機事件都是由多個故障的組合造成的,因此只要任何一個安全機制正常運作,就能避免事件發生。需要修復的是整條故障鏈,而非僅僅單一環節。
避免單點故障#
找出並消除系統中的單點故障(Single Points of Failure),配合切換到備用元件的機制,是降低 MTTR 的方法之一。
需要檢視的常見單點故障:
- 硬碟、伺服器、交換器/路由器、單一機架的電源
- 所有機器是否在同一資料中心
- DNS、單一網路供應商、單一雲端可用區、單一電力網格
增加冗餘有兩種形式:增加備用容量(如伺服器池 + 負載均衡)和複製元件(如備用伺服器)。複製整台 MySQL 伺服器比較困難,因為伺服器沒有資料就毫無用處——必須確保備用伺服器能存取主伺服器的資料。
共享儲存(SAN)#
共享儲存將資料庫伺服器與儲存解耦。主伺服器掛掉時,備用伺服器可掛載相同的檔案系統,執行必要的恢復操作後啟動 MySQL。
| 面向 | 說明 |
|---|---|
| 優點 | 非儲存元件的故障不會造成資料遺失 |
| 優點 | 可以對非儲存元件建立冗餘 |
| 缺點 | 共享儲存本身仍是單點故障——SAN 可以且確實會故障 |
| 缺點 | MySQL 不支援多實例同時以 active-active 模式存取同一份資料 |
| 缺點 | 若 crash 導致資料檔案損壞,備用伺服器也無法恢復 |
強烈建議搭配共享儲存使用 InnoDB(而非 MyISAM)和日誌式檔案系統(journaling filesystem)。MyISAM 在 crash 後幾乎必然損壞,修復耗時且可能丟失資料列。
磁碟複製(DRBD)#
DRBD(Distributed Replicated Block Device)是 Linux 核心模組實作的同步區塊層級複製。它將主設備的每個區塊透過網路複製到另一台伺服器的區塊設備,且在主設備確認寫入前,必須先完成對端的寫入。
關鍵特性:
- 可防止 split-brain 症候群(兩個節點同時升為主節點)
- 內建 failback 能力
- 建立了資料冗餘——儲存與資料本身都不是單點故障
缺點:
- 故障轉移不是亞秒級,通常至少需數秒(不含檔案系統與 MySQL 恢復時間)
- 必須以 active-passive 模式運行,備用伺服器的複製設備不能用於其他用途
- 對 MyISAM 幾乎無法使用(檢查與修復太慢)
- 不能取代備份——惡意操作、bug、硬體錯誤造成的資料損壞會被完美複製
- 寫入延遲增加(網路往返 ~0.3ms,對大量短寫入和
fsync()影響顯著)
作者最推薦的 DRBD 使用方式:只複製存放 binary log 的設備。若主節點故障,可在被動節點啟動 log server,用恢復的 binary log 將所有從庫同步到最新位置,再選一個從庫升為主庫。
總結: 共享儲存與磁碟複製更多是保護資料安全的方案,而非低停機時間方案。與備用伺服器隨時在線的架構相比,它們的 MTTR 通常更高。
同步 MySQL 複製#
在同步複製中,交易在主庫上無法完成,直到它在一個或多個從庫上也提交為止。這實現兩個目標:
- 伺服器 crash 不會遺失已提交的交易
- 至少有一台伺服器擁有「活」的資料副本
大多數同步複製架構以 active-active 模式運行,每台伺服器隨時可作為故障轉移目標。
MySQL Cluster(NDB Cluster)#
NDB Cluster 提供節點間的同步 active-active 複製——可以寫入任何節點,每一行都有冗餘儲存。
特色功能:
- 非索引資料的磁碟儲存
- 線上擴展(新增資料節點)
- 多執行緒運作
- Push-down joins(自適應查詢定位)
- 透過 NDB API 和 memcached 協定提供 NoSQL 存取
- 未來版本支援跨 WAN 的最終一致性模式
管理工具: Oracle 的 MySQL Cluster Manager、Severalnines 的 Cluster Control
Percona XtraDB Cluster(基於 Galera)#
Percona XtraDB Cluster 將同步複製與叢集功能加入 XtraDB(InnoDB)儲存引擎本身,而非透過新的儲存引擎或外部伺服器。基於 Galera 函式庫,使用 write-set replication 技術。
