什麼是可擴展性(Scalability)#
可擴展性、高可用性與效能是三個完全不同的概念,不應混為一談:
| 概念 | 定義 |
|---|---|
| 效能(Performance) | 回應時間 |
| 容量(Capacity) | 系統在給定時間內能完成的工作量(在可接受效能下的吞吐量,而非最大吞吐量) |
| 可擴展性(Scalability) | 系統在增加資源時,能否等比例地增加處理能力 |
用高速公路來比喻:效能是車速、容量是車道數乘以最大安全車速、可擴展性是增加更多車和車道後交通是否依然順暢。可擴展性取決於交流道設計、事故頻率等因素,而非引擎馬力。
容量可以從多個維度衡量:
- 資料量:應用程式累積的資料總量,社群網站通常不刪除任何資料
- 使用者數量:使用者增加不僅增加資料量,交易數量也可能不成比例地增長;關聯數量上限為
N*(N-1)/2 - 使用者活躍度:不同使用者的活躍程度差異巨大,新功能可能突然改變負載模式
- 相關資料集大小:社群網站需要對整個關聯群組進行查詢與計算
線性擴展與非線性擴展#
理想的線性擴展意味著伺服器數量加倍,系統容量也加倍。但現實中大多數系統的擴展呈非線性——隨著規模增長,偏離線性越來越明顯,最終到達一個最大吞吐量點,之後再增加資源反而會降低吞吐量。
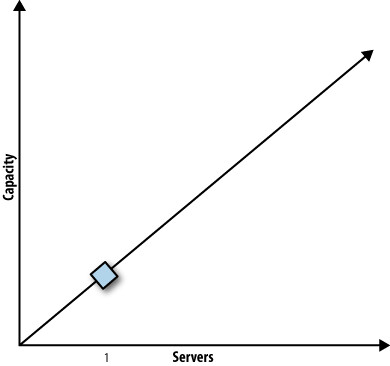
Figure 11.1: A system with one server
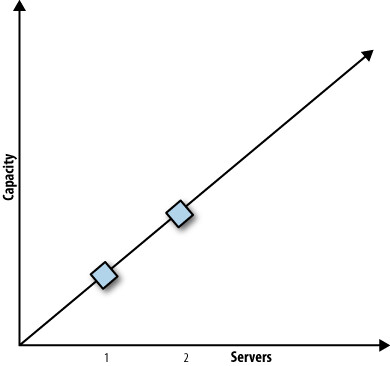
Figure 11.2: A linearly scalable system with two servers has twice the capacity
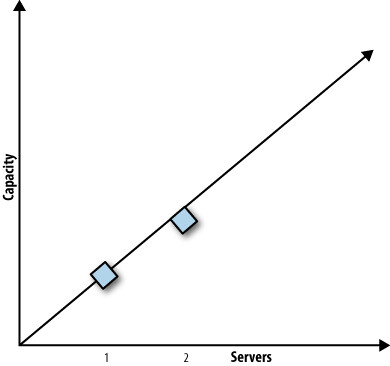
Figure 11.3: A system that doesn't scale linearly
Amdahl’s Law 與 Universal Scalability Law(USL)#
Universal Scalability Law(USL) 是 Dr. Neil J. Gunther 提出的可擴展性模型,將偏離線性擴展的原因歸納為兩個因素:
- 序列化(Serialization):部分工作無法並行化,無論如何分割任務,至少要花序列部分的時間。僅考慮此因素即為 Amdahl’s Law,它導致吞吐量趨於平坦
- 跨節點通訊(Crosstalk):節點間的通訊成本隨通訊通道數量呈二次方增長,最終增長速度超過收益,造成逆行可擴展性(retrograde scalability)——吞吐量反而下降
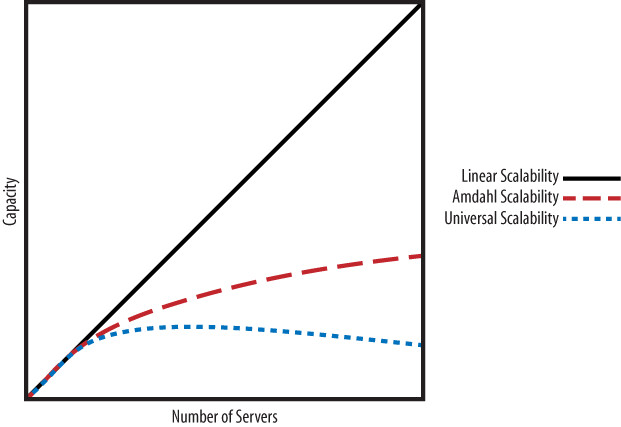
Figure 11.4: Comparison of linear scalability, Amdahl scalability, and the USL
USL 揭示了建構高可擴展系統的核心原則:盡量避免系統內部的序列化與跨節點通訊。
USL 可同時應用於硬體(x 軸為伺服器/CPU 數量)和軟體(x 軸為並行度,如使用者/執行緒數量)。透過量測與迴歸分析,可以估算系統的序列化與跨節點通訊程度,作為容量規劃的參考上下限。
USL 的限制:它無法完美描述所有系統。例如,當叢集的總記憶體大小改變了工作負載的 I/O 特性(從部分 I/O-bound 變為完全 in-memory),可能出現超線性擴展,這是 USL 無法建模的。USL 是有用的簡化模型,但使用時要搭配實際驗證。
擴展 MySQL 的策略#
規劃可擴展性#
效能瓶頸通常表現為:工作負載從 CPU-bound 轉為 I/O-bound、並行查詢之間的競爭加劇、延遲增加。規劃時需考慮:
- 應用程式功能完整度——許多擴展方案會限制某些功能的實現
- 預期的峰值負載——系統在峰值下也必須正常運作
- 部分系統故障時的應對能力——是否有備用容量
爭取時間的短期策略#
在進行大規模架構改造前,可先採取以下措施:
- 優化效能:正確建立索引、從 MyISAM 切換到 InnoDB、分析慢查詢日誌
- 購買更強大的硬體:對早期應用特別有效,從 1 台增加到 3 台的成本遠低於從 100 台增加到 300 台
向上擴展(Scaling Up)#
向上擴展意味著購買更強大的硬體。對許多應用來說,這就夠了:
- 優點:單一伺服器的維護、開發、備份都簡單得多;不存在一致性問題
- 硬體現況:商用伺服器可達 512 GB 記憶體、32+ CPU 核心、PCIe 閃存卡
- 合理的邊際遞減點:大約 256 GB RAM、32 核心、PCIe 閃存
向上擴展的局限性:
- 成本曲線陡升:超過最佳性價比區間後,硬體變得專有且昂貴
- 複製延遲:重度負載的 master 可能產生超過同等硬體 replica 處理能力的工作量
- 單執行緒限制:複雜查詢在 MySQL 中是單執行緒的,再多 CPU 也無法加速
- 雲端環境:公有雲通常無法提供非常強大的伺服器
向外擴展(Scaling Out)#
向外擴展策略分為三大類:複製(Replication)、分區(Partitioning)、分片(Sharding)。
節點(Node) 是架構中的功能單元,可以是:
- Master-Master 複製對(一主動一被動)
- 一個 master 加多個 replica
- 使用 DRBD 的主備伺服器
- SAN-based 叢集
mindmap
root(("向外擴展 Scaling Out"))
Replication
Master-Replica
Master-Master
Functional Partitioning
依功能拆分資料庫
不同表到不同伺服器
Sharding
依 Key 分片
跨 Shard 查詢挑戰功能分區(Functional Partitioning)#
功能分區是將不同節點分配給不同任務。例如一個網站可以將新聞、論壇、客服知識庫等功能區的資料放在各自專用的 MySQL 伺服器上。
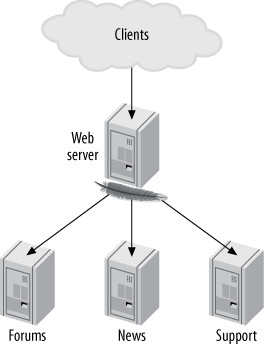
Figure 11.5: A portal and nodes dedicated to functional areas
另一種做法是將單一應用的資料表拆分為永遠不會互相 JOIN 的群組,放到不同節點上。
功能分區的局限性:每個功能區仍然只能垂直擴展。當其中一個功能區增長過大,仍需尋找其他策略。過度分區反而會增加日後遷移到更可擴展架構的難度。
資料分片(Data Sharding)#
資料分片是目前擴展超大型 MySQL 應用最常見且最成功的方法。將資料切分為較小的碎片(shard),分散儲存在不同節點上。
分片通常與功能分區結合使用。大多數分片系統也有一些**全域資料(Global Data)**不做分片(如城市列表、登入資料),通常存放在單一節點並搭配 memcached 等快取。
典型的演進路徑:
- 單一伺服器
- 使用 Replication 擴展讀取
- 功能分區——將 users、posts、comments 拆到不同伺服器
- 分片——依 user ID 分片 posts 和 comments,保留 users 在全域節點
flowchart LR
A["單一伺服器"] -->|"讀取瓶頸"| B["Replication 擴展讀取"]
B -->|"功能成長"| C["功能分區"]
C -->|"資料量超限"| D["Sharding 分片"]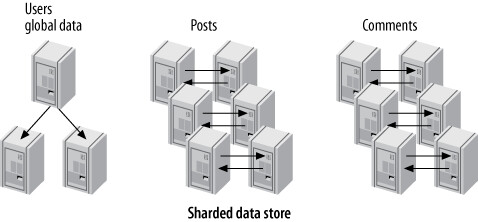