運作原理:
- Write sets 以 row-based binary log events 編碼,在節點間傳輸
- 變更在交易提交時序列化並傳輸到各節點,經過 certification 程序
- 若有衝突更新,某方必須回滾(樂觀並行控制)
- 使用
auto_increment_offset和auto_increment_increment避免 ID 衝突
sequenceDiagram
participant A as Node A
participant B as Node B
participant C as Node C
A->>A: 執行交易
A->>B: 傳送 Write Set
A->>C: 傳送 Write Set
B->>B: Certification 檢查
C->>C: Certification 檢查
alt 無衝突
B->>B: Apply Write Set
C->>C: Apply Write Set
B-->>A: 確認
else 有衝突
B-->>A: 衝突,Rollback
end| 面向 | 優點 | 缺點 |
|---|---|---|
| 技術基礎 | 基於 InnoDB 的透明叢集,不需遷移到 NDB 等不同技術 | — |
| 可用性 | 真正的高可用——所有節點平等,隨時可讀寫 | — |
| 資料安全 | 節點故障時零資料遺失(每個節點都有全部資料) | — |
| 複製延遲 | 從庫不會落後(write set 在交易提交前已傳播並認證) | — |
| 複製速度 | 跨節點複製可能比不叢集更快(寫入遠端 RAM 比寫入本地磁碟快) | — |
| 平行複製 | 支援平行(多執行緒)row-level 複製 | — |
| 寫入效能 | — | 整個叢集的寫入速度受限於最慢的節點 |
| 空間效率 | — | 低於 NDB(每個節點存全部資料) |
| Schema 變更 | — | 當時不支援某些操作技巧(如離線在從庫做 schema 變更後升為主庫) |
| 擴展性 | — | 新增節點需要完整資料複製,大叢集可能難以擴展(悲觀估計 ~100GB 上限) |
| 網路敏感度 | — | 複製協定對網路抖動敏感,可能導致節點脫離叢集 |
| 叢集規模 | — | 需要注意叢集不能大到無法重啟故障節點 |
Percona XtraDB Cluster 需要至少三個節點才能實現高可用。在兩節點叢集中,若一個節點故障,剩餘節點不構成 quorum,叢集將停止運作。
基於複製的冗餘#
複製管理器嘗試使用標準 MySQL 複製作為冗餘的建構元件,但存在一個玻璃天花板——非同步和半同步複製無法達到真正同步複製的效果:
- 無法保證即時故障轉移和零資料遺失
- 無法將所有節點視為等價
MMM(MySQL Master-Master Replication Manager):
- 作者不推薦在自動故障轉移模式下使用
- 已知問題:可能將正常伺服器下線、將寫入導向錯誤位置、將從庫移到錯誤座標
MHA(MySQL Master High Availability):
- 由 Yoshinori Matsunobu 開發
- 比 MMM 更謹慎,不嘗試做太多事
- 依賴 Pacemaker 移動虛擬 IP
- 有測試套件,可預防 MMM 遇到的部分問題
自行開發複製管理器是非常糟糕的主意。從非同步元件中引導出正確行為,面對你從未親身經歷過的大量故障模式,充滿了遺失資料的機會。機器可能將原本人類可修復的狀況變得更糟。
故障轉移與故障恢復#
冗餘本身不會提升可用性——高可用是建立在冗餘之上,透過故障轉移(failover)的過程實現的。
術語說明:
- Failover:當元件故障時,切換到冗餘備用元件
- Failback:故障修復後,切換回原始元件
- Switchover:計畫性的切換(非故障回應)
作者偏好對稱的複製拓撲(如 dual-master),不喜歡三個或更多 co-master 的環形複製。對稱拓撲下,failover 和 failback 是同一操作的反方向。
提升從庫或切換角色#
- 將從庫升為主庫是許多 MySQL 故障轉移策略的重要部分