Figure 11.6: From a single instance to a functionally partitioned data store
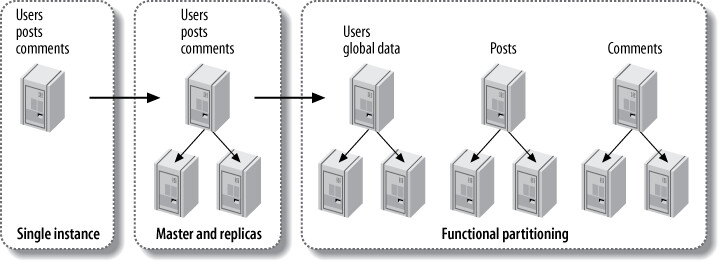
Figure 11.7: A data store with one global node and six master-master nodes
是否該分片? 不要在不需要時做分片。先嘗試效能優化、更好的應用程式設計、購買更大的伺服器。分片在資料量或寫入工作負載超過單一伺服器承受範圍時才是必要的。如果你想擴展寫入容量,就必須分割資料——無論有多少 replica,單一 master 無法擴展寫入。
選擇分區鍵(Partitioning Key)#
分區鍵決定每一行資料應該存放在哪個 shard。核心目標:讓最重要且最頻繁的查詢盡可能只觸及最少的 shard。
- 好的分區鍵通常是資料庫中非常重要的實體的主鍵(如 user_id、client_id)
- 透過 ER 圖視覺化分析資料模型,尋找可以「切斷」的關聯
- 資料模型的連接度決定分片難易度
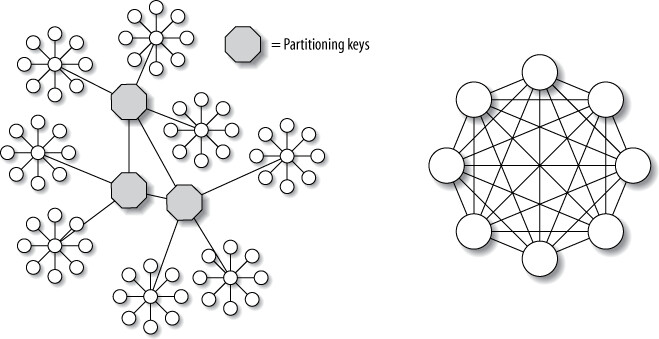
Figure 11.8: Two data models, one easy to shard and the other difficult
左側模型容易分片(有許多低連接度的子圖),右側模型難以分片(高度互連)。
多重分區鍵#
當應用程式需要從不同角度高效查看資料時,可能需要多個分區鍵。例如部落格服務需要依 user ID 查詢使用者的所有文章,也需要依 post ID 查詢一篇文章的所有留言。解法是將部分資料冗餘儲存:完整留言存在 user shard,留言標題和 ID 存在 book shard。
跨分片查詢#
跨分片查詢是分片架構中最困難的部分:
- 需要將查詢拆分為多個子查詢並行執行
- 可以使用 Summary Tables 來加速,將聚合結果冗餘存放在各 shard
- 非分片的全域資料通常搭配大量快取
- 資料一致性維護困難——外鍵無法跨 shard 運作,通常在應用層檢查引用完整性
- 可設計定期清理程式來維護跨 shard 的一致性
分配策略#
固定分配(Fixed Allocation)#
使用只依賴分區鍵值的函數(如 hash、modulus):
-- 使用 CRC32 hash 分配到 100 個 bucket
SELECT CRC32(111) % 100; -- 結果: 81- 優點:簡單、低開銷
- 缺點:難以平衡負載、無法指定資料存放位置、變更 shard 數量需要重新分配所有資料
動態分配(Dynamic Allocation)#
使用對照表儲存分區鍵與 shard 的映射:
CREATE TABLE user_to_shard (
user_id INT NOT NULL,
shard_id INT NOT NULL,
PRIMARY KEY (user_id)
);- 優點:細粒度控制資料存放位置、更容易平衡負載、支援 shard 親和性
- 缺點:需要額外查詢對照表(可用快取緩解)
動態分配搭配 shard 親和性,可以讓跨 shard 查詢不隨規模增長:固定分配在 400 shard 時可能需要查詢全部 400 個,動態分配可能只需查詢 3 個。
顯式分配(Explicit Allocation)#
將 shard 編號直接編碼到 ID 中:
-- 將 shard 11 編碼到 user_id 3 中(使用 BIGINT 的最高 8 位)
-- ID = (11 << 56) + 3 = 792633534417207299