- 被動從庫可能未針對讀取工作負載暖機——若要從庫隨時可接手讀取流量,需持續「訓練」它
- 可透過嗅探 TCP 流量、過濾出 SELECT 查詢並在從庫重播來暖機
虛擬 IP 位址(VIP)/ IP 接管#
將邏輯 IP 位址指派給執行特定服務的 MySQL 實例,故障時將 IP 移到另一台伺服器。
優點: 對應用程式透明,不需修改設定,有時可原子性移動(所有應用程式同時看到變更)
缺點:
| 限制 | 說明 |
|---|---|
| 網路區段限制 | 所有 IP 必須在同一網路區段,或使用 network bridging |
| 權限需求 | 變更 IP 需要 root 權限 |
| ARP 快取 | 快取可能延遲更新 |
| 硬體需求 | 需要網路硬體支援快速 IP 接管 |
| Fencing 需求 | 可能需要 STONITH(Shoot The Other Node In The Head)/ fencing 來確保故障節點不再持有 IP |
sequenceDiagram
participant VM as VIP Manager
participant P as Primary Server
participant S as Standby Server
Note over P: 發生故障
VM->>P: 偵測到故障
VM->>P: 執行 STONITH/Fencing
VM->>P: 移除 VIP
VM->>S: 指派 VIP
VM->>VM: 發送 ARP 更新
S->>S: 開始接受請求中間層方案(Middleman Solutions)#
使用 proxy、port forwarding、NAT 或硬體負載均衡器進行故障轉移。作為中央權威控制應用程式與資料庫的連線,避免了其他方案中「系統各元件是否真的同意哪個是主資料庫」的不確定性。
透過中間層,可以讓遠端資料中心看起來像在應用程式的同一網路上。每個資料中心的應用程式伺服器透過各自的 middleman 連線,middleman 將流量路由到活躍資料中心的機器。若活躍資料中心的 MySQL 完全故障,middleman 可將流量路由到另一個資料中心,應用程式完全不需感知。
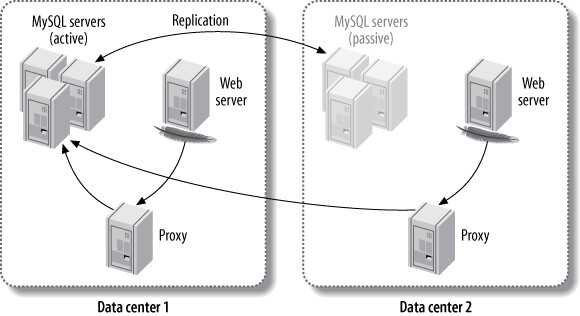
Figure 12.1: Using a middleman to route MySQL connections across data centers
缺點:
- 跨資料中心的高延遲——可透過 web server 的 redirect 模式或 HTTP proxy 緩解
- 中間層本身是單點故障,需要做冗餘
在應用程式中處理故障轉移#
讓應用程式自行處理故障轉移看似有彈性,但隨著應用程式成長(cron jobs、設定檔、不同語言的腳本),會變得難以管理。
建議做法:
- 在應用程式中建立監控,讓它在需要時啟動故障轉移流程
- 應用程式應能管理使用者體驗——降級功能並顯示適當訊息
高可用策略選擇指南#
| 需求 | 推薦方案 |
|---|---|
| 極短停機時間 + 強保證 | MySQL Cluster、Percona XtraDB Cluster、Clustrix |
| 較寬鬆的故障轉移 + 成本考量 | 標準 MySQL 複製(謹慎使用自動故障轉移) |
| 不在意故障轉移時間 + 零資料遺失 | 同步複製:DRBD(低成本)、雙 SAN 同步複製(高成本)、或 NDB/XtraDB Cluster |
| 最簡單 + 可接受部分資料遺失 | 非同步或半同步複製 |
本章重點摘要#
- 高可用 = 減少停機時間,從 MTBF(預防故障)和 MTTR(快速恢復)兩個方向著手
- 預防往往被忽視,但投資報酬率很高——系統變更管理、監控、備份驗證是基本功
- 冗餘不等於高可用——冗餘只提供恢復的機會,需要搭配故障轉移機制才能真正降低停機
- 冗餘使系統變得複雜:分散式系統帶來協調、同步、CAP 定理等挑戰
- 複製(replication)是資料複製的唯一途徑,但引入了不一致的可能性
- 分片(sharding)可減少資料複製次數,降低資源消耗與一致性維護的開銷
- 人員、流程與技術同等重要——不要只依賴工具和系統