SELECT (792633534417207299 >> 56) AS shard_id,
792633534417207299 & ~(11 << 56) AS user_id;
-- shard_id: 11, user_id: 3優點是每個物件的 ID 自帶分區鍵資訊,不需要額外查詢。
flowchart TD
subgraph Fixed["固定分配"]
F1["分區鍵"] --> F2["Hash / Modulus"]
F2 --> F3["Shard N"]
end
subgraph Dynamic["動態分配"]
D1["分區鍵"] --> D2["查詢對照表"]
D2 --> D3["Shard N"]
end
subgraph Explicit["顯式分配"]
E1["分區鍵"] --> E2["解碼 ID 中的 Shard 編號"]
E2 --> E3["Shard N"]
endShard 的安排與管理#
Shard 大小建議:保持足夠小,使 ALTER TABLE、CHECK TABLE 等維護操作能在 5-10 分鐘內完成。較小的 shard 更容易搬移和重新平衡。
節點上的排列方式:
- 每個 shard 一個資料庫,名稱相同
- 多個 shard 在同一資料庫,表名包含 shard 編號(如
bookclub.comments_23) - 每個 shard 一個資料庫,資料庫名包含 shard 編號(如
bookclub_23.comments) - 資料庫和表名都包含 shard 編號(推薦:
bookclub_23.comments_23)
重新平衡 Shard#
避免搬移個別資料,盡量搬移整個 shard。一個實用的技巧:
- 建立 shard 的兩個 replica
- 讓每個 replica 負責一半的資料
- 停止向 master 發送查詢
- 用
pt-archiver等工具在背景移除各 replica 上不需要的資料
產生全域唯一 ID#
分片環境中 AUTO_INCREMENT 不再適用,替代方案:
| 方案 | 說明 | 注意事項 |
|---|---|---|
auto_increment_increment + auto_increment_offset | 設定不同的起始值和間隔 | 簡單但容易產生重複值 |
| 全域節點的 AUTO_INCREMENT 表 | 集中分配 ID | 全域節點可能成為瓶頸 |
memcached incr() | 利用 memcached 原子遞增 | 快速但非持久化 |
| 批次分配 | 一次取一批號碼 | 需處理未用完的號碼 |
| 組合值 | shard ID + 遞增數字 | 需要設計編碼格式 |
| UUID | 全域唯一 | 不適合 InnoDB 主鍵(大且非循序);MySQL 5.1+ 有 UUID_SHORT() 較佳 |
分片工具#
建議使用資料庫抽象層來隱藏分片細節,可處理:連線路由、分散一致性檢查、跨 shard 聚合/JOIN、鎖與交易管理。
現有工具包括:
| 工具 | 說明 |
|---|---|
| Hibernate Shards | Google 的 Java ORM 分片擴展 |
| HiveDB | Java 分片系統 |
| Shard-Query | PHP,自動拆解查詢並行執行 |
| 商業方案(ScaleBase、ScaleArc、dbShards) | 商用分片解決方案 |
| Sphinx | 全文搜尋引擎,可用於跨 shard 並行查詢 |
透過合併擴展(Scaling by Consolidation)#
MySQL 無法充分利用超大型硬體的全部效能(超過約 24 核心效率開始趨平)。解法是在一台強大的伺服器上執行多個 MySQL 實例,每個實例分配一部分資源。
- 可達 10x-15x 的合併效率
- 比虛擬化的效能損耗更低
- 將每個 MySQL 實例綁定到特定 CPU 核心(同一物理 socket)可減少跨核心同步開銷
- 網路可能成為瓶頸——可使用多 NIC bonding 解決
透過叢集擴展(Scaling by Clustering)#
MySQL Cluster(NDB Cluster)#
NDB 是分散式、容錯、shared-nothing 的資料庫,提供同步複製與自動資料分區。
- 強項:極高的寫入和鍵值查詢吞吐量;全球幾乎每通行動電話都使用 NDB
- 限制:不擅長複雜查詢(大量 JOIN、聚合);沒有 MVCC(讀取會加鎖);無死鎖偵測(靠超時解決)
- 需要快速可靠的網路和大量記憶體
其他 NewSQL 技術#
| 技術 | 說明 |
|---|---|
| Clustrix | 完全分散式 ACID 交易型 SQL 資料庫,支援 MySQL 協議,可線上擴展 |
| ScaleBase | 軟體 proxy,拆分查詢到多個後端 MySQL 執行 |
| GenieDB | 地理分散部署的 NoSQL 文件儲存 + MySQL Storage Engine 層 |
| Akiban | 查詢加速器,透過「table grouping」將關聯表的 tuple 交錯存放 |
向後擴展(Scaling Back)#
歸檔與清除#
設計歸檔策略時的考量:
- 對應用的影響:小批量、高效地找到和刪除行,必要時讓位給交易處理
- 資料一致性:先插入目標再刪除來源,避免資料遺失
- 反歸檔(Unarchiving):設計從歸檔中取回資料的機制,讓你可以更積極地歸檔
Percona Toolkit 的
pt-archiver可以高效地歸檔和清除 MySQL 表。
區分活躍與非活躍資料#
- 分割表:將
users分為active_users和inactive_users,提升 InnoDB buffer pool 的記憶體使用效率(避免每頁 90% 是冷資料) - MySQL 分區表:利用原生分區將最新資料保留在記憶體
- 基於時間的分片:新資料放在高記憶體快速磁碟的「活躍」節點,舊資料放在大容量慢速磁碟的「歸檔」節點
負載平衡(Load Balancing)#
負載平衡的五大目標:
- 可擴展性:支援讀寫分離等擴展策略
- 效率:根據伺服器能力分配請求
- 可用性:自動避開故障伺服器
- 透明性:用戶端只看到單一虛擬伺服器
- 一致性:有狀態的請求導向同一伺服器
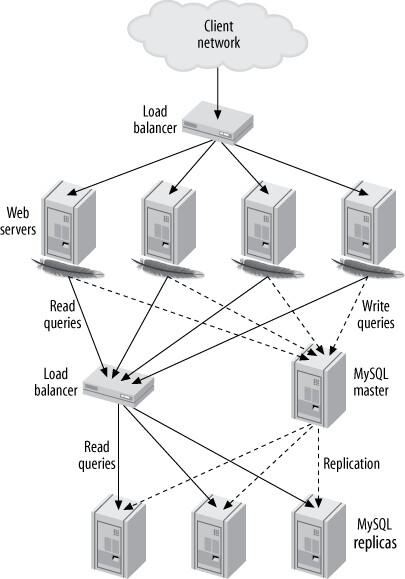
Figure 11.9: Typical load-balancing architecture for a read-intensive website
直接連線方式#
讀寫分離(Read/Write Splitting)#
主要挑戰是處理 replica 上的過期資料。常見策略:
| 策略 | 說明 | 適用場景 |
|---|---|---|
| Query-based | 所有寫入和不容忍過期的讀取 → master,其餘 → replica | 簡單但 replica 使用率低 |
| Stale-data | 檢查 replica 延遲決定是否可讀 | 報表應用 |
| Session-based | 使用者修改資料後一段時間內讀取 → master | 推薦方案,兼顧簡單與效果 |
| Version-based | 追蹤物件版本號,比對 replica 版本決定是否可用 | 需要精確控制 |
| Global version/session | 寫入後記錄 master binlog 位置,比對 replica 位置 | 需要最高精確度 |
SHOW SLAVE STATUS的Seconds_behind_master不是監控複製延遲的可靠方式。建議使用 Percona Toolkit 的pt-heartbeat。
其他直接連線方式#
- 修改應用設定:設定不同機器連線到不同 replica,簡單但脆弱
- DNS 名稱:為讀取和寫入建立不同 DNS 名稱,但 DNS 變更不即時、不完全可控
盡量建構零 DNS 依賴的架構。DNS 快取、傳播延遲、不可預測的 round-robin 行為都是隱患。
- 虛擬 IP 位址:使用 Pacemaker 等工具在伺服器間移動 VIP,透過 ARP 命令快速生效,比 DNS 更可控
中介者方式(Introducing a Middleman)#
中介者(load balancer)接收所有流量,轉發到目標伺服器再將回應路由回來。
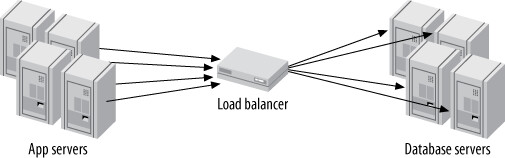
Figure 11.10: A load balancer that acts as a middleman
中介者如果本身不做冗餘,會成為單點故障。
通用負載平衡器用於 MySQL 的限制:
- 無法感知 MySQL 的真實負載(只能平均分配請求,無法區分查詢權重)
- 無法像 HTTP session stickiness 那樣將同一 session 的 MySQL 連線固定到同一伺服器
- 連線池可能干擾負載分配——新加入的伺服器可能閒置
- 健康檢查通常只支援 HTTP——需要在 MySQL 伺服器上安裝自訂 HTTP 腳本,檢查 OS 負載、複製狀態、連線數
負載平衡演算法#
| 演算法 | 說明 | 注意事項 |
|---|---|---|
| Random | 隨機選擇 | |
| Round-robin | 輪流 A, B, C, A, B, C… | |
| Fewest connections | 分配給連線數最少的伺服器 | 可能淹沒新加入的冷快取伺服器 |
| Fastest response | 分配給回應最快的伺服器 | SQL 查詢複雜度差異大時效果不穩定 |
| Hashed | 依來源 IP hash 固定映射到伺服器 | 伺服器數量變化時才重新映射 |
| Weighted | 結合其他演算法並加權 | 適用於異質硬體環境 |
伺服器池管理#
- 加入新伺服器:不能直接加入,應先用流量重放(
pt-query-digest)或 Percona Server/MySQL 5.6 的快速暖機功能預熱快取 - 容量規劃:
max_connections應設為日常使用量的 2 倍,以應對半數伺服器故障的情況 - 佇列機制:某些連線池支援限制並行交易數,排隊等待可用伺服器
Master 搭配多 Replica 的負載平衡#
- 功能分區:設定特定 replica 群組處理報表、資料倉儲、全文搜尋等
- 資料過濾:使用複製過濾器在不同 replica 間分割資料
- 讀取分區:即使不分割資料,也可以按使用者名稱 A-M / N-Z 分配到不同 replica,提升快取命中率
- 寫入部分卸載:將寫入查詢的部分工作分解到 replica 執行
- 同步保證:使用
MASTER_POS_WAIT()確保 replica 追上特定位置後再讀取
本章總結#
- 正確的擴展策略不是從第一天就建構 Facebook 架構,而是做當前需要的事,並提前規劃
- 典型的成長路徑:單一伺服器 → 讀取 replica 的向外擴展 → 分片和/或功能分區
- 不贊成「早分片、常分片」——分片複雜且昂貴,許多應用永遠不需要
- 多伺服器環境中最常見的問題:Session 一致性(發表留言後看不到)和讀寫路由錯誤(向多處寫入會造成極難修復的資料問題)
- 負載平衡器可以幫忙,但也可能製造新問題或加劇既有問題